K-近邻算法(KNN)原理分析和代码实战
前言
K-近邻算法,全称为K-nearest neighbor,简称KNN。它是一个原理非常简单,但是计算复杂度比较高的一个分类算法,接下来,我们先从原理出发,再进行源代码的解析。
源代码地址:KNN
原理分析
通过计算输入数据与模型数据的欧几里得距离,选取前K个距离最短的模型数据,类型出现次数最多的就是输入数据所属的类型。
我们来看一下下面这个图(画的不好,大家多多担待)

上图中,黑色点为输入数据,棕色和红色数据均为模型数据,我们假设棕色数据属于1类,红色数据属于2类,假设K等于5.
步骤:
- 计算黑色数据与棕色数据和红色数据之间的距离(欧几里得距离)
- 找出与黑色数据距离最近的五个数据,如图中橘黄色线段
- 统计这五个数据所属的分类。图中这5个数据中,有3个是红色数据,属于2类,2个棕色数据,属于1类
- 选择数量最多的类别,即为输入数据的类别。图中5个数据中,红色数据个数大于棕色数据个数,所以,输入数据属于2类。
欧几里得距离公式:
二维
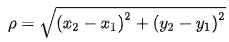
多维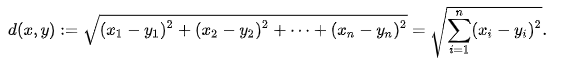
原理很简单,接下来咱们分析一下算法优缺点
优点:
- 原理简单,不涉及复杂的数据理论知识,只有一个欧几里得距离计算
- 对异常数据不敏感
- 精准度比较高
- 适用于数值型数据和标称型(就是取值有限,比如0、1或者是、否)数据
缺点:
- 计算量太大,每次输入数据,都需要与模型中所有数据进行欧几里得距离计算
- 占用的空间比较大。
源代码解析
项目背景:
此项目数据集使用得是《机器学习实战》一书提供得关于约会对象匹配得数据集,该数据集共有四列数据,前三列是数据的属性,分别是 行里程数、玩游戏时间占比、消耗冰淇淋公升数,最后一列是数据的归属类,数据一共分类3类,分别是1、2、3.
数据存储在txt文件中,不同属性的数据使用空格进行分割,下图是数据格式:

一、加载数据
import numpy as np
import operator
def loaddatasets(dataseturl,datatype='train'):
datasetLabel = []
datasetClass = []
with open(dataseturl) as f:
datas = f.readlines()
for data in datas:
dataline = data.strip().split('\t')
datasetLabel.append(dataline[:-1])
datasetClass.append(dataline[-1])
if(type=='train'):
datasetLabel = datasetLabel[:900]
datasetClass = datasetClass[:900]
else:
datasetLabel = datasetLabel[900:]
datasetClass = datasetClass[900:]
return datasetLabel,datasetClass
此方式是加载数据,这里原数据一共有1000个,由于数据本身就是乱序,所以我们不需要对数据进行乱序处理。我们选取前900个数据为模型数据,后100个数据作为测试数据。分别将数据的属性和数据所属类存储到不同的列表中。
二、数据归一化
## 数据归一化
def normalized_dataset(dataset):
dataset = np.array(dataset,dtype='float')
max = np.max(dataset,axis=0)
min = np.min(dataset,axis=0)
result = (dataset-min)/(max-min)
return result,max,min
这里使用的公式是(x-min)/(max-min).为什么要进行归一化呢,从数据集中我们可以看到,这三个属性的值差别很大。由于KNN算法是通过计算空间距离来判定数据归属,那么,值比较大的就会对计算产生较大的影响,所以,在这里,我们对数据进行归一化处理,使其数据在0-1的范围之间。
三、计算欧几里得距离
## 计算欧几里得距离
def calculate_distance(dataset,x):
#此时算出了新数据x与原来每个数据之间的距离
result = np.sqrt(np.sum(np.power((dataset-x),2),axis=1))
#返回值是形状为(length,1)的数组
return result
这里就是计算欧几里得距离,所使用的公式就是上面图中所给的公式。
四、进行分类计算
## 进行分类
def KnnClassify(k,inputdata,datasetLabel,datasetClass):
# print(result)
distance = calculate_distance(datasetLabel,inputdata)
sortdistanceindex = np.argsort(distance)
#print("sortdistanceindex",sortdistanceindex)
classcount={ }
for i in range(k):
klist=datasetClass[sortdistanceindex[i]]
classcount[klist] = classcount.get(klist,0)+1
#这里需要记录一下,如何对字典中某一属性进行排序
sortedClassCount = sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
#print("sortedClassCount:",sortedClassCount)
return sortedClassCount[0][0]
- 前两行计算输入数据与模型数据的空间距离,然后对距离数据进行排序。argsort 这里方法返回的是排序数据原来索引值,这样做方便我们找到与之对应的原数据。
- 循环K次,找到距离最短的K个原数据的分类
- 创建一个字典,用于统计K个数据所属分类的数量
- 使用sorted 方法,对字典进行升序排序,这个方法后面会详细讲一下
- 返回K个数据中,类别数量最多的的那个分类,就是输入数据的分类
五、检测模型精准度
def TestModelPrecision():
dataseturl = 'datasets/datingTestSet2.txt'
datatestLabel,datatestClass = loaddatasets(dataseturl,datatype='test')
datamodelLabel,datamodelClass = loaddatasets(dataseturl,datatype='train')
datatestLabel,_ ,_ = normalized_dataset(datatestLabel)
datamodelLabel,_,_ = normalized_dataset(datamodelLabel)
#print("normalize:",datasetLabel)
num=0
for i in range(len(datatestClass)):
DataClass = KnnClassify(k=3,inputdata=datatestLabel[i],datasetLabel=datamodelLabel,datasetClass=datamodelClass)
print("当前预测所属类为{},实际所属类为{}".format(DataClass,datatestClass[i]))
if(int(DataClass)==int(datatestClass[i])):
num+=1
return 100*num/len(datatestClass)
这里主要用来检测模型精准度,测试数据使用的就是数据集的后100个,精准率能达到96%,效果还不错。
六、输入数据分类
# 输入数据进行分类
def ClassifyResult():
data1 = input("请输入飞行里程数:")
data2 = input("请输入玩游戏时间占比:")
data3 = input("请输入消耗得冰淇淋公升数:")
dataseturl = 'datasets/datingTestSet2.txt'
datamodelLabel,datamodelClass = loaddatasets(dataseturl,datatype='train')
datamodelLabel,max,min = normalized_dataset(datamodelLabel)
inputdata = np.array([data1,data2,data3],dtype='float')
inputdata = (inputdata-min)/(max-min)#处理输入的数据
DataClass = KnnClassify(k=3,inputdata=inputdata,datasetLabel=datamodelLabel,datasetClass=datamodelClass)
print("输出结果是:",DataClass)
在这里,我们可以输入数据,来判断数据的归属
知识点扩展
如何对字典进行排序?
#字典格式
classcount = {'a':2,'b':33,'c':5}
sorted() #这个方法是python自带的一个排序方法,返回值是一个按照升序排序的列表,
#我们来分析下面这个
sorted(classcount.items(),key=operator.itemgetter(1),reverse=True)
classcount.items() 是将字典转化为元组
key=operator.itemgetter(1) 按照元组的第二个值进行排序
reverse=True 默认升序,这个属性设置为true,表示进行降序排列
这里返回值值列表,列表的数据是元组形式。[('a', 2), ('c', 5), ('b', 33)]
结论
KNN算法原理非常简单,非常容易理解,并且代码也很好写。但是往往,越容易理解,越简单的东西,背后就会有一些东西被牺牲,比如计算资源和空间容量。而且KNN算法无法得知数据中的基础结构信息,下一节的决策树会解决这个问题。

