原标题:运用Python做一个ip代理池
前言:
作为对Python爬虫才一点的进步的小白,我对于IP代理池也不是很理解,如果没有达到读者的要求,还请见谅!我今天写的这篇文章主要是讲运用Python爬虫爬取西祠代理上可用的IP,然后将这些写到一个.txt文件中,然后在用这些IP访问网址的量和我自己的IP访问网址的量做一个对比。
文章目录
1.运用Python爬虫爬取西祠代理上可用的IP代理
1.1需要的模块
完成这个过程需要的Python模块只需要两个即可,即requests(urllib模块也可)模块和lxml模块(bs4模块也可),之所以不用括号里面的模块也许大家都清楚吧!那就是用这两个模块比较简单,既然有简单的,为什么还要用复杂的呢?
1.2 具体实现过程
实现我们需要来到西祠代理这个网址: 西祠代理
也就是如下界面:

我们需要爬取上面的IP地址和端口号,按电脑键盘的F12键

发现IP地址和端口号分别在上面那个标签下面第二个和第三个标签下面。
代码实现:
ip_list=HTML.xpath('//tr[@class="odd"]/td[2]/text()') # IP
ips_list=HTML.xpath('//tr[@class="odd"]/td[3]/text()') # 端口号
这样我们就得到了ip地址和端口号了,然后就只需判断这个ip可不可用了,我是直接用百度这个网址拿来测试的,如果通过访问返回的状态码为200,就表明这个ip地址是可用的
代码实现:
try:
response_1=requests.get(url='https://www.baidu.com/',proxies=proxies,timeout=6)
# timeout 超时设置
print(response_1.status_code)
if response_1.status_code==200:
ip_useful.append(ip_list[i])
except:
print('没用!')
当然,既然是这种不知道什么时候会出错的,要用上try和except,为了减少判断ip是否可用的时间,这里用到了的超时设置,下面就来看一下具体运行结果吧!我这里只用了西祠代理一页的内容。

2.通过爬取的IP代理和自己的IP访问网址的量进行对比
上面那个运行完毕之后,会在同一个文件夹下面出现一个ip.txt的文件,上面的可用的ip代理就在这个文件里面,如下:
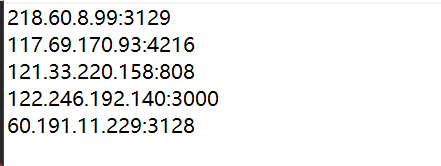
大家也许会觉得很少,但不要忘记我这里只是爬取了一页西祠代理上面可用的ip,然后,我用这些ip来访问了一下快代理,发现如下:

可以发现,运用这几个ip代理可以访问快代理这个网址到一千多页,如果不用ip代理,或许最多也只能访问一百多页吧!
代码如下:
import requests
with open(file='./ip.txt',mode='r',encoding='utf-8') as f:
str1=f.read()
list1=str1.split('\n')[:-1]
j=0
for i in range(1,3001):
try:
proxies={'https':list1[j]}
try:
response=requests.get(url='https://www.kuaidaili.com/free/inha/{}/'.format(i),proxies=proxies)
print(response.url)
print(response.status_code)
except:
j+=1
print('第{}ip开始'.format(j))
except:
print('所有代理已经全部使用!')
break
不用ip代理运行结果:

在访问这个网址时,发现如下,无论我怎样刷新都是这样,或许是ip被封了吧!

3.完成代码
import requests
from lxml import etree
def get_usefulip():
url='https://www.xicidaili.com/wn/'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3756.400 QQBrowser/10.5.4039.400'}
response=requests.get(url=url,headers=headers)
HTML=etree.HTML(response.text)
ip_list=HTML.xpath('//tr[@class="odd"]/td[2]/text()') # IP
ips_list=HTML.xpath('//tr[@class="odd"]/td[3]/text()') # 端口号
ip_useful=[]
for i in range(len(ips_list)):
ip_list[i]+=':{}'.format(ips_list[i])
proxies={'https':ip_list[i]}
print(ip_list[i],end=' ')
try:
response_1=requests.get(url='https://www.baidu.com/',proxies=proxies,timeout=6)
# timeout 超时设置
print(response_1.status_code)
if response_1.status_code==200:
ip_useful.append(ip_list[i])
except:
print('没用!')
return ip_useful
with open(file='./ip.txt',mode='w',encoding='utf-8') as f:
for i in get_usefulip():
f.write(i+'\n')
读者还可以把这个代码改进一下,访问多页的西祠代理,不过这样时间会久一点,但可用的IP会多一点。
4. 总结
这个项目也许对于一些Python爬虫的大牛来说,我的这篇文章对于ip代理池的讲解还不完善。如果读者有什么好的建议的话,欢迎在下面留言,如果觉得我的这篇文章还写的还可以,记得给我点一个小小的赞,谢谢!
