最近在做公司的一个内部项目,其中用到了graphql技术,通过这些天的学习对graphql有了大概的认知,这篇文章算是对graphql的总结,本文主要分以下四部分部分。
graphql简介
什么是Grphql?
GraphQL 是一个用于 API 的查询语言,是一个使用基于类型系统来执行查询的服务端运行时(类型系统由你的数据定义)。它是一个新的API标准,由Facebook开发和开源,提供了比REST更高效、灵活、强大的替代方案。
上述定义是官方文档给出的,看完之后可能一头雾水,api不是服务端定义好供客户端调用的吗?基于API的查询是什么鬼?
传统的服务端会提供很多接口,每个接口对应一个url,接口的返回值是定义好的,客户端被动的接收所有的数据。 例如一个查询患者详情的接口它的返回结果包含了如下的信息:
可以看到这个接口返回的字段非常多,有些字段前端用的到,有些字段对前端来讲完全没用,这就是数据过载的问题,这样会有损应用的性能(需要更长时间下载,解析更多的数据)。
Graphql服务能够很好的解决这个问题,“用于API的查询语言”表明graphql允许客户端向服务端接口发送查询请求,客户端需要什么字段就请求什么字段,graphql服务会以一致的方式返回这些数据。举个例子:有个患者查询的接口,客户端客户端只想查询患者姓名和年龄,用graphql的话只需下面的查询就能得到想要的结果。
query {
patient(id: '1') {
name,
age,
}
}
接口返回结果:
{
data: {
patient: {
name: '张三',
age:25
}
}
}
什么原理呢?
graphql服务是基于类型系统的,服务端会事先定义好schema,schema描述了服务所支持的查询,变更,订阅操作等,graphql服务收到客户端请求后,会逐字段遍历,找到schema中对应的字段,然后执行这个字段的“解析器”,通过解析器获得数据返回给客户端。
下面是一个graphql服务 schema的定义:该graphql服务有一个名称为patient的查询,查询的返回结果的类型是Patient;还有一个addPatient的变更操作,操作返回结果是修改后的患者信息。
// graphql.schema
type Query {
patient(id: String): Patient,
}
type Mutation{
addPatient(name: String, age: Number, phone:String):Patient
}
type Patient{
name: String,
age: Int,
...
}
schema {
query: Query,
}
还是以客户端请求查询患者为例,客户端发送下面的查询请求
query {
patient(id: '1') {
name,
age,
}
}
服务端收到请求后,遍历到patient字段,然后调用patient的解析器,解析器resolver通过读数据库查询数据,或者调用第三方服务返回数据。
graphql服务的执行过程大概是这个样子:
与REST服务对比
-
graphql服务允许客户端选择返回的字段。
它解决了数据过度获取的问题,在实际场景中可能对多端产品的接口复用有一定的帮助。例如公司的产品可能会有web端,安卓,小程序等等,不同的客户端同一功能展示的效果可能不一样。就医生列表页面而言,web端可能需要展示id、姓名、医生类型、而小程序医生列表可能只需要展示姓名、头像、诊疗服务费等。
针对这种情况,服务端要么提供一个返回所有字段的接口供所有客户端调用,要么提供多个接口供不同到客户端调用。然而这两种方式都有他的弊端,第一种方式就会导致过度获取问题,客户端得到了大量无用的数据,这样会有损应用的性能(需要更长时间下载,解析更多的数据)。第二种方式则会造成后期维护成本的增加。而graphq这种基于接口查询的方式能很好的解决这个问题。
-
graphql服务允许客户端只通过一次请求就得到所有需要的数据。
使用REST API,通常会过访问多个接口来收集数据,例如我们中控系统中的耗材详情页面,除了调用接口查询耗材详情信息,还会调接口查询一些枚举下拉框的数据, 如包装单位、税务分类等等。如果用graphql只需调用一次接口就能查询所有的数据
query {
cousumble(id) {
name,
alias,
...
},
// 查询库存单位
units() {
...
},
// 查询分类
category() {
...
}
}
- graphql使用强类型系统定义API,服务支持什么操作都在schema定义好了,schema就相当于服务端和客户端之间的契约,一旦定义好前后端团队便可独立的工作。
- rest服务中,查询数据一般用get请求,添加修改数据一般用post,put请求,删除数据一般用delete请求。而graphql所有的操作都是post请求。
- rest服务中,每一个接口对应一个url,而graphql服务中只有一个url,通常是/graphql。
graphql的几个核心概念
1、Schema和类型
Schema定义了GraphQL API的类型系统,它完整描述了客户端可以访问的所有数据(对象、成员变量、关系、任何类型)。客户端的请求将根据schema进行校验和执行。
graphql有自己的语言来定义schema即SDL(schema definition language)。
2、对象类型
对象类型是 GraphQL schema中的一个最基本的组件,它就表示你可以从服务上获取到什么类型的对象,以及这个对象有什么字段。可以简单把它理解为model的定义,下面是用SDL定义对象类型的例子。
type Person {
name: String!
age: Int!
posts: [Post!]!
}
这样就定义了一个名为Person的对象类型,他有两个字段,字段name和age是标量类型,感叹号表示非空。中括号表示是数组类型,所以posts是个数组类型,且非空,数组中的每一项也不为空。
Person中我们只定义了三个字段,这意味着在一个操作 Person类型的 GraphQL 查询中只能出现 name,age 和 post 字段。
字段的数据类型只有两种可能:要么是标量类型,要么是个对象类型。
标量类型
一个对象类型有自己的名字和字段,而某些时候,这些字段必然会解析到具体数据。这就是标量类型的来源:它们表示对应 GraphQL 查询的叶子节点
graphql的自带的标量类型有5种:Int、Float、String、Boolean,Id。
当然我们也可以自定义新的标量类型,例如定义一个Date类型。
scalar Date
枚举类型
枚举类型是一种特殊的标量,它限制在一个特殊的可选值集合内。这让你能够:
验证这个类型的任何参数是可选值的的某一个
与类型系统沟通,一个字段总是一个有限值集合的其中一个值。
enum Episode {
NEWHOPE
EMPIRE
JEDI
}
3、查询与变更
schema内有两个特殊的类型:Query,Mutation。这两个类型和常规对象类型无差别,它们之所以特殊,是因为它们定义了每一个 GraphQL查询的入口。graphql服务支持的查询操作都定义在Query对象类型中,修改删除操作都定义在Mutation对象类型中。
定义查询
Query类型确切定义了客户端可以针对您的数据图执行哪些GraphQL查询(即读取操作)。它类似于对象类型,但其名称始终为Query。
type Query {
getBooks: [Book]
getAuthors: [Author]
}
此Query类型定义了两个可用的查询:getBooks和getAuthors。
定义变更
type Mutation {
createPost(post: PostAndMediaInput): Post
}
input PostAndMediaInput {
title: String
body: String
mediaUrls: [String]
}
查询可以传递参数,如果参数特别多可以定义一个输入类型,另外graphql的类型系统还支持接口定义等等,更多关于graphql的语法信息可参考官方文档
4、解析器
前面提到的schema只是定义了graphql服务支持的操作,他描述了允许客户端执行哪些查询,可以从服务器上获取哪些类型的数据,以及这些数据之间的关系。服务端收到请求后具体怎么把数据返回给客户端,算法的核心非常简单:逐字段遍历查询,为每个字段执行“解析器”。这篇文章有关于resolver详细执行过程的介绍。
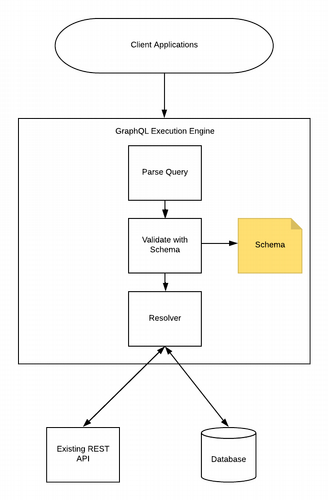
graphql服务常见的三种架构
作为一种服务,最重要的就是对数据的操作,graphql服务可以直接操作数据库包括mysql,mongo等,也可以集成第三方服务或其他微服务。以下是常见的三种架构:
- graphql服务直接读取数据库
- graphql服务仅作为一个代理层,客户端通过这个代理层访问第三方或者旧系统的服务。
这张图有没有很眼熟?是不是和 BFF的理念十分贴合?
- 混合模式,即能访问数据库,又集成了第三方服务或旧系统。
混合模式是将以上两种方法结合起来,构建一个即能连接数据库又与旧系统或第三方系统通信的GraphQL服务器。