链接为:http://www.erogol.com/brief-history-machine-learning/
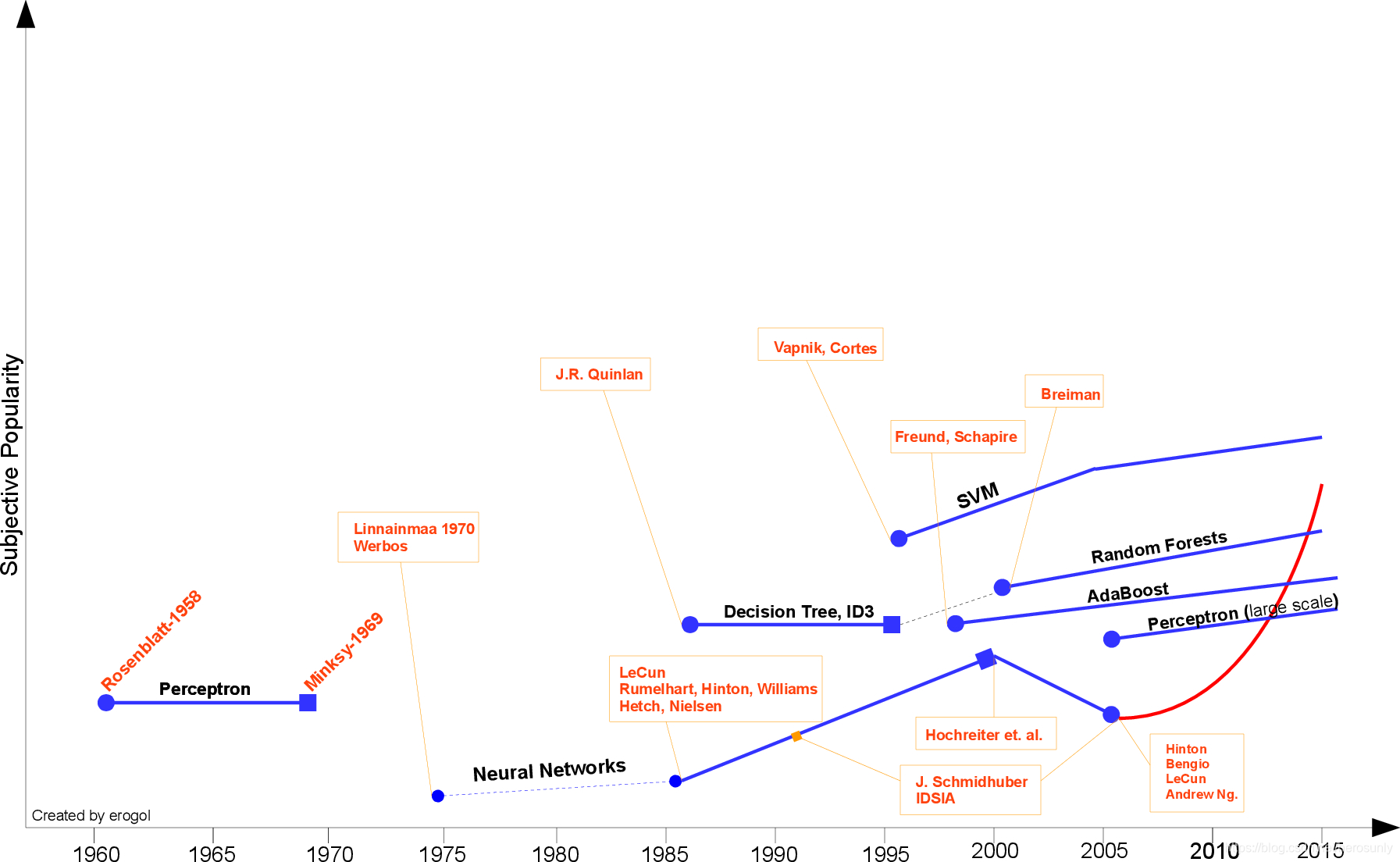
First step toward prevalent ML was proposed by Hebb , in 1949, based on a neuropsychological learning formulation. It is called Hebbian Learning theory. With a simple explanation, it pursues correlations between nodes of a Recurrent Neural Network (RNN). It memorizes any commonalities on the network and serves like a memory later. Formally, the argument states that:
1. 赫布理论
Let us assume that the persistence or repetition of a reverberatory activity (or “trace”) tends to induce lasting cellular changes that add to its stability.… When an axon of cell A is near enough to excite a cell B and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that A’s efficiency, as one of the cells firing B, is increased.[1]
赫布理论(英语:Hebbian theory)描述了突触可塑性的基本原理,即突触前神经元向突触后神经元的持续重复的刺激可以导致突触传递效能的增加。我们可以假定,反射活动的持续与重复会导致神经元稳定性的持久性提升……当神经元A的轴突与神经元B很近并参与了对B的重复持续的兴奋时,这两个神经元或其中一个便会发生某些生长过程或代谢变化,致使A作为能使B兴奋的细胞之一,它的效能增强了。这一理论经常会被总结为“一起发射的神经元连在一起”(Cells that fire together, wire together)。这可以用于解释“联合学习”(associative learning),在这种学习中通过对神经元的刺激使得神经元间的突触强度增加。这样的学习方法被称为赫布型学习(Hebbian learning)
突触是一个神经元和另一个神经元连接的部分,而神经元的突起是神经元胞体的延伸部分,由于形态结构和功能的不同,可分为树突(dendrite)和轴突(axon);树突是从胞体发出的一至多个突起,一个神经元里除了树突就是轴突,且每个神经元只有一个轴突。
2. 跳棋程序
In 1952 , Arthur Samuel at IBM, developed a program playing Checkers . The program was able to observe positions and learn a implicit model that gives better moves for the latter cases. Samuel played so many games with the program and observed that the program was able to play better in the course of time.
3. 感知机
In 1957 , Rosenblatt’s Perceptron was the second model proposed again with neuroscientific background and it is more similar to today’s ML models. It was a very exciting discovery at the time and it was practically more applicable than Hebbian’s idea. The perceptron is designed to illustrate some of the fundamental properties of intelligent systems in general, without becoming too deeply enmeshed in the special, and frequently unknown, conditions which hold for particular biological organisms.
Widrow engraved Delta Learning rule that is then used as practical procedure for Perceptron training. It is also known as Least Square problem. Combination of those two ideas creates a good linear classifier.
4. AI的第一次危机
However, Perceptron’s excitement was hinged by Minsky in 1969 . He proposed the famous XOR problem and the inability of Perceptrons in such linearly inseparable data distributions. It was the Minsky’s tackle to NN community. Thereafter, NN researches would be dormant up until 1980s.
5. MLP和BP
There had been not to much effort until the intuition of Multi-Layer Perceptron (MLP) was suggested by Werbos in 1981 with NN specific Backpropagation(BP) algorithm, albeit BP idea had been proposed before by Linnainmaa in 1970 in the name “reverse mode of automatic differentiation”. Still BP is the key ingredient of today’s NN architectures. With those new ideas, NN researches accelerated again. In 1985 - 1986 NN researchers successively presented the idea of MLP with practical BP training
6. 决策树算法
At the another spectrum, a very-well known ML algorithm was proposed by J. R. Quinlan in 1986 that we call Decision Trees , more specifically ID3 algorithm. This was the spark point of the another mainstream ML. Moreover, ID3 was also released as a software able to find more real-life use case with its simplistic rules and its clear inference, contrary to still black-box NN models. After ID3, many different alternatives or improvements have been explored by the community (e.g. ID4, Regression Trees, CART …) and still it is one of the active topic in ML.
7. SVM
One of the most important ML breakthrough was Support Vector Machines (Networks) (SVM), proposed by Vapnik and Cortes in 1995 with very strong theoretical standing and empirical results. That was the time separating the ML community into two crowds as NN or SVM advocates. However the competition between two community was not very easy for the NN side after Kernelized version of SVM by near 2000s .(I was not able to find the first paper about the topic), SVM got the best of many tasks that were occupied by NN models before. In addition, SVM was able to exploit all the profound knowledge of convex optimization, generalization margin theory and kernels against NN models. Therefore, it could find large push from different disciplines causing very rapid theoretical and practical improvements.
8. Adaboost
Little before, another solid ML model was proposed by Freund and Schapire in 1997 prescribed with boosted ensemble of weak classifiers called Adaboost. This work also gave the Godel Prize to the authors at the time. Adaboost trains weak set of classifiers that are easy to train, by giving more importance to hard instances. This model still the basis of many different tasks like face recognition and detection.
9. Random Forest
Another ensemble model explored by Breiman in 2001 that ensembles multiple decision trees where each of them is curated by a random subset of instances and each node is selected from a random subset of features. Owing to its nature, it is called Random Forests(RF) . RF has also theoretical and empirical proofs of endurance against over-fitting. Even AdaBoost shows weakness to over-fitting and outlier instances in the data, RF is more robust model against these caveats.(For more detail about RF, refer tomy old post.). RF shows its success in many different tasks like Kaggle competitions as well.
Random forests are a combination of tree predictors such that each tree depends on the values of a random vector sampled independently and with the same distribution for all trees in the forest. The generalization error for forests converges a.s. to a limit as the number of trees in the forest becomes large.
10. Deep Learning
As we come closer today, a new era of NN called Deep Learning has been commerced. This phrase simply refers NN models with many wide successive layers. The 3rd rise of NN has begun roughly in 2005 with the conjunction of many different discoveries from past and present by recent mavens Hinton, LeCun, Bengio, Andrew Ng and other valuable older researchers.
11. Now
With the combination of all those ideas and non-listed ones, NN models are able to beat off state of art at very different tasks such as Object Recognition, Speech Recognition, NLP etc. However, it should be noted that this absolutely does not mean, it is the end of other ML streams. Even Deep Learning success stories grow rapidly , there are many critics directed to training cost and tuning exogenous parameters of these models.
After the growth of WWW and Social Media, a new term, BigData emerged and affected ML research wildly. Because of the large problems arising from BigData , many strong ML algorithms are useless for reasonable systems (not for giant Tech Companies of course). Hence, research people come up with a new set of simple models that are dubbed Bandit Algorithms (formally predicated with Online Learning ) that makes learning easier and adaptable for large scale problems.
