1.文档目的
本文面向的读者是所有开发的同学,熟悉安装zookeeper、hadoop和hbase的流程,并能自主解决安装过程中遇到的问题。 本文档主要是描述安装和配置zookeeper、hadoop和hbase分布式集群的详细步骤。使用本文档需要在VMware上安装centOS虚拟机。
2.集群架构
三个节点,一个主,3个从。节点之间局域网连接,可以相互ping通,节点IP地址分布如下:
主机名 IP 系统版本 Hadoop节点
master 192.168.8.22 centOS 6.2 主
node1 192.168.8.23 centOS 6.2 从
hbase 192.168.8.33 centOS 6.2 从
3.修改/etc/hosts文件
/etc/hosts文件是IP地址对应其主机名的文件,是机器知道IP和主机名的对应关系。在每一台服务器上执行vi /etc/hosts,在最后加上以下内容:
#ipAddress HostName
192.168.8.22 master
192.168.8.23 node1
192.168.8.66 hbase
4.本机连上hbase集群
4.1.修改本机hosts文件
在本机中打开hosts文件,目录为C:\Windows\System32\drivers\etc/hosts,加入以下内容:
192.168.8.33 hbase
192.168.8.22 master
192.168.8.23 node1

4.2.关闭本机防火墙
hbase集群上的服务器的防火墙都已关闭,这里只是关闭本机防火墙。
以win7为例,控制面板→Windows防火墙→打开或关闭防火墙,然后选择关闭防火墙:

4.3.本机ping通集群服务器
在本机cmd中输入以下命令:
ping 192.168.8.22
发现ping不通

使用以下步骤使本机能ping通集群服务器:
打开网络与共享中心→本地连接→属性,如图:

选择TCP/Ipv4→属性→高级(V)…,如图:

添加ip地址
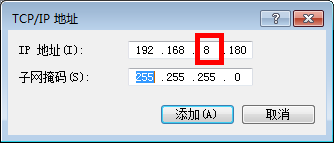
点击添加,然后一直关闭确认,再次在cmd中输入以下命令:
ping 192.168.8.22
结果就能ping通了
5.配置ssh无密码登录
5.1.新建hadoop用户
(1)添加一个hadoop用户组
sudo groupadd hadoop
(2)设置hadoop用户密码
passwd hadoop
输入两次密码即可。
(3)将run下面所有文件的属组都改成hadoop和hadoop
chown -R hadoop:hadoop /run/
(4)使用hadoop用户
su hadoop
在整个安装过程中都使用hadoop用户。
(5)将当前用户加入到hadoop组
sudo usermod –a –G hadoop hadoop
前面一个hadoop是组名,后面一个hadoop是用户名。
(6)使用root用户修改/etc/sudoers,使用如下命令:
vi /etc/sudoers
在root ALL=(ALL) ALL后面增加
hadoop ALL=(ALL) ALL
输入:wq!强制保存。
(7)修改hadoop目录的权限
sudo chown –R hadoop:hadoop /run/install
sudo chmod –R 755 /run/install
(8到10先不执行)
(8)修改HDFS的权限
sudo bin/hadoop dfs –chmod –R 755/
(9)修改HDFS文件的所有者
sudo bin/hadoop fs –chown –R hadoop/
(10)解除hadoop的安全模式
sudo bin/hadoop dfsadmin –safemode leave
5.2.配置ssh免密登录(这里使用hadoop用户)
(1)配置每一台服务器ssh免密登录
在每一台服务器上执行以下操作:
1)生成密钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2)将id_dsa.pub(公钥)追加到授权的key中:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
(2)将另外两个节点的id_dsa.pub(公钥)复制到master服务器上
scp ~/.ssh/id_dsa.pub hadoop@master:~/.ssh/id_dsa.pub.node1
scp ~/.ssh/id_dsa.pub hadoop@master:~/.ssh/id_dsa.pub.hbase
(3)将从节点的公钥追加到master授权的key中:
cat ~/.ssh/id_dsa.pub.node1 >> ~/.ssh/authorized_keys
cat ~/.ssh/id_dsa.pub.hbase >> ~/.ssh/authorized_keys
(4)将master节点的authorized_keys复制到从节点的authorized_keys
scp ~/.ssh/authorized_keys hadoop@node1:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hbase:~/.ssh/authorized_keys
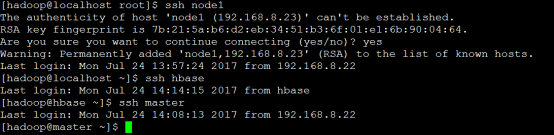
(5)验证ssh是否成功:
ssh hbase

发现还要输入密码,这是因为.ssh的权限不够的问题。输入以下命令:
chmod 700 ~/.ssh
chmod 644 ~/.ssh/authorized_keys

第一次连接需要确认连接,输入yes即可,可以测试一下所有节点是否都可以互通ssh登录。
6.JDK安装
6.1.解压jdk安装包
在每一台服务器上安装相同版本的jdk,且安装在相同的目录下。安装JDK1.6或者以上版本,这里安装1.7.0_75,解压到
/usr/java/jdk1.7.0_75;
tar –xzvf jdk-7u75-linux-x64.tar.gz –C /usr/java/
6.2.配置JAVA_HOME环境变量
在/root/.bash_profile中添加如下配置:
–-这里的目录是在/run/install/ jdk1.7.0_75
vi /root/.bash_profile
export JAVA_HOME=/usr/java/jdk1.7.0_75
export PATH=$JAVA_HOME/bin:$PATH
为使环境变量生效,在终端输入命令
source ~/.bash_profile
6.3.验证jdk是否安装成功
输入命令 java -version,如图所示,表示安装成功

6.4.分发并同步安装包
在master服务器上安装好jdk之后,直接将解压后的jdk文件夹copy到另外两个服务器的相同目录下,然后在/root/.bash_profile中添加JAVA_HOME环境变量就好了。
scp –r /run/install/jdk1.7.0_75/ hadoop@node1/java/jdk1.7.0_75
scp –r /run/install/jdk1.7.0_75/ hadoop@node2/java/jdk1.7.0_75
分别在两个服务器上添加/root/.bash_profile文件中的配置:
vi /root/.bash_profile
export JAVA_HOME=/run/install/java1.7.0_75
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bash_profile
验证环境变量是否配置成功:


7.hadoop集群安装配置(三个环境都要装,使用hadoop用户)
7.1.解压hadoop安装包
复制hadoop-2.8.0.tar.gz 到/run/install目录下,然后输入命令
tar -xzvf hadoop-2.6.0.tar.gz
解压,解压后目录为:/run/install/hadoop-2.8.0
7.2.配置hadoop环境变量
输入命令
vi ~/.bash_profile
按insert键编辑文本,在最后写入
#Hadoop Env
export HADOOP_HOME=/run/install/hadoop-2.8.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
编辑完成后按esc;进入命令模式,然后后输入:wq保存退出
使环境变量生效,输入命令
source ~/.bash_profile
7.3.配置hadoop-env.sh
功能:配置环境变量,一般有java home,hadoopcpmfdir等这些软件,配置目录,有运行过程中使用的变量,如hadoop栈大小配置,java运行内存大小配置等等。
文件路径:HADOOP_HOME/etc/hadoop/hadoop-env.sh,添加如下配置:
export JAVA_HOME=/run/install/jdk1.7.0_75
export HADOOP_PREFIX=/run/install/hadoop-2.8.0
见如图示例:

7.4.配置yarn-env.sh
功能:配置环境变量,如java home等。
文件路径:HADOOP_HOME/etc/hadoop/yarn-env.sh, 添加如下配置:
export JAVA_HOME=/run/install/jdk1.7.0_75
见如图示例:

7.5.配置core-site.xml
功能:用于定义系统级别的参数,如HDFS URL、Hadoop的临时目录等。
文件路径:HADOOP_HOME/etc/hadoop/core-site.xml, 添加如下配置:
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/run/install/hadoop-2.8.0/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
见如下示例:
 注意:tmp目录需提前创建
注意:tmp目录需提前创建
7.6.配置hdfs-site.xml
功能:用于定义HDFS参数,如名称节点和数据节点的存放位置、文件副本的个数、文件的读取权限等。
文件路径:HADOOP_HOME/etc/hadoop/hdfs-site.xml, 添加如下配置:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
见如下示例:
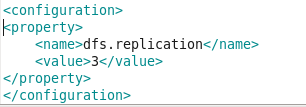
数据有3个副本,默认值就是3。
7.7.配置mapred-site.xml
功能:用于定义mapreduce参数,包括JobHistory Server和应用程序参数两部分,如reduce任务的默认个数、任务所能使用内存的默认上下线等。
复制mapred-site.xml.template文件,并改名为mapred-site.xml,添加如下配置:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
见如下示例:
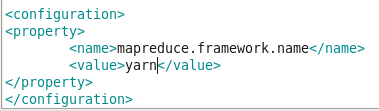
默认值:local。取值local、classic或yarn其中之一,如果不是yarn,则不会使用yarn集群来实现资源的分配。
7.8.配置yarn-site.xml
功能:用于定义集群资源管理系统参数,如配置ResourceManager,NodeManager的通信端口,web监控端口等。
文件路径:HADOOP_HOME/etc/hadoop/yarn-site.xml, 添加如下配置:
<
property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
见如下示例:

通过aux-services配置项,用户可以自定义一些服务,;比如mapreduce的shuffle功能就是采用这种方式实现的,这样就可以在nodeManager上扩展自己的服务。
7.9.配置slaves
功能:记录机群里所有DataNode的主机名。
文件路径:HADOOP_HOME/etc/hadoop/slaves, 添加如下配置:
master
node1
hbase
见如下示例:

master节点既作为NameNode节点也作为DataNode节点。
7.10.分发并同步安装包
在node1和hbase上也做同样的配置,直接将master上配置好的hadoop复制到node和hbase节点的相同目录。
scp -r /run/install/hadoop-2.8.0/ root@node1:/run/install/hadoop-2.8.0
(这里的用户改为hadoop)
scp –r /run/install/hadoop-2.8.0/ root@hbase:/run/install/hadoop-2.8.0
(这里的用户改为hadoop)
7.11.启动hadoop 集群
注意:以下命令接在hadoop根目录下执行
(1)格式化文件系统
在master机器上执行以下命令:
bin/hdfs namenode –format
(只需要在第一次启动时,执行这个命令)
(2)启动NameNode 和 DataNode ,在master机器上执行以下命令:
sbin/start-dfs.sh

使用jps命令查看master上的Java进程:
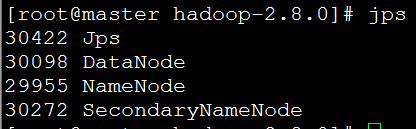
使用jps命令分别查看node1和hbase上的Java进程:
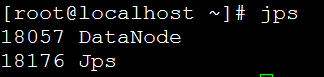

可以看到NameNode和DataNode均启动成功。
(3)查看NameNode和DataNode信息
浏览器输入地址:http://master:50070/可以查看NameNode信息。

(4)启动ResourceManager 和 NodeManager
在master机器上运行以下命令:
sbin/start-yarn.sh

使用jps命令查看master上的Java进程:
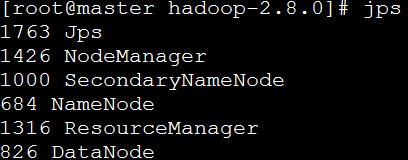
可以看到master上ResourceManager 和 NodeManager均启动成功。
使用jps命令分别查看node1和hbase上的Java进程:

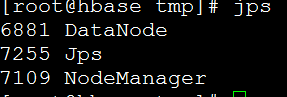
可以看到node1和hbase上NodeManager都启动成功了。
(5)启动验证
在浏览器中输入http://localhost:8088/ 即可看到YARN的ResourceManager的界面。
注意:8088是默认端口,可以通过设置yarn.resourcemanager.webapp.address值为${yarn.resourcemanager.hostname}:端口号 来设置访问端口。

7.12.有的时候启动不了包name的clusterID和data的clusterID不一致的问题
需要将两个clusterID改为一致的。
Data:/run/install/hadoop-2.8.0/tmp/dfs/data/current/VERSION
Name: /run/install/hadoop-2.8.0/tmp/dfs/name/current/VERSION
这两个文件中有两个clusterID
8.zookeeper集群安装配置
8.1.解压zookeeper安装包(三个服务器都要装)
复制zookeeper-3.4.10.tar.gz 到/run/install目录下,然后输入命令
tar –xzvf zookeeper-3.4.10.tar.gz
解压,解压后目录为:/run/install/zookeeper-3.4.10
8.2.修改配置文件zoo.cgf
进入/run/install/zookeeper-3.4.10/conf目录,:
cp zoo_sample.cfg zoo.cfg
复制zoo_sample.cfg文件为zoo.cfg,并编辑如下:
dataDir=/run/zookeeper
server.1=master:2888:3888
server.2=node1:2888:3888
server.3=hbase:2888:3888
说明:
master:代表zookeeper的主机名
2888:代表访问zookeeper的端口
3888:代表重新选举leader的端口
8.3.新建并编辑myid文件
在dataDir目录下新建myid文件,输入一个数字(master为1,node1位,hbase为3):
(是不是1,2,3)
mkdir /run/zookeeper
echo “1” > /run/zookeeper/myid
使用scp命令进行远程复制myid文件,然后修改相应节点上myid文件中的数字。
8.4.启动zookeeper集群
在zookeeper集群的每个节点上,执行启动zookeeper服务的脚本
bin/zkServer.sh start



用jps命令查看zookeeper启动情况:
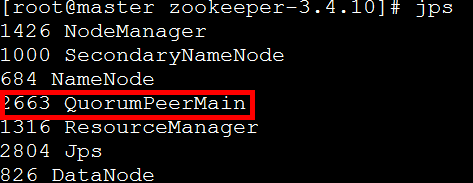
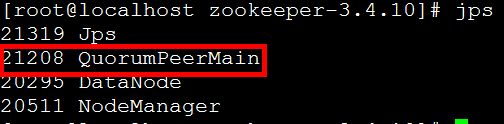

3个节点zookeeper均启动成功,查看zookeeper状态:



3个节点中,node1节点是leader,其他两个节点都是follower,这个leader是zookeeper集群自动选举出来的。
8.5.启动zookeeper集群可能遇到的问题
1.如果启动报类似异常:QuorumCnxManager@588] - Cannot open channel to 1 at election address master/192.168.8.22:3888是可以忽略的,因为该服务启动时会尝试连接所有节点,而其他节点尚未启动。通过后面可以看到,集群在选出一个leader后,就稳定了。其他节点可能也会出现类似异常,属于正常。
2.未关闭防火墙,可能出现很多连接方面的问题。
No route to host
connection refuse
KeepErrorCode = ConnectionLoss for xxx等这类错误,所以一定要关闭防火墙。
3.关闭防火墙方法:
查看状态:
service iptables status
生效,重启后复原:
开启:
service iptables start
关闭:
service iptables stop
永久性生效,重启后不会复原:
开启:chkconfig iptables on
关闭:chkconfig iptables off
9.Hbase集群安装配置
9.1.解压hbase安装包
复制hbase-1.3.1-bin.tar.gz 到/run/install目录下,然后输入命令
tar –xzvf hbase-1.3.1-bin.tar.gz
解压,解压后目录为:/run/install/hbase-1.3.1;
9.2.配置hbase-env.sh
文件路径:/run/install/hbase-1.3.1/conf/hbase-env.sh,添加以下配置:
export JAVA_HOME=/run/install/jdk1.7.0_75
export HBASE_CLASSPATH=/run/install/hbase-1.3.1
export HBASE_MANAGES_ZK=false
见如下所示:

9.3.配置hbase-site.xml
文件路径:/run/install/hbase-1.3.1/conf/hbase-site.xml,添加以下配置:
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>master</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,node1,hbase</value>
</property>
–这里的hbase一定要命名hbase吗?node2,这里填写集群中的服务器
<property>
<name>zookeeper.session.timeout</name>
<value>60000000</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
见如下所示:

9.4.配置regionservers
文件路径:/run/install/hbase-1.3.0/conf/regionservers,在其中添加slave列表(这里要干掉之前的内容,也就是说覆盖掉原来文件):
node1
hbase
见如下所示:
9.5.分发并同步安装包
将hbase安装目录复制到所有的slave服务器:
scp -r /run/install/hbase-1.3.0/ root@node1:/run/install/hbash-1.3.1
scp –r /run/install/hbase-1.3.0/ root@hbase:/run/install/hbase-1.3.1
9.6.启动Hbase集群
注意:启动hbase前,确保hadoop集群以及zookeeper集群已正常启动
在master服务器上执行命令
bin/start-hbase.sh
正常启动提示信息如下所示:

启动后,master和slave上进程列表:


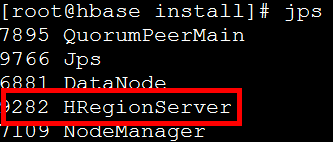
同时可以浏览器端查看,输入地址master:16010,正常启动浏览器端如下所示:

输入命令bin/hbase shell,进入hbase shell进行验证:

9.7.hbase启动可能出现的问题
报ClockOutOfSyncException: Server hbase,16020,1500264051644 has been rejected; Reported time is too far out of sync with master. Time difference of 1049395ms > max allowed of 30000ms类似异常
这是由于三台虚拟机的时间不一致造成的,解决方法如下:
1)在hbase-site.xml中增加以下内容,将时间改大点:
<property>
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
2)修改系统时间,将时间改为一致
修改日期
date -s 7/18/2017
修改时间
date -s 16:33:00
查看硬件(CMOS)时间
clock –r
将系统时间写入CMOS
clock -w
3)修改完成后,重启hbase就好了
10.参照《HBASE API操作文档》,使用Java API操作hbase数据库(后续补充此文档)。
原创不易,喜欢本文的朋友,给博主点个赞关注一下吧~
