希尔排序(Shell Sort)
上一章提到过的冒泡排序、简单选择排序和直接插入排序时间复杂度都是O(n^2);希尔排序是第一批突破这个时间复杂度的算法之一。
直接插入排序在某些情况下效率是很高的,比如数据基本有序的情苦下,为什么?如果序列是:{9,1,5,8,7,3,4,6,2};这个序列如果使用直接插入排序的话,由于序列中最大的记录9位于序列的第一位,因此后面的记录都需要插入到9之前(假设为从小到大排序),这样就会造成比较大的时间开销。但是如果序列是{2,1,3,6,4,7,5,8,9}这样基本有序的,时间性能就会好很多。注意基本有序这个概念,不要求序列一定是从小到大排好的,但是需要小的关键字在前面,大的在后面,不大不小的在中间。还有一种情况直接插入排序效率也是比较高的,就是记录数比较少的时候,直接插入排序优势也比较明显。其实记录数比较少的时候排序算法之间的差距也并不明显。
希尔排序是科学家希尔在1959年提出的,采用跳跃分割的策略将待排序的序列分割为若干个子序列,然后对这些子序列进行排序,为什么要采取跳跃分割而不是直接将每几位作为一个子序列的呢?这样是为了使得排序后的序列是基本有序而不是局部有序。
代码如下:
void ShellSort(SqList * L)
{
int i, j;
int increment = L->length;
do
{
increment = increment/3 + 1;
for (i = increment+1; i <= L->length; i++)
{
if (L->r[i] < L->r[i-increment])
{
L->r[0] = L->r[i];
// 下面这个for循环实质上就是一个直接插入排序
for (j = i - increment; j > 0 && L->r[0] < L->r[j]; j -= increment)
{
L->r[j+increment] = L->r[j];
}
L->r[j+increment] = L->r[0];
}
}
}while(increment > 1);
}因为希尔排序的关键是相隔某个“增量”(代码中的increment)的记录组成一个子序列,实现跳跃式移动,所以“增量”的选择就很重要。究竟选择什么样的增量最好,目前还是一个数学难题。但是大量的研究表明当增量序列
dlta[k] = 2^(t-k+1) -1(0 <= k <= t <= [log2(n+1)]) 时,可以取得不错的效果。但是“增量”最后的结果一定要为 1 。时间复杂度为 O(n^(3/2))。另外希尔排序不是一种稳定的排序算法(因为时跳跃式的移动)。
堆排序
堆排序是对简单选择排序的一种改进,简单选择排序的主要优势就是交换数据的次数少(最多n - 1次),但是比较的次数为n(n-1)/2。比较次数中有很多是重复比较的,就是说某两个数之间的比较次数不止一次,最明显的就是最后两个数的比较。
如果可以每次做到在选择到最小记录的同时,根据比较结果对其他记录做出调整,那么效率就很高了。堆排序就是这么做的。
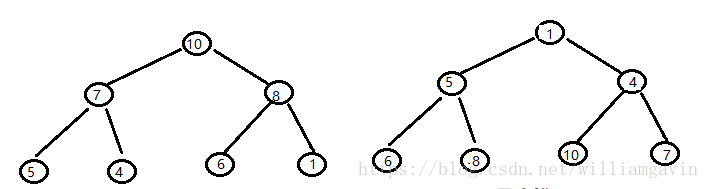
在讲堆排序之前先说什么是“堆”,堆实际上是一棵完全二叉树,这颗完全二叉树每个结点的值都大于或者等于其左右孩子节点的值,称为大顶堆(下图左),或者每个结点的值都小于或者等于其左右孩子结点的值,称为小顶堆(下图右)。
先介绍一个完全二叉树的性质,代码里面用得到。
完全二叉树性质:
- 如果i = 1;则结点 i 是完全二叉树的根,无双亲;如果 i > 1,则其双亲结点 [i/2]。
- 如果 2i > n ,则结点 i 无左孩子(结点 i 为叶子结点);否则其左孩子是结点 2i。
如果 2i + 1 > n;则结点 i 无左右孩子;否则其右孩子是结点 2i + 1。
堆排序的基本思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
基本可分为三步:- 构建大顶堆
- 将根节点与末尾元素进行交换
- 向下调整
代码:
void HeapAdjust(SqList * L, int s, int m)
{
int temp, j;
temp = L->r[s];
for (j = 2*s; j <= m; j *= 2) // 这里的j = 2 * s和 j*=2都是根据前面的那条性质来写的
// 因为 s 结点不可能是 叶子结点,所以必然存在孩子结点(至少存在左孩子,因为是完全二叉树)
// 所以 j = 2 * s , j 就是表示 s 的左孩子。
{
if (j < m && L->r[j] < L->r[j+1])
j++; // 到这里, j 表示双亲结点、左右孩子结点中最大结点的下标。
if (temp >= L->r[j])
break;
L->r[s] = L->r[j]; // 到这里,L->r[j]为 s 的左或者右孩子结点中值较大的结点, 将这个值赋给双亲结点
// 即 现在的双亲结点是原来双亲结点、左右孩子结点中最大的,符合最大堆的定义
s = j;
}
L->r[s] = temp;
}
// 堆排序
void HeapSort(SqList * L)
{
int i;
for (i = L->length/2; i > 0; i--) // i 为什么是从L->length/2开始,根据完全二叉树的结点顺序可知,
// i 所表示的结点都不是叶子结点。
{
HeapAdjust(L, i, L->length);
}
for (i = L->length; i > 1; i--)
{
swap(L, 1, i); // 交换
HeapAdjust(L,1,i-1); // 重新调整为大顶堆。
}
}堆排序的时间复杂度为: O(nlogn);
参考资料
大话数据结构
堆排序算法解析