Searching and Mining Trillions of Time Series Subsequences under Dynamic Time Warping
T. Rakthanmanon, B. Campana, A. Mueen, et al., Searching and Mining Trillions of Time Series Subsequences under Dynamic Time Warping, KDD (2012) (Best Paper)
预备知识
动态时间规整
、 分别为 、 维时间序列(time series)
动态时间规整(dynamic time warping,DTW):利用动态规化(DP)计算距离最小的最佳映射,“时间扭曲”是指为计算最佳映射,需要在时间上压缩或扩展(compress or expand in time)。
规整路径(mapping path): ,使 最小,且满足
-
边界条件(boundary conditions): 、
-
局部约束(local constraint):路径上任意节点 ,其候选节点(fan-in node)为 , , 。该约束保证映射路径单调非减(monotonically non-decreasing)。且对于 中的任意元素, 中至少有一个元素与之对应,反之亦然。
DTW计算(前向DP):
-
最优值函数(optimum-value function): 为 与 间的DTW距离
-
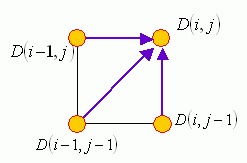
初始条件: ,递归( ):
- 输出
实现:构造 维的矩阵 ,将初始条件填入 ,然后根据递归公式逐列(行)填充矩阵。计算时间复杂度为 。
DTW计算(反向DP):
-
最优值函数(optimum-value function): 为 与 间的DTW距离,
-
初始条件: ,递归( ):
- 输出
DTW距离不满足距离三角不等式且计算时间复杂度高。
DTW下界距离(lower bounding)
DTW下界距离:采用计算更简单的距离度量粗略估计DTW距离,通过DTW下界过滤掉不满足相似性要求的序列,提高查询效率
DTW下界距离应满足3个条件:
-
正确性:经下界距离过滤得到的候选集中必须包含所有满足条件的序列,即不允许出现漏报;
-
有效性:下界距离的计算复杂度应尽量低;
-
紧致性(tightness):下界距离的度量结果应尽量逼近DTW距离,使候选集不至过大,减少后处理计算量
常用DTW下界距离:
LB_Yi:
LB_Kim: 、 以起始点、结束点为特征构造DTW下界距离, ;、以起始点、结束点最大值点和最小值点为特征构造DTW下界距离,
LB_Keogh:查询序列(query)的上、下边界序列 与候选序列(candidate sequence)对应点间欧氏距离较近者作为DTW下界距离,
LB_Zhu:
LB_GMBR:对时间序列进行分段累积近似,用网格最小边界矩形近似表示查询序列
摘要
在DTW距离下,实现大规模数据集上的精确搜索,且比已知欧氏距离(Euclidean distance)搜索算法更快。
1 引言
在大多数时序问题中,动态时间规整(dynamic time warping,DTW)是最佳测度(the best measure),但其过高的计算复杂度限制其应用。
1.1 万亿数据量(A Brief Discussion of a Trillion)
万亿(trillion): ,已知论文处理时序数据(time series data)规模至多数亿(one hundred million objects)。
1.2 默认条件(Explicit Statement of our Assumptions)
1.2.1 时序子序列必须标准化(Time Series Subsequences must be Normalized)

比较时,除了对整个数据集进行标准化,还需对每个子序列标准化(normalize each subsequence before making a comparison, it is not sufficient to normalize the entire dataset)。
1.2.2 DTM是最佳测度(Dynamic Time Warping is the Best Measure)
经验表明(800余篇论文):DTM是最佳测度。
1.2.3 任意长度的查询序列无法索引(Arbitrary Query Lengths cannot be Indexed)
当数据集规模超过10亿时,现有技术无法进行任意长度序列的相似性搜索(there are no known techniques to support similarity search of arbitrary lengths once we have datasets in the billions)。
1.2.4 某些数据挖掘问题需要耗时数小时(There Exists Data Mining Problems that we are Willing to Wait Some Hours to Answer)
2 相关工作
本文考虑精确搜索(exact search)
3 背景(Background and Notations)
3.1 定义(Definitions and Notations)
定义1:时间序列(Time Series) ,
定义2:子序列(subsequence) ,起始位置为 、长度为 的时间序列,
查询序列(query): ,
候选匹配(a Candidate match to a query ): (子序列 )
定义3:当 时, 和 之间的欧式距离(Euclidean distance,ED)为

欧式距离(一一映射(a one-to-one mapping of the two sequence),Fig. 2)时DTW(一对多映射(one-to-many alignment),Fig. 3)的特例。
DTW对齐:构造 矩阵,矩阵的第 元素表示 和 的ED距离 。
规整路径(warping path) :一组矩阵元素的连续集合(a contiguous set of matrix elements),给出了 和 之间的映射关系。 的第 个元素定义为 ,则有:
规整路径必须以矩阵反对角元素的角点作为起点和终点,路径中各步限制在相邻单元中选取且路径点沿时间轴单调增加(start and finish in diagonally opposite corner cells of the matrix, the steps in the warping path are restricted to adjacent cells, and the points in the warping path must be monotonically spaced in time)。
些外,对规整路径各点与对角位置偏移也可作全局限定(constrain the warping path in a global sense by limiting how far it may stray from the diagonal)。如Sakoe-Chiba带(Sakoe-Chiba Band),规整路径不能偏离对角位置
个单元(the warping path cannot
deviate more than R cells from the diagonal)。

4 算法
4.1 现有优化方法(Known Optimizations)
4.1.1 平方距离(Using the Squared Distance)
DTW和ED都需要开方计算(square root calculation)。由于平方根距离和平方距离均是单调凸函数(monotonic and concave),因此采用平方距离计算时,并不会改变最近邻的相对排序(the relative rankings of nearest neighbors);此外,相比平方根距离,平方距离更易于优化(the absence of the square root function will make later optimizations possible and easier to explain)。
4.1.2 下界距离(Lower Bounding)
利用计算时间复杂度低的下界距离对候选子序列进行过滤(A classic trick to speed up sequential search with an expensive distance measure such as DTW is to use a cheap-to-compute lower bound to prune off npromising candidates)。

下界距离(
):采用
和
的第一(最后)点对间的距离作为下界距离(原始
需要计算两个时间序列间距的最大值和最小值(the original definition of
also uses the distances between the maximum values from both time series and the minimum values between both time series in the lower bound),其计算时间复杂度为
),然而经标准化后,这两个极值变得很小。忽略这两个极值后,计算时间复杂度为
);
下界距离( ):首先构造 的上边界 和下边界 ,然后分别计算 、 与 对应各点对间的距离,取二者中较小的作为距离下界。
4.1.3 提前终止ED和Keogh下界距离计算(Early Abandoning of ED and )
计算ED、
下界距离时,当累积的差值平方和(the current sum of the squared
differences)大于
时,终止计算。

4.1.4 提前终止DTW距离计算(Early Abandoning of DTW)
已知 上下边界,计算DTW第 个路径点时, 为真实DTW距离( )的下界,即
当该下界大于 时,终止计算(compute the DTW from to , sum the partial DTW accumulation with the contribution from to ,This sum of is a lower bound to the true DTW distance ( ),If at any time this lower bound exceeds the best-so-far distance we can admissibly stop the calculation and prune this )。

4.1.5 多核处理(Exploiting Multicores)
4.2 UCR优化策略(Novel Optimizations: The UCR Suite)
本文给出4种基于ED和DTW距离的优化策略。
4.2.1 提前终止标准化(Early Abandoning Z-Normalization)
本文将提前终止ED(或Keogh下界距离)计算与在线(online)标准化(Z-Normalization)结合。子序列的均值和方差可通过更新两个相差 个值的(a lag of exactly values)求和(keeping two running sums)计算:

为避免累积浮点误差(accumulation of the floating-point error),每一百万条子序列执行一次完全标准化(once every one million subsequences, we force a complete Z-normalization to “flush out” any accumulated error)。
4.2.2 重排序提前终止(Reordering Early Abandoning)

排序的差异对加速产生的影响很大(on a query-by-query basis, different orderings produce different speedups)
本文猜测:基于标准化 的绝对值对索引排序是通用最优顺序(the universal optimal ordering is to sort the indices based on the absolute values of the Z-normalized )。标准化候选子序列搜索问题中, 大多服从0均值高斯分布,因此查询序列中绝对值最大的部分对距离度量的平均贡献最大(for subsequence search, with Z-normalized candidates, the distribution of many ’s will be Gaussian, with a mean of zero. Thus, the sections of the query that are farthest from the mean, zero, will on average have the largest contributions to the distance measure)。该技巧可应用于ED和 (use this trick for both ED and ),并与提前终止标准化(4.2.1)一起使用(use it in conjunction with the early abandoning Z-normalization technique)。
4.2.3 交换查询序列与候选序列在 中的角色(Reversing the Query/Data Role in )
通常, 下界距离为查询序列构造包络(normally the lower bound builds the envelope around the query),记为 。由于 只需计算一次,因此节省时间和空间开销(save the time and space overhead)。
本文为每个候选序列构造包络,记为 。

仅当其余下界无法剪枝时,才计算
(selectively calculate
in a “just-in-time” fashion, only if all other lower bounds fail to prune),因此消除了空间开销(remove space overhead)。
时间开销能够通过减少DTW计算获得补偿(the time overhead pays for itself by pruning more full DTW calculations)。
注意:
4.2.4 级联多个下界(Cascading Lower Bounds)
下界需在紧致性与计算复杂度之间妥协(a tradeoff between the tightness of the lower bound and how fast it is to compute)。
下界紧致性衡量:

选择天际线(skyline)上的下界(Fig. 9中的虚线)。注意提前终止DTW计算(4.1.4)不在Fig. 9中,该方法逐步累加DTW并与下界比较,直至得到最终结果(it produces a spectrum of bounds, as at every stage of computation it is incrementally computing the DTW until the last computation gives the final true DTW distance)。
本文将天际线上的各下界级联使用(use all of the lower bounds on the skyline in a cascade):
(1)计算 , ,剪枝;
(2)计算 ( ),剪枝;
(3)计算 (4.2.3),剪枝;
(4)计算DTW(4.1.4,提前终止)
在大规模搜索问题中,上述方法可减少99.9999%的DTW计算(prune more than 99.9999% of DTW calculations for a large-scale search)。
5 实验
5.1 随机游走基线测试(Baseline Tests on Random Walk)


5.2 长序列查询:脑电图(Supporting Long Queries: EEG)


5.3 超长序列查询:脱氧核糖核酸(Supporting Very Long Queries: DNA)


5.4 实时数据(Realtime Medical and Gesture Data)

