声明:笔者的该篇博客核心内容借鉴了多位大牛的分享,出发点源于知识的分享以及督促学习,若有作者需特别标注请私信或留言。力争用“土到掉渣的语言(通俗易懂的语言)”与大家分享,因水平有限,欢迎大牛批评指正!
背景知识
Transfer Learning(TL)和Deep Learning(DL)是当下较为热门的领域,简单可以理解为:DL是当下,TL是未来。
VGG 是视觉领域竞赛 ILSVRC 在 2014 年获胜模型,VGG16 基本上继承了 AlexNet 深的思想,AlexNet 只用到了 8 层网络,而 VGG 的两个版本分别是 16 层网络版和 19 层网络版。在接下来的迁移学习实践中,我们会采用稍微简单的一些的 VGG16,他和 VGG19 有几乎完全一样的准确度,但是运算起来更快。
喜碧理解:
DL解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。TL作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
简单来说,DL重在获取知识;TL重在利用数据、任务、或模型之间的相似性,将已获取的知识应用于其他领域。
“土到掉渣”的语言就是,TL是举一反三,一通百通。相对应的,DL就是学会那个“一”。只不过TL的核心是相似性,否则会东施效颦。
举个例子,TL就是乾坤大挪移,将其他攻击者使用的招式(DL学习的知识,粗略可以理解为模型)转移并加上自己的内功(结合自身特点,微调参数或网络层)再打出去(应用于其他领域)。其优点就是用最低的成本(时间短,数据集不多的情况),获取不错的效果。因为要学会神功(好的模型),需要资质(硬件支持)和机遇(算法设计),再加上夜以继日的练习(大量的数据集)才能出山。作为老百姓,我们只需在相似性的基础上利用TL,就能在一朝一夕(微调参数或网络层)习得看家本领(自己的模型)。
(一不小心聊多了,希望能帮助大家理解,背景知识一般大佬都直接跳过,这里就很心机的放在最后啦。)
VGG16
进入正题,首先我们看看VGG模型长啥样。

VGG 的输入数据格式是 244 * 224 * 3 的像素数据,经过一系列的卷积神经网络和池化网络处理之后,输出的是一个 4096 维的特征数据,然后再通过 3 层全连接的神经网络处理,最终由 softmax 规范化得到分类结果。
喜碧理解:
VGG的输入参数为图片(如:输入.jpg图片经过处理可以转换为所需像素数据),经过计算,输出特征值,再经过计算,输出预测分布(粗略理解为每种预测结果的概率),经过处理,输出预测结果。(如下图所示)

我们可以看出输出了一个ndarray,这里预测的种类一共为五种,所以ndarray有五列。可以看到第一列的值是最大的,所以预测的种类应该是第一种。

我们可以看到一个十五列的ndarray,因为我们一共对十五个测试数据进行了预测。对照上面的预测分布,因为在第一个测试数据预测分布中,第一列的值最大,所以预测种类应该是第一种即预测结果输出为0(因为所以是从0开始的)。
数据集
数据集放到flower_photos文件夹下,创建了五个子文件夹,里面分别存放对应种类花卉的.jpg图片。

这里插播一条各个文件夹存放路径。

导入Python模块
import os
import numpy as np
import tensorflow as tf
#注意,存放vgg16和utils文件夹名最好使用全英文。
from tensorflowvgg import vgg16
from tensorflowvgg import utils
加载数据集
将flower_photos文件夹中的子文件夹作为标签值,各个子文件夹里面的.jpg图片加载。
#data_dir :数据集所在文件夹名
data_dir = 'flower_photos/'
#contents :文件夹里子文件名集合
contents = os.listdir(data_dir)
#classes :文件夹里子文件夹名集合
classes = [each for each in contents if os.path.isdir(data_dir + each)]

利用 VGG16 计算特征值
一顿操作主要是得到标签值labels和对应的特征值codes。
# 首先设置计算batch的值,如果运算平台的内存越大,这个值可以设置得越高
batch_size = 10
# 用codes_list来存储特征值
codes_list = []
# 用labels来存储花的类别
labels = []
# batch数组用来临时存储图片数据
batch = []
#codes存放所有数据集特征值
codes = None
with tf.Session() as sess:
# 构建VGG16模型对象
vgg = vgg16.Vgg16()
#input_ 可粗略理解为声明一个有具体要求的变量
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
#tf.name_scope可管理变量名,类似于在前面加前缀
with tf.name_scope("content_vgg"):
# 载入VGG16模型
vgg.build(input_)
# 对每个不同种类的花分别用VGG16计算特征值
for each in classes:
print("Starting {} images".format(each))
#class_path 为各个种类文件夹名
class_path = data_dir + each
#files为各个种类文件夹里的.jpg图片名
files = os.listdir(class_path)
for ii, file in enumerate(files, 1):
# 载入图片并放入batch数组中
img = utils.load_image(os.path.join(class_path, file))
batch.append(img.reshape((1, 224, 224, 3)))
labels.append(each)
# 如果图片数量到了batch_size则开始具体的运算
if ii % batch_size == 0 or ii == len(files):
images = np.concatenate(batch)
feed_dict = {input_: images}
# 计算特征值
codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict)
# 将结果放入到codes数组中
if codes is None:
codes = codes_batch
else:
codes = np.concatenate((codes, codes_batch))
# 清空数组准备下一个batch的计算
batch = []
print('{} images processed'.format(ii))
因为计算特征值的过程较为费时,所以可以把来之不易的标签值和对应的特征值保存下来,下次直接载入使用即可。
#该保存方法适用于保存ndarray
with open('codes', 'w') as f:
codes.tofile(f)
#该保存方法适用于保存list
import csv
with open('labels', 'w') as f:
writer = csv.writer(f, delimiter='\n')
writer.writerow(labels)
#该加载方法适用于加载ndarray
with open("codes",'rb') as fid:
codes = np.fromfile(fid,dtype=np.float32)
codes.shape = 3670, 4096
#该加载方法适用于加载list
with open("labels") as csvfile:
reader = csv.reader(csvfile)
labels=list(reader)
当保存完特征值和标签值后可以观察Project Files目录,可以synchronize(同步)。在按钮可以通过View->ToolBar找到。


如果还是不能顺利同步,可以尝试Settings->Excluded,通过切换Excluded的状态尝试。


分配训练集、验证集、测试集
首先我们把 labels 数组中的分类标签用 One Hot Encode 的方式替换。
简单说就是把五个类别的名字对应换成如下形式:
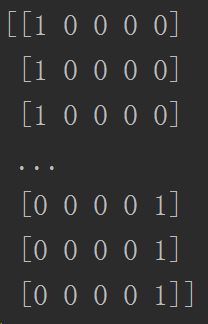

from sklearn.preprocessing import LabelBinarizer
lb = LabelBinarizer()
lb.fit(labels)
#labels_vecs 就是标签值转换后对应的One Hot Encode
labels_vecs = lb.transform(labels)
用 StratifiedShuffleSplit 方法来进行分层随机划分。假设我们使用训练集:验证集:测试集 = 8:1:1,代码如下:
from sklearn.model_selection import StratifiedShuffleSplit
#test_size这里是测试集加验证集所占的比例,1-test_size即为训练集所占比例。
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
#从0到train_idx,从0到val_idx 即为训练集,这里是通过索引来划分。
train_idx, val_idx = next(ss.split(codes, labels))
#划分验证集和测试集
half_val_len = int(len(val_idx)/2)
val_idx, test_idx = val_idx[:half_val_len], val_idx[half_val_len:]
train_x, train_y = codes[train_idx], labels_vecs[train_idx]
val_x, val_y = codes[val_idx], labels_vecs[val_idx]
test_x, test_y = codes[test_idx], labels_vecs[test_idx]
print("Train shapes (x, y):", train_x.shape, train_y.shape)
print("Validation shapes (x, y):", val_x.shape, val_y.shape)
print("Test shapes (x, y):", test_x.shape, test_y.shape)
运行后的结果:
Train shapes (x, y): (2936, 4096) (2936, 5)
Validation shapes (x, y): (367, 4096) (367, 5)
Test shapes (x, y): (367, 4096) (367, 5)
这里2936,367代表的是对应数据集样本数量,4096是特征值所要求的维数,5是种类决定的维数。
在加载保存好的数据时,一定要注意其类型和维度是否满足需求。类型可以通过加载函数里面的dtype参数来控制,维度可以通过shape属性来控制。
训练网络
假设我们使用一个 256 维的全连接层,一个 5 维的全连接层(因为我们要分类五种不同类的花朵),和一个 softmax 层。当然,这里的网络结构可以任意修改,你可以不断尝试其他的结构以找到合适的结构。
# 输入数据的维度
inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]])
# 标签数据的维度
labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]])
# 加入一个256维的全连接的层
fc = tf.contrib.layers.fully_connected(inputs_, 256)
# 加入一个5维的全连接层
logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None)
# 计算cross entropy值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits)
# 计算损失函数
cost = tf.reduce_mean(cross_entropy)
# 采用用得最广泛的AdamOptimizer优化器
optimizer = tf.train.AdamOptimizer().minimize(cost)
# 得到最后的预测分布
predicted = tf.nn.softmax(logits)
# 计算准确度
#tf.argmax(predicted, 1)和tf.argmax(labels_, 1)分别为预测的结果和样本标记的结果。
correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
为了方便把数据分成一个个 batch 以降低内存的使用,还可以再用一个函数专门用来生成 batch。
def get_batches(x, y, n_batches=10):
""" 这是一个生成器函数,按照n_batches的大小将数据划分了小块 """
batch_size = len(x)//n_batches
for ii in range(0, n_batches*batch_size, batch_size):
# 如果不是最后一个batch,那么这个batch中应该有batch_size个数据
if ii != (n_batches-1)*batch_size:
X, Y = x[ii: ii+batch_size], y[ii: ii+batch_size]
# 否则的话,那剩余的不够batch_size的数据都凑入到一个batch中
else:
X, Y = x[ii:], y[ii:]
# 生成器语法,返回X和Y
yield X, Y
开始训练:
# 运行多少轮次
epochs = 20
# 统计训练效果的频率
iteration = 0
# 保存模型的保存器
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for x, y in get_batches(train_x, train_y):
feed = {inputs_: x,
labels_: y}
# 训练模型
loss, _ = sess.run([cost, optimizer], feed_dict=feed)
print("Epoch: {}/{}".format(e+1, epochs),
"Iteration: {}".format(iteration),
"Training loss: {:.5f}".format(loss))
iteration += 1
if iteration % 5 == 0:
feed = {inputs_: val_x,
labels_: val_y}
val_acc = sess.run(accuracy, feed_dict=feed)
# 输出用验证机验证训练进度
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Validation Acc: {:.4f}".format(val_acc))
# 保存模型
saver.save(sess, "checkpoints/flowers.ckpt")
测试网络
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))
feed = {inputs_: test_x,
labels_: test_y}
test_acc = sess.run(accuracy, feed_dict=feed)
print("Test accuracy: {:.4f}".format(test_acc))
补充:因为tf.argmax(predicted, 1)和tf.argmax(labels_, 1)是tensor类型,若要输出其值需要如下处理:
test_label2 = sess.run(tf.argmax(predicted, 1), feed_dict=feed2)
print(test_label2)
print("=========")
test_label3 = sess.run(tf.argmax(labels_, 1), feed_dict=feed)
print(test_label3)
处理后能看到输出值,通过将其值里的元素逐个比较可以看到预测值与标签值对比:
for index in range(len(test_label2)):
if test_label2[index]==test_label3[index]:
print("true")
else:
print("false")
并不是epochs越多越好,这里给大家附上几个测试结果对比图。

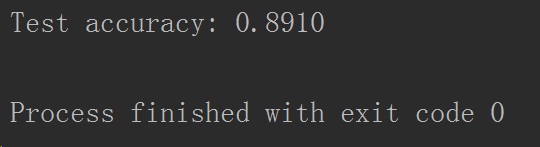

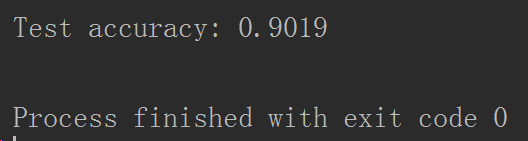
补充:为了提高效率,将VGG16分为三个部分,分别是特征值计算、训练网络、预测。
#!/usr/bin/python
# -*- coding:utf8 -*-
import os
import numpy as np
import tensorflow as tf
import csv
from tensorflowvgg import vgg16
from tensorflowvgg import utils
data_dir = 'L:/pics/'
contents = os.listdir(data_dir)
classes = [each for each in contents if os.path.isdir(data_dir + each)]
# 首先设置计算batch的值,如果运算平台的内存越大,这个值可以设置得越高
batch_size = 10
# 用codes_list来存储特征值
codes_list = []
# 用labels来存储花的类别
labels = []
# batch数组用来临时存储图片数据
batch = []
codes = None
with tf.Session() as sess:
# 构建VGG16模型对象
vgg = vgg16.Vgg16()
input_ = tf.placeholder(tf.float32, [None, 224, 224, 3])
with tf.name_scope("content_vgg"):
# 载入VGG16模型
vgg.build(input_)
# 对每个不同种类的花分别用VGG16计算特征值
for each in classes:
print("Starting {} images".format(each))
class_path = data_dir + each
files = os.listdir(class_path)
for ii, file in enumerate(files, 1):
# 载入图片并放入batch数组中
try:
print("0000000000")
img = utils.load_image(os.path.join(class_path, file))
print("1111111111")
batch.append(img.reshape((1, 224, 224, 3)))
print("22222222222")
labels.append(each)
print("3333333333")
except:
print("NoPic!")
continue
# 如果图片数量到了batch_size则开始具体的运算
if ii % batch_size == 0 or ii == len(files):
images = np.concatenate(batch)
feed_dict = {input_: images}
# 计算特征值
codes_batch = sess.run(vgg.relu6, feed_dict=feed_dict)
# 将结果放入到codes数组中
if codes is None:
codes = codes_batch
else:
codes = np.concatenate((codes, codes_batch))
# 清空数组准备下一个batch的计算
batch = []
print('{} images processed'.format(ii))
# print(codes)
with open('MushroomCodes', 'w') as f:
codes.tofile(f)
with open('MushroomLabels', 'w') as f:
writer = csv.writer(f, delimiter='\n')
writer.writerow(labels)
import os
import numpy as np
import tensorflow as tf
import csv
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import StratifiedShuffleSplit
from tensorflowvgg import vgg16
from tensorflowvgg import utils
# with open("train_x",'rb') as fid:
# train_x = np.fromfile(fid,dtype=np.float32)
# train_x.shape=2936,4096
#
# with open("train_y",'rb') as fid:
# train_y = np.fromfile(fid,dtype=np.int32)
# train_y.shape=2936,5
#
# with open("val_x",'rb') as fid:
# val_x = np.fromfile(fid,dtype=np.float32)
# val_x.shape=367,4096
#
# with open("val_y",'rb') as fid:
# val_y = np.fromfile(fid,dtype=np.int32)
# val_y.shape=367,5
with open("MushroomCodes",'rb') as fid:
codes = np.fromfile(fid,dtype=np.float32)
codes.shape = 458, 4096
with open("MushroomLabels") as csvfile:
reader = csv.reader(csvfile)
labels=list(reader)
labels = str(labels)
labels = labels.replace('[', '')
labels = labels.replace(']', '')
# 最后转化成列表
labels = list(eval(labels))
# print(labels)
lb = LabelBinarizer()
lb.fit(labels)
labels_vecs = lb.transform(labels)
print(labels_vecs)
ss = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
# codes=codes[:,:]
# print(codes.shape)
# print(labels.shape)
train_idx, val_idx = next(ss.split(codes, labels))
# print(codes.shape)
# print(labels)
labels = np.array(labels)
# print(labels.shape)
half_val_len = int(len(val_idx) / 2)
val_idx, test_idx = val_idx[:half_val_len], val_idx[half_val_len:]
train_x, train_y = codes[train_idx], labels_vecs[train_idx]
val_x, val_y = codes[val_idx], labels_vecs[val_idx]
test_x, test_y = codes[test_idx], labels_vecs[test_idx]
print("Train shapes (x, y):", train_x.shape, train_y.shape)
print("Validation shapes (x, y):", val_x.shape, val_y.shape)
print("Test shapes (x, y):", test_x.shape, test_y.shape)
with open('MushroomTest_x', 'w') as f:
test_x.tofile(f)
with open('MushroomTtest_y', 'w') as f:
test_y.tofile(f)
# 输入数据的维度
inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]])
# 标签数据的维度
labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]])
# 加入一个256维的全连接的层
fc = tf.contrib.layers.fully_connected(inputs_, 256)
# 加入一个5维的全连接层
logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None)
# 计算cross entropy值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits)
# 计算损失函数
cost = tf.reduce_mean(cross_entropy)
# 采用用得最广泛的AdamOptimizer优化器
optimizer = tf.train.AdamOptimizer().minimize(cost)
# 得到最后的预测分布
predicted = tf.nn.softmax(logits)
# 计算准确度
correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
def get_batches(x, y, n_batches=10):
""" 这是一个生成器函数,按照n_batches的大小将数据划分了小块 """
batch_size = len(x) // n_batches
for ii in range(0, n_batches * batch_size, batch_size):
# 如果不是最后一个batch,那么这个batch中应该有batch_size个数据
if ii != (n_batches - 1) * batch_size:
X, Y = x[ii: ii + batch_size], y[ii: ii + batch_size]
# 否则的话,那剩余的不够batch_size的数据都凑入到一个batch中
else:
X, Y = x[ii:], y[ii:]
# 生成器语法,返回X和Y
yield X, Y
# 运行多少轮次
epochs = 5
# 统计训练效果的频率
iteration = 0
# 保存模型的保存器
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for e in range(epochs):
for x, y in get_batches(train_x, train_y):
feed = {inputs_: x,
labels_: y}
# 训练模型
loss, _ = sess.run([cost, optimizer], feed_dict=feed)
print("Epoch: {}/{}".format(e + 1, epochs),
"Iteration: {}".format(iteration),
"Training loss: {:.5f}".format(loss))
iteration += 1
if iteration % 5 == 0:
feed = {inputs_: val_x,
labels_: val_y}
val_acc = sess.run(accuracy, feed_dict=feed)
# 输出用验证机验证训练进度
print("Epoch: {}/{}".format(e, epochs),
"Iteration: {}".format(iteration),
"Validation Acc: {:.4f}".format(val_acc))
# 保存模型
saver.save(sess, "MushroomCheckpoints/illness.ckpt")
import os
import numpy as np
import tensorflow as tf
import csv
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import StratifiedShuffleSplit
from tensorflowvgg import vgg16
from tensorflowvgg import utils
with open("MushroomTest_x",'rb') as fid:
test_x = np.fromfile(fid,dtype=np.float32)
test_x.shape=46,4096
# print(myCodes)
with open("MushroomTtest_y",'rb') as fid:
test_y = np.fromfile(fid,dtype=np.int32)
test_y.shape= 46,3
# print(myLabels)
# with open("myCodes",'rb') as fid:
# myCodes = np.fromfile(fid,dtype=np.float32)
# myCodes.shape=1,4096
# # print(myCodes)
#
# with open("myLabels",'rb') as fid:
# myLabels = np.fromfile(fid,dtype=np.int32)
# myLabels.shape=1,5
# # print(myLabels)
#
# with open("test_x",'rb') as fid:
# test_x = np.fromfile(fid,dtype=np.float32)
# test_x.shape=367,4096
# # print(test_xx.shape)
#
# with open("test_y",'rb') as fid:
# test_y = np.fromfile(fid,dtype=np.int32)
# test_y.shape=367,5
# # print(test_yy.shape)
#
#
# with open("train_x",'rb') as fid:
# train_x = np.fromfile(fid,dtype=np.float32)
# train_x.shape=2936,4096
#
# with open("train_y",'rb') as fid:
# train_y = np.fromfile(fid,dtype=np.int32)
# train_y.shape=2936,5
#
#
with open("MushroomCodes",'rb') as fid:
codes = np.fromfile(fid,dtype=np.float32)
codes.shape = 458, 4096
with open("MushroomLabels") as csvfile:
reader = csv.reader(csvfile)
labels=list(reader)
labels = str(labels)
labels = labels.replace('[', '')
labels = labels.replace(']', '')
# 最后转化成列表
labels = list(eval(labels))
lb = LabelBinarizer()
lb.fit(labels)
labels_vecs = lb.transform(labels)
# 输入数据的维度
inputs_ = tf.placeholder(tf.float32, shape=[None, codes.shape[1]])
# 标签数据的维度
labels_ = tf.placeholder(tf.int64, shape=[None, labels_vecs.shape[1]])
# 加入一个256维的全连接的层
fc = tf.contrib.layers.fully_connected(inputs_, 256)
# 加入一个5维的全连接层
logits = tf.contrib.layers.fully_connected(fc, labels_vecs.shape[1], activation_fn=None)
# 计算cross entropy值
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=labels_, logits=logits)
# 计算损失函数
cost = tf.reduce_mean(cross_entropy)
# 采用用得最广泛的AdamOptimizer优化器
optimizer = tf.train.AdamOptimizer().minimize(cost)
# 得到最后的预测分布
predicted = tf.nn.softmax(logits)
# 计算准确度
correct_pred = tf.equal(tf.argmax(predicted, 1), tf.argmax(labels_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, tf.train.latest_checkpoint('MushroomCheckpoints'))
feed = {inputs_: test_x,
labels_: test_y}
test_acc = sess.run(accuracy, feed_dict=feed)
print("Test accuracy: {:.4f}".format(test_acc))
print(test_x.shape)
feed2 = {inputs_: test_x
}
test_label = sess.run(predicted, feed_dict=feed2)
print(test_label.shape)
print("=========")
test_label2 = sess.run(tf.argmax(predicted, 1), feed_dict=feed2)
print(test_label2)
print("=========")
test_label3 = sess.run(tf.argmax(labels_, 1), feed_dict=feed)
print(test_label3)
# for index in range(len(test_label2)):
# if test_label2[index]==1:
# print("sun")
# else:
# print("false")
# if(test_label2==3):
# print("sun")
# if(test_label2==2):
# print("nosun")
# print(myLabels2)
# test_label3 = sess.run(tf.argmax(labels_, 1), feed_dict=feed)
# print(test_label3.dtype)
# print(tf.argmax(test_label, 1))
# print(predicted,feed_dict=feed)
# print(labels_)
# print("===============")
# print(predicted)
# with tf.Session():
# print(predicted.eval(),feed_dict=feed)
# print("Test accuracy: {:.4f}".format(test_acc))
