HTTP Cookie
是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。
它用于告知服务端两个请求是否来自同一浏览器,以保持用户的登录状态。
Cookie主要用于以下三个方面:
会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
个性化设置(如用户自定义设置、主题等)
浏览器行为跟踪(如跟踪分析用户行为等)
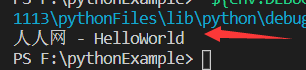
人人网爬虫实现登录
-
初次登录后退出
-
再次登录点击F12观察 看到一个返回document的请求 点击查看具体
 有人人网用户名 表面进入登录成功页
有人人网用户名 表面进入登录成功页

-
可以看到第二次登录内容中出现cookie 其中包含你的登录名以及加密后的密码

4.附上useragent和cookie 使用get方式去请求
具体代码如下:
import requests
from bs4 import BeautifulSoup
class renrenwangSpider():
def __init__(self, url, user_agent):
self._url = url
self._user_agent = user_agent
def makeCookie(self, cookie_str):
cookie = {
item.split("=")[0]: item.split("=")[1]
for item in cookie_str.split(";")
}
return cookie
def requestRenrenWebsite(self, cookie):
try:
res = requests.get(self._url,
headers=self._user_agent,
cookies=cookie)
if res.status_code == 200:
return res.text
except requests.RequestException:
return None
def getTitle(self, html):
soup = BeautifulSoup(html, "lxml")
return soup.title.string
def main():
url = "http://www.renren.com/974135345"
user_agent = {
"User-Agent":
"机密 自填"
}
cookie_str = "Cookie: 自填"
spider = renrenwangSpider(url,user_agent)
cookie=spider.makeCookie(cookie_str)
res=spider.requestRenrenWebsite(cookie)
title=spider.getTitle(res)
print(title)
if __name__ == '__main__':
main()
若查询结果为你登录网名 则为成功