一、Requests入门
(一)Requests库的安装
- 安装Requests库:“以管理员身份运行”cmd,执行 pip install requests
- pip 是一个现代的,通用的 Python包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能。
- Requests 库安装小测:status_code为200表示返回成功
>>> import requests >>> r =requests.get("http://www.baidu.com") >>> print(r.status_code) 200
要注意斜杠是正斜杠还是反斜杠,网页上文件路径一般用正斜杠 \,本地一般路径用 反斜杠
(二)Requests库的7个主要方法
requests.request() 构造一个请求,支撑以下各方法的基础方法
requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE
Requests.get() 构造一个向服务器请求资源的Request对象,返回一个包含服务器资源的Response对象
requests.get(url, params=None, **kwargs)
∙ url : 拟获取页面的url链接
∙ params : url中的额外参数,字典或字节流格式,可选
∙ **kwargs: 12个控制访问的参数
(三)Response对象的属性
r.status_code HTTP请求的返回状态,200表示连接成功,404表示失败
r.text HTTP响应内容的字符串形式,即,url对应的页面内容
r.encoding 从HTTP header中猜测的响应内容编码方式
.apparent_encoding 从内容中分析出的响应内容编码方式(备选编码方式)
r.content HTTP响应内容的二进制形式
(四)Requests的异常
requests.ConnectionError 网络连接错误异常,如DNS查询失败、拒绝连接等
requests.HTTPError HTTP错误异常
requests.URLRequired URL缺失异常
requests.TooManyRedirects 超过最大重定向次数,产生重定向异常
requests.ConnectTimeout 连接远程服务器超时异常
requests.Timeout 请求URL超时,产生超时异常
可以使用 如下框架
try
r = requests.get(url,timeout=30)
r=raise_for_status()
r.encoding = r.apparent_encoding
return t.text
except:
return "产生异常"(五)实际操作中的具体问题
- 一些网站对网络爬虫进行限制:(1) 来源审查:判断来访的HTTP协议头的User-Agent域进行限制(2)发布公告:Robots协议,要求爬虫遵守(可以忽略,不过不要进行商业牟利,或者大量数据的下载,占用服务器资源),公告于网站根目录下的robots.txt
- encoding中的编码形式可能会不正确,因为它只分析了头部,得出的编码类型,而apparent_encoding是分析了页面得出的编码类型,相对来说,比较准确,所以可以使用r.encoding = r.apparent_encoding语句来改变其译码方式,从而可以调用r.text()获得正确编译完的页面内容
- 实际操作中,获取到的页面内容可能过多,导致调用text()函数时IDLE奔溃,所以可以使用r.text[:1000]来获取前1000个字符,或者使用r.text[:-1000]来获得其最后1000个字符
- 遇到来源审查的网站,使用 r.request.headers["user-agent"]="Mozilla/5.0" 语句将 header中的user-agent改成 Mozilla/5.0(大多数浏览器都Mozilla/5.0字样),或在获取语句中直接使用r = requests .get(url,headers = {'user-agent' : 'Mozilla/5.0'})语句
- 图片的读取:使用get获取图片,URL例:http:XXX//XXX/XXX.jpg, f=open(path,'wb')二进制写打开本地存储路径,f.write(r.content)保存图片
二、 Beautiful Soup库入门
(一)BeautifulSoup库的安装
.命令行执行pip install beautifulsoup4下载安装
(二)bs4库的使用
- 使用 from bs4 import BeautifulSoup导入
- soup =BeautifulSoup(r.text,"html,parser") 该语句表示,将r.text通过bs4的HTML解析器解析成一个标签树的形式
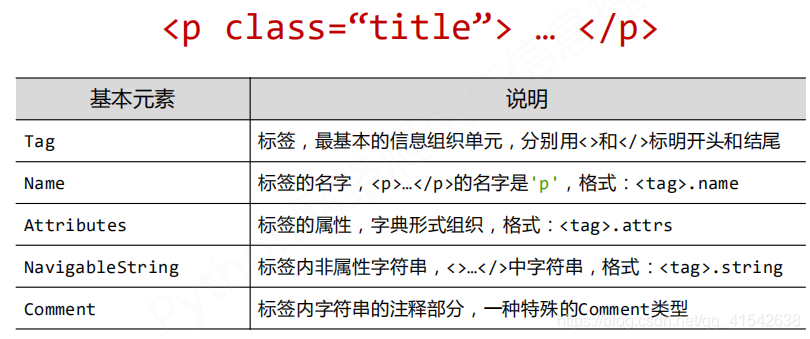
- BeautifulSoup类的基本元素
三、正则表达式入门
(一)正则表达式的使用
- .编译:将符合正则表达式语法的字符串转换成正则表达式特征:实例
regex='p(Y|YT|YTH|YTHO)?N' #正则表达式字符串 p=re.compile(regex) #字符串编译转换成正则表达式特征
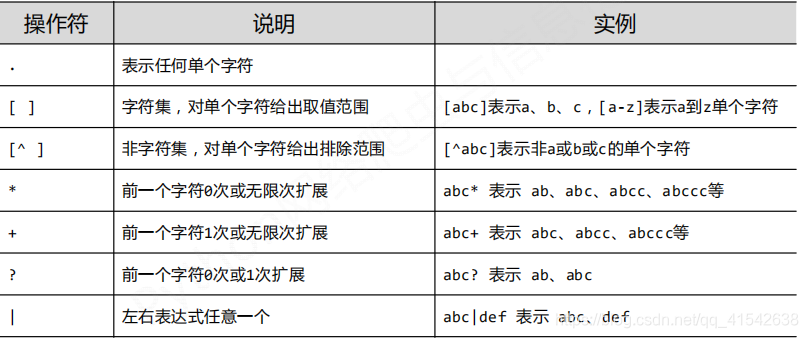
2.正则表达式常用操作符

(二)经典正则表达式


(三)Re库介绍
例如:r'[1-9]\d{5}' ,此时如果不加r' ,则斜杠需要写为两个斜杠 :'[1-9]\\d{5}'


- 概念:Re库是Python的标准库,主要用于字符串匹配
- raw string类型:即原生字符串类型(不包含转义字符转义的字符串),re库采用 raw string 类型时,表示为 r'text',
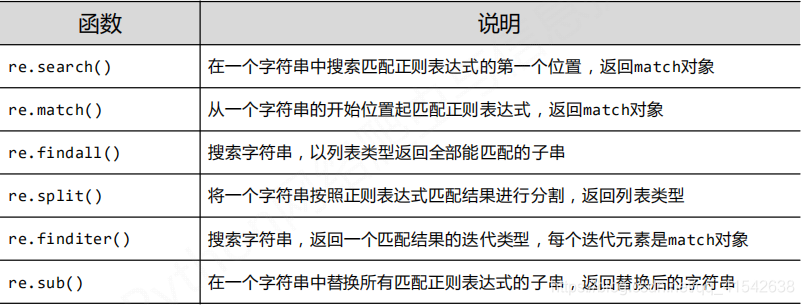
- Re库的主要功能函数: