MaxCompute
大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案。MaxCompute向用户提供了完善的数据导入方案以及多种经典的分布式计算模型,能够更快速的解决用户海量数据计算问题,有效降低企业成本,并保障数据安全。
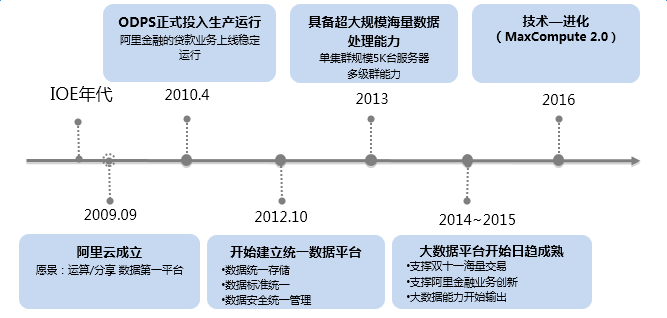
从2009年9月阿里云成立,愿景就是做运算/分享数据的第一平台。2010年4月,伴随阿里金融的贷款业务上线,ODPS正式投入生产运行。2012年建立统一数据平台,2013年具备超大规模海量数据处理能力,2014~2015年大数据平台开始日趋成熟,2016年MaxCompute2.0诞生,成立之初的愿景正在逐步实现。
关键性里程碑
| 时间 | 动态 |
|---|---|
| 2010.04 | ODPS正式投入生产运行,阿里金融的贷款业务上线稳定运行。 |
| 2013.05 | ODPS公测。 |
| 2013.07 | ODPS正式提供商业化服务,单集群规模5K台服务器多级群能力。 |
| 2016.09 | ODPS正式更名为MaxCompute,并推出MaxCompute2.0,实现高性能,新功能,富生态。 |
与其它阿里云服务的集成使用
MaxCompute(原ODPS)是一种大数据计算服务,能提供快速、完全托管的PB级数据仓库解决方案,已经与阿里云部分产品集成,快速实现多种业务场景。
MaxCompute与DataWorks
DataWorks是基于MaxCompute计算和存储,提供工作流可视化开发、调度运维托管的一站式海量数据离线加工分析平台。在数加(一站式大数据平台)中,DataWorks控制台即为MaxCompute控制台。
通过DataWorks,您既可直接编写并运行MaxCompute SQL,又能可视化配置工作流并定时调度运行MaxCompute SQL、MR等任务。更多使用说明请参见DataWorks帮助文档。
说明 您可以将DataWorks理解成MaxCompute的web客户端。
MaxCompute与数据集成
MaxCompute可以通过数据集成加载不同数据源数据,同样也可以通过数据集成把MaxCompute的数据导出到各种业务数据库。
数据集成已经集成到DataWorks作为数据同步任务进行配置、运行。您可直接在DataWorks上配置MaxCompute数据源,再配置读取MaxCompute表或者写入MaxCompute表任务,整个过程只需在一个平台上进行操作。
MaxCompute与机器学习
机器学习是基于MaxCompute的一款机器学习算法平台。数加上创建好MaxCompute项目,开通好机器学习,即可通过机器学习平台的算法组件对MaxCompute数据进行模型训练等操作。详情请参见机器学习操作文档。
MaxCompute与QuickBI
数据在MaxCompute进行加工处理后,将Project添加为QuickBI数据源,即可在QuickBI页面对MaxCompute表数据进行报表制作,实现数据可视化分析。
MaxCompute与AnalyticDB
AnalyticDB是海量数据实时高并发在线分析(Realtime OLAP)的云计算服务,与MaxCompute双剑合璧实现大数据驱动业务系统的场景。通过MaxCompute离线计算挖掘,产出高质量数据后,导入分析型数据库,供业务系统调用分析。
将MaxCompute数据导入到AnalyticDB,有以下两种方式:
- 通过DMS for AnalyticDB的导入导出功能进行配置。
- 通过DataWorks配置数据同步任务,读MaxCompute和写AnalyticDB。
MaxCompute与推荐引擎
推荐引擎是在阿里云计算环境下建立的一套推荐服务框架,推荐服务通常由三部分组成:日志采集、推荐计算和产品对接,而推荐计算的离线计算输入和输出都是MaxCompute(原ODPS)表。
在推荐引擎控制台的资源管理页面,通过添加云计算资源的方式,将MaxCompute项目添加为推荐引擎的计算资源。
MaxCompute与表格存储
表格存储(Table Store)是构建在阿里云飞天分布式系统之上的分布式NoSQL数据存储服务,MaxCompute2.0支持直接通过外部表方式访问表格存储中的表数据并进行处理,详情请参见访问OTS非结构化数据。
MaxCompute与OSS
对象存储OSS是海量、安全、低成本、高可靠的云存储服务,MaxCompute2.0支持直接通过外部表方式访问表格存储中的表数据并进行处理,详情请参见访问OSS非结构化数据。
MaxCompute与OpenSearch
阿里云开放搜索OpenSearch是一款阿里巴巴自主研发的大规模分布式搜索引擎平台。数据通过MaxCompoute进行计算处理后,可以在OpenSearch平台上通过添加数据源的方式将MaxCompute数据接入。
MaxCompute与移动数据分析
移动数据分析(Mobile Analytics)是阿里云推出的一款移动APP数据统计分析产品,为开发者提供一站式数据化运营服务。当移动数据分析自带的基础的分析报表不能满足APP开发者的个性化需求时,可以将数据一键同步至Maxcompute,结合自己的业务需求来进一步加工、分析自己的数据。
MaxCompute与日志服务
日志服务能快速完成数据采集、消费、投递以及查询分析等功能。日志数据采集后,需要更多的个性化分析、挖掘,您可以在日志服务上投递日志到MaxCompute,通过MaxCompute对日志数据进行个性化、深层次的数据分析、挖掘。
MaxCompute与RAM
RAM是阿里云为客户提供的 用户身份管理与 资源访问控制服务。MaxCompute与RAM的集成使用主要有两个场景:
- 通过DataWorks使用MaxCompute时,子账户的身份管理
主帐号开通并创建项目后,若需要通过DataWorks使用MaxCompute且多个账户协同开发,必须由主帐号到RAM服务中创建子账户,将RAM子账户添加为项目成员从而进行协同开发,详情请参见准备RAM子账号、添加工作空间成员和角色。
说明 此时RAM只起到用户身份管理功能,相关的权限管理不在RAM上控制。
- MaxCompute处理非结构化数据时,通过RAM对非结构化数据进行授权
目前MaxCompute支持直接处理非结构化数据(包含OSS和Table Store),前提条件之一就是需要在RAM中授予MaxCompute访问OSS或Table Store的权限,详情请参见访问OSS非结构化数据、访问OTS非结构化数据。
MaxCompute使用准备工作
一、准备阿里云账号
使用MaxCompute服务前,您需要准备一个阿里云账号。
操作步骤
- 注册阿里云账号如果您还没有注册过阿里云账号,请进入阿里云官网,单击 免费注册,即可进入阿里云账号注册页面创建新的阿里云账号。
说明 主账号创建成功后,作为阿里云系统识别的资源消费账号,会拥有该账户的所有权限。 请您尽可能保证账号和密码的安全,切勿借给他人使用,定期更新密码。
- 阿里云账号实名认证
阿里云账号需要进行实名制认证后,才能购买和使用阿里云上的各种产品。如果您还没有实名认证,请进入实名认证页面对账号进行实名认证。为保证后续操作顺利进行,请务必完成实名认证操作。
对于企业级用户,最好可以进行企业级认证,以获取更多的便利。更多详情请参见会员账号&实名制认证。
- 创建运行密钥accesskeys
为了保证您在DataWorks中的任务顺利运行,需要为您创建一个运行密钥。该密钥区别于您登录时填写的账号和密码,主要用于在阿里云各产品间互相认证使用权限。运行密钥AK包括Access Key ID和Access Key Secret两部分。具体操作如下:
- 登录阿里云官网,在右上角的用户名下单击accesskeys进入Access Key管理页面。
- 单击右上角的创建Access Key,单击弹出框中的同意并创建,即可成功创建。如下图所示:
- 成功创建Access Key后,便自动跳转至Access Key管理页面,您可查看相应AK的状态并对其进行禁用、删除等操作。如下图所示:
Accesskeys一旦被禁用,使用该Accesskeys的服务将运行失败并报错,因此如有变更,需要及时关注使用该Accesskeys的产品和服务。说明 账号的accesskeys非常重要,创建成功后,请您尽可能保证Access Key ID和Access Key Secret的安全,切勿让他人知晓,一旦有泄漏的风险,请及时禁用和更新。
- 登录阿里云官网,在右上角的用户名下单击accesskeys进入Access Key管理页面。
- 对于后续需要创建MaxCompute项目的子账号,需要首先创建Access Key,然后绑定Access Key。
下一步
- 开通子账号
如果您需要使用RAM子账号登录数加平台和使用DataWorks,可使用主账号创建RAM子账号。
- 使用主账号创建子账号:DataWorks-admin,生成AK信息并保存好,如图所示。
- 设置子账号可登录控制台,如下图。
-
子帐号授权
如果您需要使用子账号开通MaxCompute和创建项目等操作,请先对子账号进行授权。进入权限管理 > 授权页面,新增授权项,授权对象选择DataWorks-admin子账号,授权策略选择AliyunDataWorksFullAccess或者administrator,如图所示。

说明 子账号创建项目后,对应Project的owner还是主账号,在DataWorks上该子账号是工作空间的管理员角色。
- 使用主账号创建子账号:DataWorks-admin,生成AK信息并保存好,如图所示。
二、开通MaxCompute
如果您是第一次使用数加产品和DataWorks,请使用阿里云账号登录;如果您需要使用RAM子账号登录和创建项目,请根据准备阿里云账号检查账号是否已可用并授权。如果验证无误,请根据下述操作开通MaxCompute服务。
操作步骤
- 使用阿里云账号登录阿里云官网。
- 进入阿里云MaxCompute产品首页,单击立即购买。
- 选择付费方式并单击立即购买。
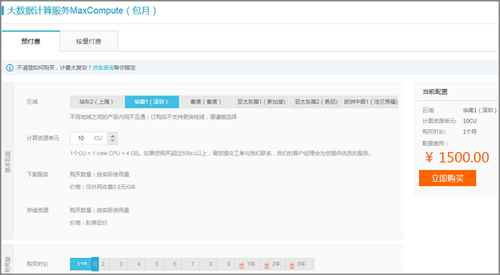
您可根据自身需求进行选择、购买,MaxCompute有按CU预付费和按I/O后付费(按量付费)两种付费方式,详情请参见计量计费说明中的计算计费模块。
如果您选择了 按量付费模式,则可以继续选择规格类型为 标准版或 开发者版。说明- 目前开发者版只支持北京、上海、杭州、深圳4个region。
- 一个region只能有一个项目可使用开发者版的MaxCompute资源,仅新创建的项目可选择开发者版资源。
- 开发者版计费方式与过去的标准版不同,详情请参见计量计费说明。
关于区域的选择,您需要考虑的最主要因素是MaxCompute与其他阿里云产品之间的关系,如ECS在什么区域,数据在什么区域。
- 确认订单后,单击去开通。
跳转至服务开通成功的页面,如下图所示:
开通MaxCompute服务后,您可进行项目的创建,详情请参见创建项目。
三、创建项目
- 登录DataWorks管理控制台,您可通过以下两种方式创建MaxCompute项目。
- 单击控制台概览页面常用功能下的创建工作空间,如下图所示:
说明 创建工作空间即创建MaxCompute项目。
- 导航至控制台工作空间列表页面,单击创建工作空间,如下图所示:
- 单击控制台概览页面常用功能下的创建工作空间,如下图所示:
- 填写创建工作空间弹出框中的各配置项,选择Region及服务,如Region没有购买相关的服务,会直接显示该Region下暂无可用服务,数据开发、运维中心、数据管理默认是选中的。如下图所示:
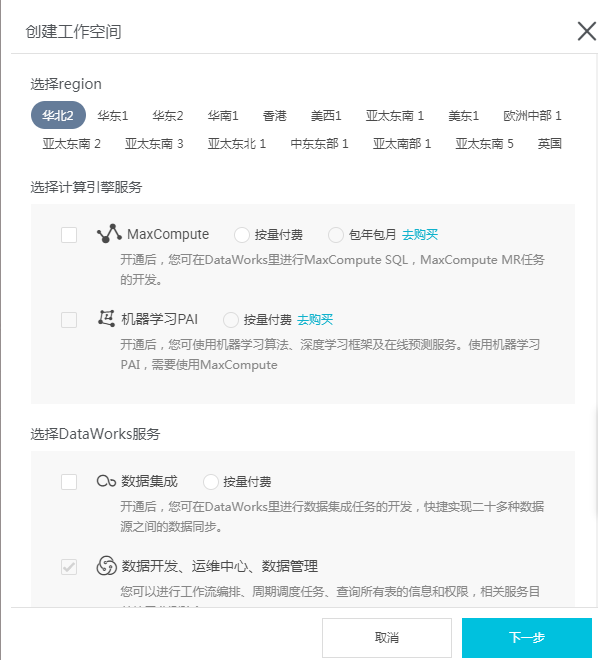
选择计算引擎服务:
- MaxCompute:大数据计算服务(MaxCompute,原名ODPS)是一种快速、完全托管的TB/PB级数据仓库解决方案,能够更快速为您解决海量数据计算问题,有效降低企业成本,并保障数据安全。详情请参见MaxCompute文档。
- 如果您通过DataWorks进行添加用户及授权等操作,请参见添加项目成员和角色。
- 机器学习PAI:机器学习指的是机器通过统计学算法,对大量的历史数据进行学习从而生成经验模型,利用经验模型指导业务。详情请参见机器学习。
选择DataWorks服务:
- 配置新建项目的基本信息和高级设置。
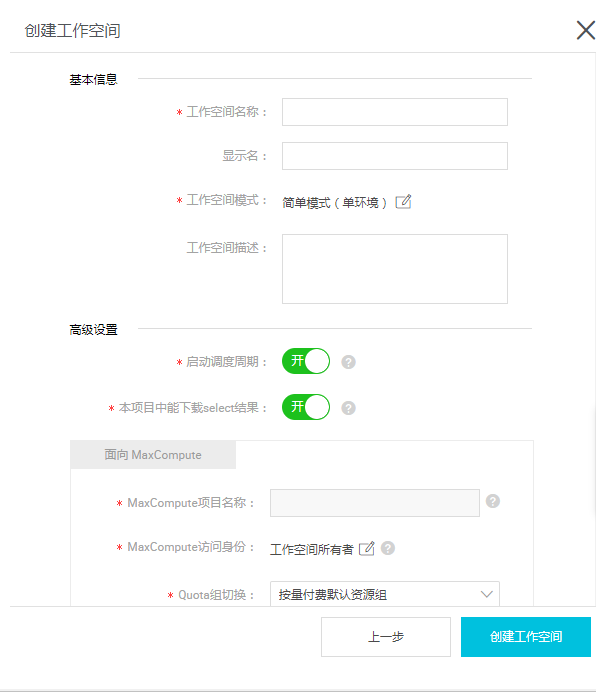
基本配置:
- 项目名:项目名长度需要在3到27个字符之间。
- 显示名:显示名不能超过27个字符。
- 工作空间模式:Dataworks新版本工作空间推出了简单模式和标准模式,详细描述请参见简单模式和标准模式的区别。
高级配置:
- 启用调度周期:控制当前项目是否启用调度系统,如果关闭则无法周期性调度任务。
- 允许在本项目中直接编辑任务和代码:当前项目成员在本项目中新建/编辑代码文件的权限,如果关闭则无法新建/编辑代码文件。
- 本项目中能下载select结果:控制数据开发中select出的数据结果是否能够下载,如果关闭无法下载select的数据查询结果。
- MaxCompute项目名称:创建项目过程中可以创建MaxCompute相同的名称项目。
- MaxCompute访问身份:个人账号,系统账号。推荐安全要求高的企业用户使用个人账号。
- Quota组切换:Quota用来实现磁盘配额。
- 项目创建成功后,您可进入工作空间列表页面查看相应内容。
说明- 您一旦成为项目空间Owner,意味着该项目内所有东西都是您的,在给别人赋权之前,任何人无权限访问您的空间。
- 对于一般用户,并非一定要创建项目空间,只要被加入到某个项目便可使用MaxCompute。
四、安装并配置客户端
您可以通过客户端(odpscmd)访问MaxCompute的项目空间并使用各项功能。本文为您介绍如何安装、配置、运行客户端。
客户端(odpscmd)的具体使用方法请参见客户端介绍。说明
- 推荐您使用MaxCompute Studio工具进行完整的大数据开发流程。该工具集成Java环境,可进行MaxCompute SQL脚本开发/执行、数据管理、可视化分析日志、Java(UDF、MR)开发。客户端(odpscmd)目前也已集成该工具中。
- 您也可以通过DataWorks使用MaxCompute:在控制台中创建项目(工作空间)后,直接点击工作空间列表 > 进入数据开发。
- 使用DataWorks进行添加用户及授权等操作请参见添加工作空间成员和角色。
安装客户端
说明 由于客户端(odpscmd)基于Java开发。在安装前,请确保您的机器上有JRE 1.7或以上版本(建议优先使用JRE 1.7/1.8,其中JRE 1.9已经支持,JRE 1.10暂不支持)。
- Linux用户请点击此处下载MaxCompute客户端(对于Windows或MAC用户,点击此处下载MaxCompute客户端。)
说明 您可以在这里下载到各版本的客户端(odpscmd)工具。
- 解压下载的文件,解压后可以看到如下4个文件夹:
bin/ conf/ lib/ plugins/
配置客户端
编辑conf文件夹中的odps_config.ini文件,对客户端进行配置,如下所示:
access_id=*******************
access_key=*********************
# Accesss ID及Access Key是用户的云账号信息,可登录阿里云官网,进入管理控制台accesskeys页面进行查看。
project_name=my_project # 指定用户想进入的项目空间。
end_point=https://service.odps.aliyun.com/api # MaxCompute服务的访问链接
tunnel_endpoint=https://dt.odps.aliyun.com # MaxCompute Tunnel服务的访问链接
log_view_host=http://logview.odps.aliyun.com
# 当用户执行一个作业后,客户端会返回该作业的LogView地址。打开该地址将会看到作业执行的详细信息。
https_check=true #决定是否开启HTTPS访问说明
- 建议您根据自己的Region配置客户端,否则会出现无法访问等错误。
- odps_config.ini文件中使用#作为注释,MaxCompute客户端内使用两个减号,即--作为注释。
- 您要提前创建好项目空间方可在配置文件中进行指定,详情请参见创建项目空间。
- MaxCompute提供了公网和私网两种服务地址Endpoint供您选择,不同的服务地址对您的下载计费结算有不同影响。如果您不配置Tunnel Endpoint,则Tunnel可能自动路由到公网,从而产生下载费用。
运行客户端
修改好配置文件后,便可运行bin目录下的MaxCompute(Linux系统下运行./bin/odpscmd,Windows下运行./bin/odpscmd.bat),示例如下:
create table tbl1(id bigint);
insert overwrite table tbl1 select count(*) from tbl1;
select 'welcome to MaxCompute!' from tbl1;更多SQL语句的介绍请参见SQL概述。
五、用户及角色管理
当用户申请创建项目空间后,该用户即是此空间的所有者(Owner),这个项目空间内的所有对象(表,实例,资源,UDF等)都属于该用户。这就是说,除了Owner之外,任何人都无权访问此项目空间内的对象,除非有Owner的授权许可。本文同时为您提供MaxCompute和Dataworks中,主账号与子账号的权限区分表。
项目空间(Project)是MaxCompute实现多租户体系的基础,是您管理数据和计算的基本单位,也是计量和计费的主体。说明 对于已在MaxCompute或DateWorks项目中拥有角色的RAM子账号,请在删除子账号之前解除子账号在项目的角色并在项目空间中删除子账号。否则子账号会在项目空间中残留,显示为“ p4_ xxxxxxxxxxxxxxxxxxxx”且无法在项目空间中移除(不影响项目空间正常功能使用)。示例如下:
子账号残留时在项目的显示:
odps@ MaxCompute>list users;
p4_2652900xxxxxxxxxx
残留子账号无法在空间中删除:
odps@ MaxCompute_DOC>remove user p4_2652900xxxxxxxxxx;
Confirm to "remove user p4_2652900xxxxxxxxxx
;" (yes/no)? yes
FAILED: lack of account provider
在此时在Dataworks项目成员管理页面依然能看到RAM子账号。
正确的做法:在删除子账号前先解除子账号的角色
odps@ MaxCompute>revoke role_project_security, role_project_admin, role_project_dev, role_project_pe, role_project_deploy, role_project_guest from RAM$MainCount:hanmeimei;
OK
然后在空间移除子账号:
odps@ MaxCompute>remove user RAM$MainCount:hanmeimei;
之后即可正常删除RAM子账号。
在MaxCompute和Dataworks中,主账号与子账号的权限区分如下表所示。
| 操作类型 | 操作说明 | 操作端 | 主账号 | 角色 | RAM子账号 | 角色 | 依赖 |
| Project管理 | Project-创建、删除 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员 | 主账号AK开启 |
| Project-创建、删除 | MaxCompute CLI/Studio | 不支持 | N/A | 不支持 | N/A | ||
| Project-跨Project访问 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | ALL | 主账号指定授权 | |
| Project-更新 | Dataworks/MaxCompute CLI/Studio | 不支持 | N/A | 不支持 | N/A | ||
| IP白名单设置 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 不支持 | N/A | 主账号AK开启 | |
| 全表扫描 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 不支持 | N/A | 主账号AK开启 | |
| 数据保护 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 不支持 | N/A | 主账号AK开启 | |
| 项目成员-添加、授权管理 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员 | 主账号AK开启 | |
| 项目成员-添加、授权管理 | MaxCompute CLI/Studio | 不支持 | N/A | 不支持 | N/A | ||
| 数据集成 | 数据源创建、修改 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员 | |
| 同步任务创建、修改 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 同步任务发布 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员、开发、运维、部署 | ||
| CU管家 | CU管家-修改Quota | Dataworks | 支持 | 项目所有者 | 不支持 | N/A | 主账号AK开启 |
| CU管家-访问、监控 | Dataworks | 支持 | 项目所有者 | 支持 | ALL | ||
| CU管家-RAM授权 | Dataworks | 不支持 | N/A | 不支持 | N/A | ||
| 代码开发 | 查看代码列表、内容 | Dataworks | 支持 | 项目所有者 | 支持 | ALL | |
| 代码创建、删除、更新、运行 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| JAVA UDF | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发、运维、部署 | ||
| Python UDF | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发、运维、部署 | 工单申请开通 | |
| 运维中心 | 调度任务查看管理 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员、开发、运维、部署 | |
| 数据管理 | 表-创建 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | |
| 表-更新 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发、运维、部署 | ||
| 表-删除 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 单表授权(ACL) | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 表查询-元数据预览 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | ALL | ||
| 表查询-跨Project表预览 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | ALL | 主账号指定授权 | |
| 资源管理 | 查看资源列表 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | ALL | |
| 资源-创建、删除 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 资源-上传(jar/text/archive) | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 工作流开发 | 查看工作流列表、内容 | Dataworks | 支持 | 项目所有者 | 支持 | ALL | |
| 工作流创建、删除、更新 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 文件夹创建、删除、更新 | Dataworks | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 函数开发 | 查看函数列表、详情 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | ALL | |
| 函数-创建、删除 | Dataworks/MaxCompute CLI/Studio | 支持 | 项目所有者 | 支持 | 项目管理员、开发 | ||
| 售卖 | 购买、充值、续费、升级、降配 | 数加控制台/MaxCompute购买页 | 支持 | 项目所有者 | 不支持 | N/A | |
| 消费账单、消费明细、使用记录 | 阿里云费用中心 | 支持 | 项目所有者 | 不支持 | N/A |
- 如果您通过DataWorks进行添加用户及授权等操作,请参见添加项目成员和角色。
- 如果您通过MaxCompute安全管理命令进行用户管理,请参见用户管理,以了解如何添加/删除用户、给用户授权(包括RAM子账号管理)。
- 如果您通过MaxCompute安全管理命令进行角色管理,请参见角色管理,以了解如何创建/删除角色,如何给角色授权。
- 授权及权限查看的更多详情,请参见授权和查看权限。
六、配置Endpoint
本文将为您介绍MaxCompute Region的开通情况和连接方式,解答您在与其他云产品(ECS、TableStore、OSS)互访场景中遇到的网络连通性和下载数据收费等问题。
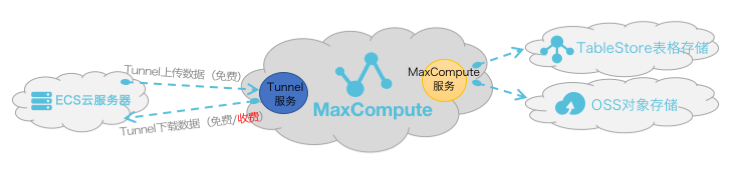
由上图可知,从服务层面来看,MaxCompute为您提供了两大类服务连接地址,如下所示:
- MaxCompute服务本身的连接地址:您可以向MaxCompute发出除数据上传、下载外的所有请求,例如创建表、删除某个函数、创建一个作业等。
- MaxCompute Tunnel服务的连接地址:上传、下载数据的能力是通过MaxCompute Tunnel服务提供的。当您想通过Tunnel上传、下载数据时,可以通过Tunnel提供的链接地址发起请求。说明
- 由于各Region部署和网络连接状况不一致,在Tunnel数据的下载计费规则上也不统一。
- 如果您不配置Tunnel Endpoint,则Tunnel可能自动路由到公网,从而产生下载费用。
访问来源及下载数据收费规则说明
从阿里云各Region部署及网络情况来看,通常情况下分为三种连接方式,如下所示:
- 从外网访问MaxCompute服务和Tunnel服务。
- 从阿里云经典网络访问MaxCompute服务和Tunnel服务。
- 从阿里云VPC网络访问MaxCompute服务和Tunnel服务。
说明 创建MaxCompute的项目时无需指定网络,只在连接项目时才需指定通过什么网络进行连接。
数据上传
Tunnel数据上传无论走哪一种网络形态都免费,如上文示意图所示。
数据下载
您无论是在ECS云服务器的哪一个Region上进行Tunnel服务请求进行下载数据,网络连通性设置都需满足如下形态定义。
- 两者在同一Region内,Tunnel下载请求走阿里云经典网络/VPC网络都免费。
说明 此时必须配置经典网络/VPC类型的Tunnel Endpoint ,否则数据会路由到外网进行跨Region下载,产生费用。
- 两者不在同一Region内或没有条件满足同Region访问,则需走外网跨Region访问请求,此条件下的数据下载将会进行计费。
说明 由于阿里云数据中心各个Region部署和网络情况不一致,若您选择通过阿里云经典网络/VPC网络进行跨Region的访问,则MaxCompute产品方不承诺、不保证其永久连通性。
MaxCompute访问外部表的连通性
MaxCompute2.0支持读写OSS对象存储数据,同时也支持读写TableStore表格存储数据,详情请参见访问OSS非结构化数据和访问OTS非结构化数据。
网络连通性的配置说明,如下所示:
- MaxCompute和TableStore/OSS在同一Region情况下,建议配置阿里云经典网络或VPC网络连接方式,其外网也可以进行连通。
- MaxCompute和TableStore/OSS不在同一Region情况下,配置外网访问方式进行连通。在跨Region的情况下,您可选择配置阿里云经典网络或VPC网络则不保证其连通性。
- 对于通过物理专线访问VPC的场景,请参见通过物理专线访问VPC中的云服务保证网络连通性。
MaxCompute开通Region和服务连接对照表
从Region部署情况来看,MaxCompute目前国内国外陆续开服,您可以申请使用对应区域的MaxCompute,您的数据存储和计算消耗均发生在开通使用的区域。
说明 公网Endpoint域名(aliyun)支持http和https,若需要请求加密,请用https。内网Endpoint域名(aliyun-inc)仅支持http,不支持https访问。
- 外网网络下Region和服务连接对照表
Region名称 所在城市 开服状态 外网Endpoint 外网Tunnel Endpoint 华东1 杭州 已开服 http://service.cn.maxcompute.aliyun.com/api http://dt.cn-hangzhou.maxcompute.aliyun.com 华东2 上海 已开服 http://service.cn.maxcompute.aliyun.com/api http://dt.cn-shanghai.maxcompute.aliyun.com 华北2 北京 已开服 http://service.cn.maxcompute.aliyun.com/api http://dt.cn-beijing.maxcompute.aliyun.com 华北2政务云 北京 已开服 http://service.cn-north-2-gov-1.maxcompute.aliyun.com/api http://dt.cn-north-2-gov-1.maxcompute.aliyun.com 华南1 深圳 已开服 http://service.cn.maxcompute.aliyun.com/api http://dt.cn-shenzhen.maxcompute.aliyun.com 香港 香港 已开服 http://service.cn-hongkong.maxcompute.aliyun.com/api http://dt.cn-hongkong.maxcompute.aliyun.com 亚太东南1 新加坡 已开服 http://service.ap-southeast-1.maxcompute.aliyun.com/api http://dt.ap-southeast-1.maxcompute.aliyun.com 亚太东南2 悉尼 已开服 http://service.ap-southeast-2.maxcompute.aliyun.com/api http://dt.ap-southeast-2.maxcompute.aliyun.com 亚太东南3 吉隆坡 已开服 http://service.ap-southeast-3.maxcompute.aliyun.com/api http://dt.ap-southeast-3.maxcompute.aliyun.com 亚太东南5 雅加达 已开服 http://service.ap-southeast-5.maxcompute.aliyun.com/api http://dt.ap-southeast-5.maxcompute.aliyun.com 亚太东北1 东京 已开服 http://service.ap-northeast-1.maxcompute.aliyun.com/api http://dt.ap-northeast-1.maxcompute.aliyun.com 欧洲中部1 法兰克福 已开服 http://service.eu-central-1.maxcompute.aliyun.com/api http://dt.eu-central-1.maxcompute.aliyun.com 美国西部1 硅谷 已开服 http://service.us-west-1.maxcompute.aliyun.com/api http://dt.us-west-1.maxcompute.aliyun.com 美国东部1 弗吉尼亚 已开服 http://service.us-east-1.maxcompute.aliyun.com/api http://dt.us-east-1.maxcompute.aliyun.com 亚太南部1 孟买 已开服 http://service.ap-south-1.maxcompute.aliyun.com/api http://dt.ap-south-1.maxcompute.aliyun.com 中东东部1 迪拜 已开服 http://service.me-east-1.maxcompute.aliyun.com/api http://dt.me-east-1.maxcompute.aliyun.com 英国 伦敦 已开服 http://service.eu-west-1.maxcompute.aliyun.com/api http://dt.eu-west-1.maxcompute.aliyun.com - 经典网络下Region和服务连接对照表
Region名称 所在城市 开服状态 经典网络Endpoint 经典网络Tunnel Endpoint 华东1 杭州 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-hangzhou.maxcompute.aliyun-inc.com 华东2 上海 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-shanghai.maxcompute.aliyun-inc.com 华北2 北京 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-beijing.maxcompute.aliyun-inc.com 华北2政务云 北京 已开服 http://service.cn-north-2-gov-1-all.maxcompute.aliyun-inc.com/api http://dt.cn-north-2-gov-1-all.maxcompute.aliyun-inc.com 华南1 深圳 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-shenzhen.maxcompute.aliyun-inc.com 香港 香港 已开服 http://service.cn-hongkong.maxcompute.aliyun-inc.com/api http://dt.cn-hongkong.maxcompute.aliyun-inc.com 亚太东南1 新加坡 已开服 http://service.ap-southeast-1.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-1.maxcompute.aliyun-inc.com 亚太东南2 悉尼 已开服 http://service.ap-southeast-2.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-2.maxcompute.aliyun-inc.com 亚太东南3 吉隆坡 已开服 http://service.ap-southeast-3.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-3.maxcompute.aliyun-inc.com 亚太东南5 雅加达 已开服 http://service.ap-southeast-5.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-5.maxcompute.aliyun-inc.com 亚太东北1 东京 已开服 http://service.ap-northeast-1.maxcompute.aliyun-inc.com/api http://dt.ap-northeast-1.maxcompute.aliyun-inc.com 欧洲中部1 法兰克福 已开服 http://service.eu-central-1.maxcompute.aliyun-inc.com/api http://dt.eu-central-1.maxcompute.aliyun-inc.com 美国西部1 硅谷 已开服 http://service.us-west-1.maxcompute.aliyun-inc.com/api http://dt.us-west-1.maxcompute.aliyun-inc.com 美国东部1 弗吉尼亚 已开服 http://service.us-east-1.maxcompute.aliyun-inc.com/api http://dt.us-east-1.maxcompute.aliyun-inc.com 亚太南部1 孟买 已开服 http://service.ap-south-1.maxcompute.aliyun-inc.com/api http://dt.ap-south-1.maxcompute.aliyun-inc.com 中东东部1 迪拜 已开服 http://service.me-east-1.maxcompute.aliyun-inc.com/api http://dt.me-east-1.maxcompute.aliyun-inc.com 英国 伦敦 已开服 http://service.uk-all.maxcompute.aliyun-inc.com/api http://dt.uk-all.maxcompute.aliyun-inc.com - VPC网络下Region和服务连接对照表在VPC网络下访问MaxCompute,只能使用如下Endpoint和Tunnel Endpoint。
Region名称 所在城市 开服状态 VPC网络Endpoint VPC网络Tunnel Endpoint 华东1 杭州 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-hangzhou.maxcompute.aliyun-inc.com 华东2 上海 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-shanghai.maxcompute.aliyun-inc.com 华北2 北京 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-beijing.maxcompute.aliyun-inc.com 华北2政务云 北京 已开服 http://service.cn-north-2-gov-1-all.maxcompute.aliyun-inc.com/api http://dt.cn-north-2-gov-1-all.maxcompute.aliyun-inc.com 华南1 深圳 已开服 http://service.cn.maxcompute.aliyun-inc.com/api http://dt.cn-shenzhen.maxcompute.aliyun-inc.com 香港 香港 已开服 http://service.cn-hongkong.maxcompute.aliyun-inc.com/api http://dt.cn-hongkong.maxcompute.aliyun-inc.com 亚太东南1 新加坡 已开服 http://service.ap-southeast-1.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-1.maxcompute.aliyun-inc.com 亚太东南2 悉尼 已开服 http://service.ap-southeast-2.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-2.maxcompute.aliyun-inc.com 亚太东南3 吉隆坡 已开服 http://service.ap-southeast-3.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-3.maxcompute.aliyun-inc.com 亚太东南5 雅加达 已开服 http://service.ap-southeast-5.maxcompute.aliyun-inc.com/api http://dt.ap-southeast-5.maxcompute.aliyun-inc.com 亚太东北1 东京 已开服 http://service.ap-northeast-1.maxcompute.aliyun-inc.com/api http://dt.ap-northeast-1.maxcompute.aliyun-inc.com 欧洲中部1 法兰克福 已开服 http://service.eu-central-1.maxcompute.aliyun-inc.com/api http://dt.eu-central-1.maxcompute.aliyun-inc.com 美国西部1 硅谷 已开服 http://service.us-west-1.maxcompute.aliyun-inc.com/api http://dt.us-west-1.maxcompute.aliyun-inc.com 美国东部1 弗吉尼亚 已开服 http://service.us-east-1.maxcompute.aliyun-inc.com/api http://dt.us-east-1.maxcompute.aliyun-inc.com 亚太南部1 孟买 已开服 http://service.ap-south-1.maxcompute.aliyun-inc.com/api http://dt.ap-south-1.maxcompute.aliyun-inc.com 中东东部1 迪拜 已开服 http://service.me-east-1.maxcompute.aliyun-inc.com/api http://dt.me-east-1.maxcompute.aliyun-inc.com 英国 伦敦 已开服 http://service.uk-all.maxcompute.aliyun-inc.com/api http://dt.uk-all.maxcompute.aliyun-inc.com
说明 需要配置Endpoint、Tunnel Endpoint的场景:
- MaxCompute客户端(console)配置。请参见安装并配置客户端。
- MaxCompute studio project连接配置。请参见项目空间连接管理。
- SDK连接MaxCompute配置。请参见Java SDK和Python SDK连接MaxCompute接口配置。
- PyODPS创建MaxCompute入口对象、通用配置、数据上传下载配置。请参见配置选项。
- DataWorks的数据集成脚本模式连接MaxCompute数据源配置和使用DataX开源工具连接MaxCompute数据源。请参见配置MaxCompute数据源和导出SQL的运行结果。
访问原则
- 对于已开服的Region,您可以通过公网、经典网络、VPC网络方式连接MaxCompute服务。
- 通过配置外网Tunnel Endpoint地址下载数据进行收费,价格为0.8元/GB。
MaxCompute快速入门
当您完成阿里云账号开通、MaxCompute项目购买,被添加到项目空间并被赋予建表等权限,在本地完成客户端的配置后即可操作MaxCompute。本文将为您演示一个完整的使用MaxCompute进行银行贷款购房人员分析的过程,您可以参考每个步骤的示例部分进行实际操作。
说明 如果您是第一次使用MaxCompute,在您快速入门之前,请务必完成所有的准备工作。
快速入门系列文档后续将着重介绍使用客户端配合MaxCompute Studio完成表的创建、数据的上传、加工及导出。您也可以使用DataWorks完成上述整个过程,详情参见DataWorks快速入门。
由于在MaxCompute中的操作对象(输入、输出)都是表,所以在处理数据之前,首先要创建表、分区。创建、查看或删除表的方式有以下几种,本文将为您介绍如何使用 客户端创建、查看表:
- 通过客户端常用命令实现。
- 通过MaxCompute Studio实现,详情请参见可视化创建/修改/删除表。
- 通过DataWorks实现,详情请参见创建表和删除表。
步骤一:创建表
登录客户端之后,使用如下建表语句创建表。
CREATE TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[LIFECYCLE days]
[AS select_statement]
CREATE TABLE [IF NOT EXISTS] table_name
LIKE existing_table_name说明 创建表的详细介绍请参见表操作。
登录MaxCompute客户端后,首先您需要确认当前是否在正确的项目中,本例中项目名称为MaxCompute_DOC,您可以使用 use MaxCompute_DOC;命令切换到该项目(项目需要您提前创建)。
本文中,表bank_data用于存储业务数据,表result_table用于存储数据分析后产生的结果。
bank_data建表语句如下所示:
CREATE TABLE IF NOT EXISTS bank_data
(
age BIGINT COMMENT '年龄',
job STRING COMMENT '工作类型',
marital STRING COMMENT '婚否',
education STRING COMMENT '教育程度',
default STRING COMMENT '是否有信用卡',
housing STRING COMMENT '房贷',
loan STRING COMMENT '贷款',
contact STRING COMMENT '联系途径',
month STRING COMMENT '月份',
day_of_week STRING COMMENT '星期几',
duration STRING COMMENT '持续时间',
campaign BIGINT COMMENT '本次活动联系的次数',
pdays DOUBLE COMMENT '与上一次联系的时间间隔',
previous DOUBLE COMMENT '之前与客户联系的次数',
poutcome STRING COMMENT '之前市场活动的结果',
emp_var_rate DOUBLE COMMENT '就业变化速率',
cons_price_idx DOUBLE COMMENT '消费者物价指数',
cons_conf_idx DOUBLE COMMENT '消费者信心指数',
euribor3m DOUBLE COMMENT '欧元存款利率',
nr_employed DOUBLE COMMENT '职工人数',
y BIGINT COMMENT '是否有定期存款'
);直接运行上述建表语句即可,成功后您会看到 OK字样。
result_table建表语句如下所示:
CREATE TABLE IF NOT EXISTS result_table
(
education STRING COMMENT '教育程度',
num BIGINT COMMENT '人数'
);查看表
当创建表成功之后,您可以通过desc <table_name>;命令查看表的信息。
您可执行命令desc bank_data;查看上述示例中bank_data表的信息。
结果显示如下图所示。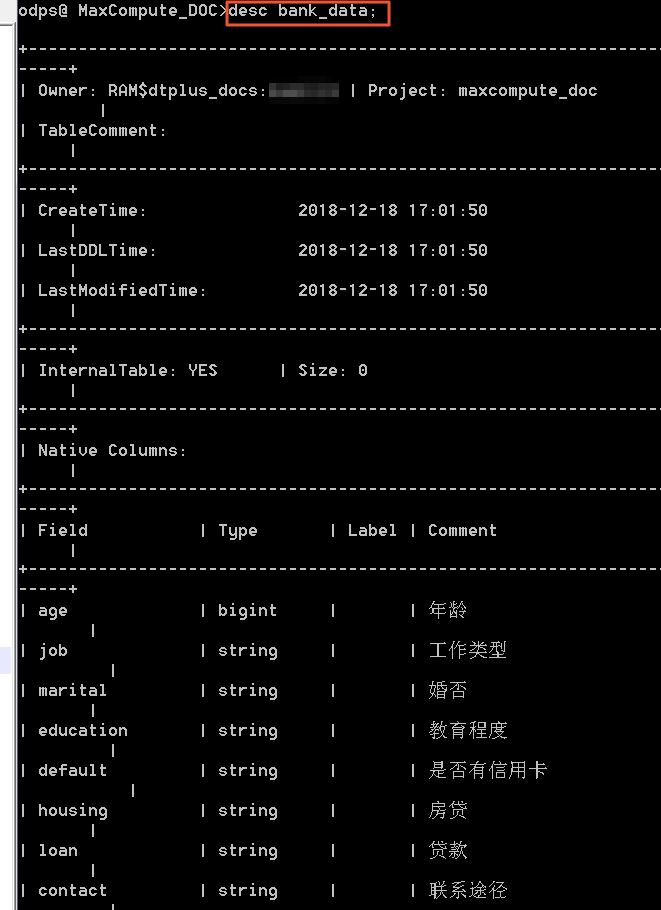
查看表信息的更多详情请参见表操作。
创建分区(可选)
本例中使用的是非分区表。
如果您创建的是分区表,为了往该表里使用Tunnel命令导入不同分区数据,您首先需要创建分区。命令如下:
alter table table_name add [if not exists] partition(partition_col1 = partition_col_value1, partition_col2 = partiton_col_value2, ...);其他操作例如使用数据集成、insert等无需单独创建分区。
删除分区(可选)
删除分区的命令如下所示:
alter table table_name drop [if exists] partition(partition_col1 = partition_col_value1, partition_col2 = partiton_col_value2, ...);例如删除区域为hangzhou,日期为20180923的分区,语句如下所示:
alter table user drop if exists partition(region='hangzhou',dt='20180923');删除表(可选)
删除表的命令如下所示:
DROP TABLE [IF EXISTS] table_name;更多详情请参见表操作。
在您完成表格的创建后,就可以使用Tunnel命令导入数据到MaxCompute了。
MaxCompute提供多种数据导入导出方式,本文主要介绍在客户端上使用Tunnel命令操作进行数据导入。
步骤二:Tunnel命令导入数据
- 准备数据本文中使用的测试数据为bank.txt,主要用于记录各人员的年龄、工作、房贷等信息,请点击下载数据到您的电脑本地。选取其中前三条数据展示如下。
44,blue-collar,married,basic.4y,unknown,yes,no,cellular,aug,thu,210,1,999,0,nonexistent,1.4,93.444,-36.1,4.963,5228.1,0 53,technician,married,unknown,no,no,no,cellular,nov,fri,138,1,999,0,nonexistent,-0.1,93.2,-42,4.021,5195.8,0 28,management,single,university.degree,no,yes,no,cellular,jun,thu,339,3,6,2,success,-1.7,94.055,-39.8,0.729,4991.6,1本文中,bank.txt本地存放路径为D:\。
- 创建MaxCompute表
您需要把上面的数据导入到MaxCompute的一张表中,所以需要创建MaxCompute表,如果您已完成步骤一创建bank_data表,可跳过本步骤。
- 执行Tunnel命令输入表创建成功后,可以在MaxCompute客户端输入Tunnel命令进行数据的导入,如下所示:
当出现下图中 OK字样,说明上传成功。tunnel upload D:\banking.txt bank_data;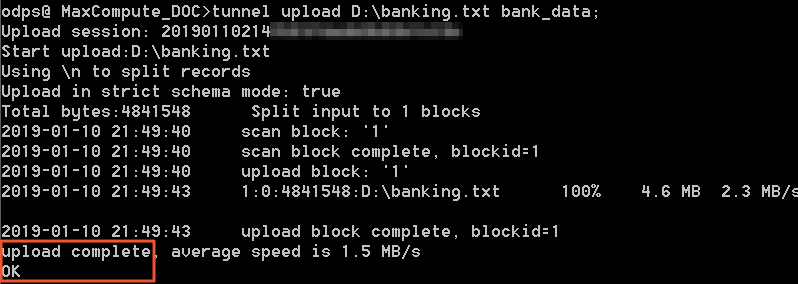
- 结果验证执行成功后,您可以使用
select count(*) from bank_data;查看表bank_data的记录数,验证是否完成所有数据上传,本文中共有41188条数据。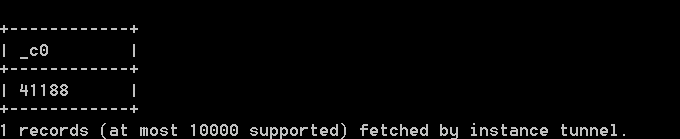
说明- 有关Tunnel命令的更多详细介绍,例如如何将数据导入分区表等,请参见Tunnel操作。
- 使用Tunnel上传数据如果出现问题,请参考Tunnel命令相关问题
其他导入方式
除了通过客户端导入数据,您也可以使用MaxCompute Studio、Tunnel SDK、数据集成、开源的Sqoop、Fluentd、Flume、LogStash 等工具都可以进行数据导入到MaxCompute,详情请参见数据上传下载-工具介绍。
步骤三:运行SQL和导出数据
在您的数据导入到MaxCompute后,即可在MaxCompute上运行SQL来处理数据。
您可以选择在MaxCompute客户端或DataWorks上运行SQL语句,本文为您演示如何使用客户端完成SQL查询、写入等过程。
MaxCompute当前支持的SQL语法:
- 支持各类运算符。
- 通过DDL语句对表、分区以及视图进行管理。
- 通过Select语句查询表中的记录,通过Where语句过滤表中的记录。
- 通过Insert语句插入数据、更新数据。
- 通过等值连接Join操作,支持两张表的关联,并支持多张小表的Mapjoin。
- 支持通过内置函数和自定义函数来进行计算。
- 支持正则表达式。
说明
- MaxCompute SQL不支持事务、索引及Update/Delete等操作,同时MaxCompute的SQL语法与Oracle,MySQL有一定差别,您无法将其他数据库中的SQL语句无缝迁移到MaxCompute上来,更多差异请参见与其他SQL语法的差异。
- 关于SQL操作的详细示例,请参见SQL模块。
- 在使用方式上,MaxCompute作业提交后会有几十秒到数分钟不等的排队调度,所以适合处理跑批作业,一次作业批量处理海量数据,不适合直接对接需要每秒处理几千至数万笔事务的前台业务系统。作业的优化请参见SQL优化示例。
- MaxCompute SQL的更多限制请参见SQL限制项汇总。
提取和分析数据
用SQL代码查询不同学历的单身人士贷款买房的数量,并将结果保存下到result_table以便分析或展现。
INSERT OVERWRITE TABLE result_table --数据插入到result_table中
SELECT education,COUNT(marital) AS num
FROM bank_data
WHERE housing = 'yes'
AND marital = 'single'
GROUP BY education;您可以使用 select * from result_table;查看result_table表中的数据,如下图所示,可以看到当前受到各阶段教育的单身人士数量。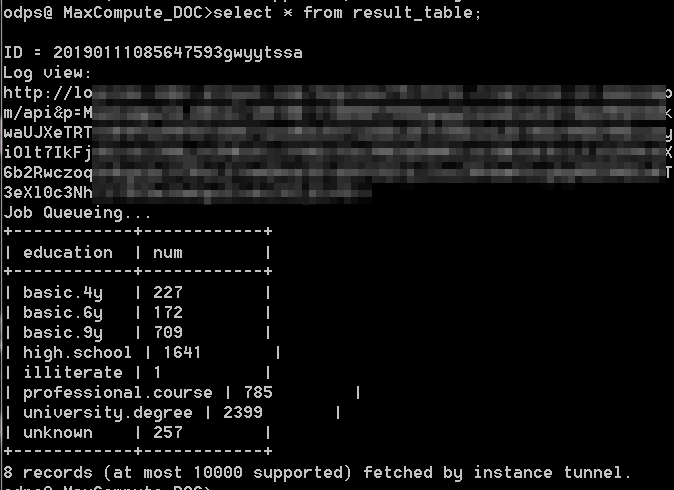
上述过程仅仅是一个最简单的数据加工举例,您在实际应用的过程中,可能需要使用多个SQL对多个表进行加工操作。推荐您使用DataWorks完成复杂的数据加工业务流程。
导出数据
您在完成SQL语句处理后,可以参考Tunnel命令操作将处理完的数据导出到本地。本例中,将result_table中数据导出到本地D盘。
tunnel download result_table D:\result.txt;导出成功后如下图所示,可以看到 download OK字样。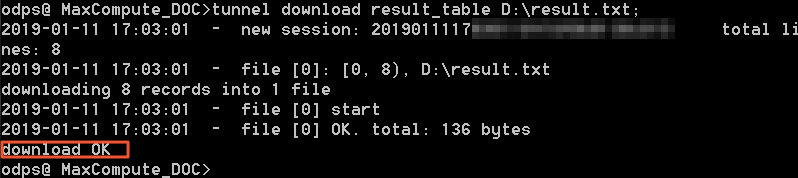
说明 如果您需要将数据导出到MySQL或其他数据源,推荐您使用数据集成。
编写MapReduce(可选)
本文将为您介绍安装好MaxCompute客户端后,如何快速编写和运行MapReduce WordCount示例程序。
说明 如果您使用Maven,可以从Maven 库中搜索odps-sdk-mapred获取不同版本的Java SDK。相关配置信息如下所示:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-mapred</artifactId>
<version>0.26.2-public</version>
</dependency>前提条件
- 编写、编译、运行MapReduce前,需要首先安装JDK1.6或以上版本。
- 请参见安装并配置客户端对MaxCompute客户端进行部署。更多关于MaxCompute客户端的使用,请参见MaxCompute客户端。
操作步骤
- 安装并配置好客户端后,打开odpscmd.bat,进入相应项目空间中。
- 输入建表语句,创建输入和输出表。如下所示:
CREATE TABLE wc_in (key STRING, value STRING); CREATE TABLE wc_out (key STRING, cnt BIGINT); -- 创建输入、输出表更多创建表的语句请参见创建表。
- 上传数据您可以通过以下两种方式上传数据。
- 开发MapReduce程序并上传MaxCompute
MaxCompute为您提供了便捷的Eclipse开发插件,方便您快速开发MapReduce程序,并提供了本地调试MapReduce的功能。您也可以使用MaxCompute Studio进行MapReduce程序开发,本文以Eclipse举例。
您需要先在Eclipse中创建一个项目工程,而后在此工程中编写MapReduce程序。本地调试通过后,将编译好的程序(Jar 包,如Word-count-1.0.jar)导出并上传至MaxCompute。详情请参见MapReduce开发插件介绍。
- 添加Jar包到project资源(比如这里的Jar包名为word-count-1.0.jar)。
add jar word-count-1.0.jar; - 在MaxCompute客户端运行Jar命令。
jar -resources word-count-1.0.jar -classpath /home/resources/word-count-1.0.jar com.taobao.jingfan.WordCount wc_in wc_out; - 在MaxCompute客户端查看结果。
select * from wc_out;说明 如果您在 Java 程序中使用了任何资源,请务必将此资源加入 -resources参数。Jar命令的详细介绍请参见作业提交 。
JAVA UDF开发(可选)
MaxCompute的UDF包括UDF、UDAF和UDTF三种函数。通常情况下,这三种函数被统称为UDF。
说明 当前MaxCompute已支持JAVA UDF、Python UDF、UDJ、UDT,详细信息可参见JAVA UDF。
实现JAVA UDF使用Maven的用户可以从Maven库中搜索 odps-sdk-udf获取不同版本的Java SDK,相关配置信息举例如下所示:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-udf</artifactId>
<version>0.20.7</version>
</dependency>通常情况下,JAVA UDF的开发可以通过以下几种方式:
- 使用MaxCompute Studio完成JAVA UDF开发整个流程。
- 使用Eclipse插件开发和调试JAVA UDF,导出Jar包,然后通过命令或者DataWorks添加资源后再注册函数。
本文中会分别给出UDF、UDAF、UDTF的代码示例,并通过两种方式给出开发UDF完整流程步骤示例(UDAF、UDTF操作步骤与UDF操作步骤一样)。说明
UDF示例
下面将为您介绍一个字符小写转换功能的UDF实现示例。
- 使用MaxCompute Studio开发
- 准备工具环境并创建Java Module。
这里假设已经完成环境准备,包括安装Studio并在Studio上创建MaxCompute项目链接以及创建MaxCompute Java Module。
- 编写代码。
在配置好的Java Module下创建Java文件。
直接选择MaxCompute Java,然后在name一栏里输入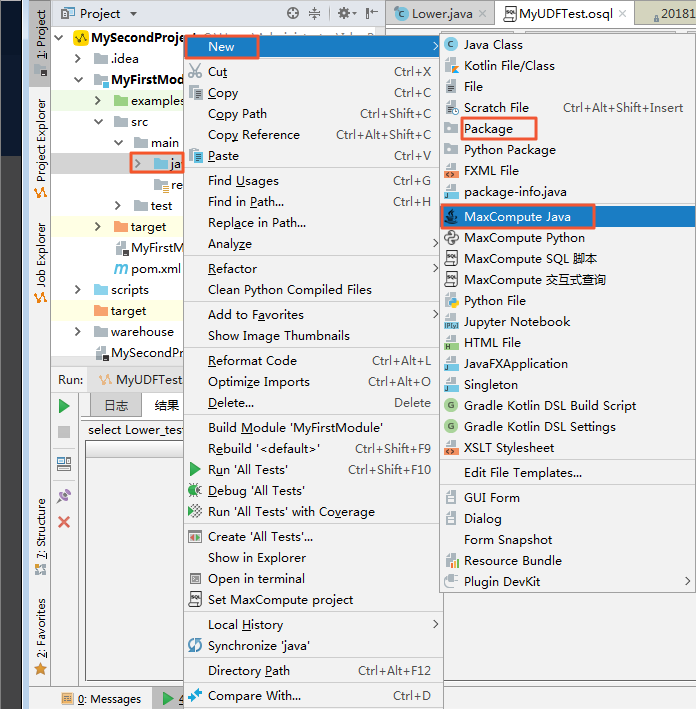
package名称.文件名,Kind选择UDF。 之后编辑如下代码:package <package名称>; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } }说明 若需本地调试Java UDF,请参见开发和调试UDF
- 注册MaxCompute UDF。
如下图所示,右键单击UDF的Java文件,选择 Deploy to server,弹框里选择注册到那个MaxCompute project,输入
function name,Resource name也可以修改。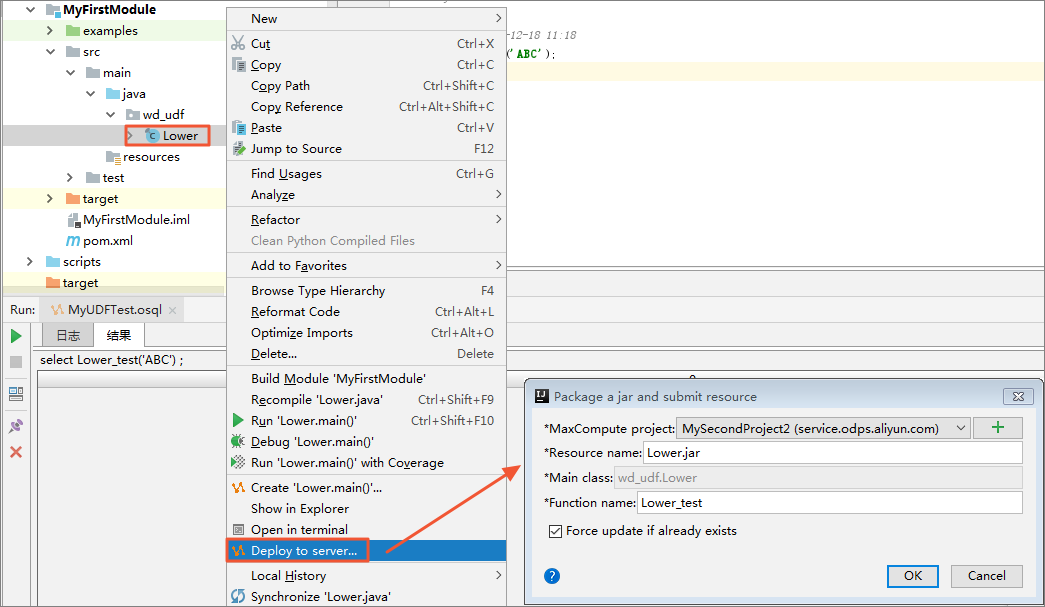
填写好后,单击 OK即可。注册成功后会有提示。 - 试用UDF。打开SQL脚本,执行代码如
select Lower_test(‘ABC’);结果如下图所示: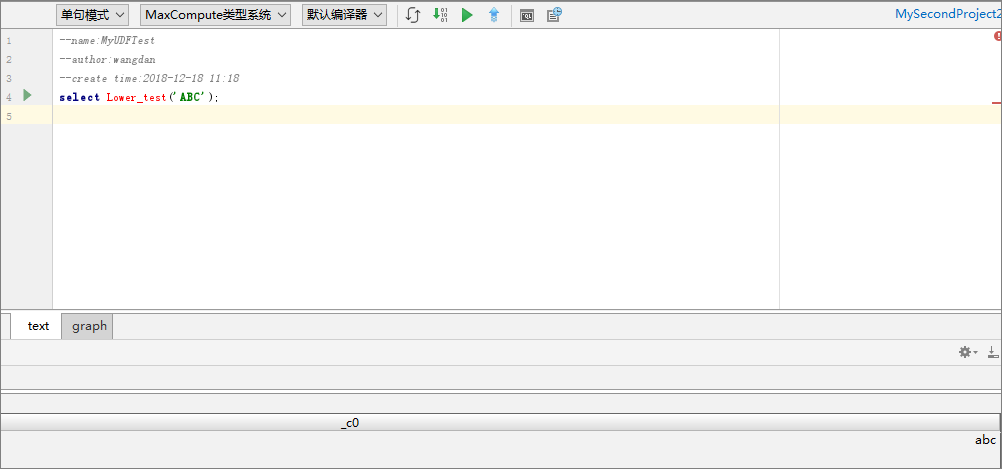
说明 Studio中编写SQL脚本请参见编写SQL脚本。
- 准备工具环境并创建Java Module。
- 使用Eclipse插件开发
- 创建工程
此处假设已经在Eclipse插件创建好一个MaxCompute(原名ODPS)工程,详情请参见创建MaxCompute工程。
- 编写代码按照MaxCompute UDF框架的规定,实现函数功能,并进行编译。示例如下:
将这个Jar包命名为 my_lower.jar。说明package <package名称>; import com.aliyun.odps.udf.UDF; public final class Lower extends UDF { public String evaluate(String s) { if (s == null) { return null; } return s.toLowerCase(); } } - 添加资源在运行UDF之前,必须指定引用的UDF代码。代码通过资源的形式添加到MaxCompute中。Java UDF必须被打成Jar包,以Jar资源添加到MaxCompute中,UDF框架会自动加载Jar包,运行用户自定义的UDF。
说明 MaxCompute MapReduce也用到了资源这一特有概念,MapReduce文档中对资源的使用也有阐述。
执行如下命令:add jar my_lower.jar; -- 如果存在同名的资源请将这个jar包重命名 -- 并注意修改下面示例命令中相关jar包的名字 -- 又或者直接使用-f选项覆盖原有的jar资源 - 注册UDF函数命令格式如下:
参数说明:CREATE FUNCTION <function_name> AS <package_to_class> USING <resource_list>;- function_name:UDF函数名,这个名字就是SQL中引用该函数所使用的名字。
- package_to_class:如果是Java UDF,这个名字就是从顶层包名一直到实现UDF类名的fully qualified class name。如果是python UDF,这个名字就是python脚本名.类名。并且这个名字必须使用引号。
- resource_list:UDF所用到的资源列表。
- 此资源列表必须包括UDF代码所在的资源。
- 如果您的代码中通过distributed cache接口读取资源文件,此列表中还要包括UDF所读取的资源文件列表。
- 资源列表由多个资源名组成,资源名之间由逗号分隔,且资源列表必须用引号引起来。
- 如果需要指定资源所在的project,写法为
<project_name>/resources/<resource_name>。
Jar包被上传后,使得MaxCompute有条件自动获取代码并运行。但此时仍然无法使用这个UDF,因为MaxCompute中并没有关于这个UDF的任何信息。因此需要在MaxCompute中注册一个唯一的函数名,并指定这个函数名与哪个jar资源的哪个类对应。
执行如下命令:
说明CREATE FUNCTION test_lower AS 'org.alidata.odps.udf.examples.Lower' USING 'my_lower.jar';- 与资源文件一样,同名函数只能注册一次。
- 一般情况下,您的自建函数无法覆盖系统内建函数。只有项目空间的Owner才有权利覆盖内建函数。如果您使用了覆盖内建函数的自定义函数,在SQL执行结束后,会在Summary中打印出warning信息。
- 在SQL中使用此函数进行验证:
select test_lower('A') from my_test_table;
- 创建工程
UDAF示例
UDAF的注册方式与UDF基本相同,使用方式与内建函数中的聚合函数相同。计算平均值的UDAF的代码示例,如下所示:
package org.alidata.odps.udf.examples;
import com.aliyun.odps.io.LongWritable;
import com.aliyun.odps.io.Text;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
/**
* project: example_project
* table: wc_in2
* partitions: p2=1,p1=2
* columns: colc,colb,cola
*/
public class UDAFExample extends Aggregator {
@Override
public void iterate(Writable arg0, Writable[] arg1) throws UDFException {
LongWritable result = (LongWritable) arg0;
for (Writable item : arg1) {
Text txt = (Text) item;
result.set(result.get() + txt.getLength());
}
}
@Override
public void merge(Writable arg0, Writable arg1) throws UDFException {
LongWritable result = (LongWritable) arg0;
LongWritable partial = (LongWritable) arg1;
result.set(result.get() + partial.get());
}
@Override
public Writable newBuffer() {
return new LongWritable(0L);
}
@Override
public Writable terminate(Writable arg0) throws UDFException {
return arg0;
}
}UDTF示例
UDTF的注册和使用方式与UDF相同。代码示例如下:
package org.alidata.odps.udtf.examples;
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.UDTFCollector;
import com.aliyun.odps.udf.annotation.Resolve;
import com.aliyun.odps.udf.UDFException;
// TODO define input and output types, e.g., "string,string->string,bigint".
@Resolve({"string,bigint->string,bigint"})
public class MyUDTF extends UDTF {
@Override
public void process(Object[] args) throws UDFException {
String a = (String) args[0];
Long b = (Long) args[1];
for (String t: a.split("\\s+")) {
forward(t, b);
}
}
}MaxCompute提供多种内建函数来满足您的计算需求,同时您还可以使用DataWorks创建自定义函数来满足不同的计算需求。您也可以参考更多UDF示例。
编写Graph(可选)
本文将以SSSP算法为例,为您介绍如何提交Graph作业。
Graph作业的提交方式与MapReduce的提交方式基本相同。如果您使用Maven,可以从Maven库中搜索 odps-sdk-graph获取不同版本的Java SDK,相关配置信息如下所示:
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-sdk-graph</artifactId>
<version>0.20.7</version>
</dependency>操作步骤
- 进入console并运行odpscmd。
- 创建输入表和输出表 。
create table sssp_in (v bigint, es string); create table sssp_out (v bigint, l bigint);创建表的更多语句请参见表操作。
- 上传数据。本地数据的内容如下:
以空格键做两列的分隔符,执行Tunnel命令上传数据。1 2:2,3:1,4:4 2 1:2,3:2,4:1 3 1:1,2:2,5:1 4 1:4,2:1,5:1 5 3:1,4:1tunnel u -fd " " sssp.txt sssp_in; - 编写SSSP示例。根据Graph开发插件的介绍,本地编译、调试SSSP算法示例。本示例中假设代码被打包为 odps-graph-example-sssp.jar。
说明 仅需要将SSSP代码打包即可,不需要同时将SDK打入 odps-graph-example-sssp.jar中。
- 添加Jar资源。
add jar $LOCAL_JAR_PATH/odps-graph-example-sssp.jar;说明 添加资源的介绍请参见资源操作。
- 运行SSSP。
jar -libjars odps-graph-example-sssp.jar -classpath $LOCAL_JAR_PATH/odps-graph-example-sssp.jar com.aliyun.odps.graph.example.SSSP 1 sssp_in sssp_out;Jar命令用于运行MaxCompute Graph作业,用法与MapReduce作业的运行命令完全一致。
Graph作业执行时命令行会打印作业实例ID,执行进度,结果Summary等。
输出示例如下所示:ID = 20130730160742915gl205u3 2013-07-31 00:18:36 SUCCESS Summary: Graph Input/Output Total input bytes=211 Total input records=5 Total output bytes=161 Total output records=5 graph_input_[bsp.sssp_in]_bytes=211 graph_input_[bsp.sssp_in]_records=5 graph_output_[bsp.sssp_out]_bytes=161 graph_output_[bsp.sssp_out]_records=5 Graph Statistics Total edges=14 Total halted vertices=5 Total sent messages=28 Total supersteps=4 Total vertices=5 Total workers=1 Graph Timers Average superstep time (milliseconds)=7 Load time (milliseconds)=8 Max superstep time (milliseconds) =14 Max time superstep=0 Min superstep time (milliseconds)=5 Min time superstep=2 Setup time (milliseconds)=277 Shutdown time (milliseconds)=20 Total superstep time (milliseconds)=30 Total time (milliseconds)=344 OK说明 如果您需要使用Graph功能,直接开通提交图计算作业即可。
使用临时查询快速查询SQL(可选)
如果您已经创建了MaxCompute项目(DataWorks工作空间),可以直接使用DataWorks临时查询功能,快速书写SQL语句操作MaxCompute。
关于临时查询功能的具体信息,请参见临时查询。
进入临时查询
点击DataWorks控制台工作空间列表,选择您需要进入的项目,点击 进入数据开发。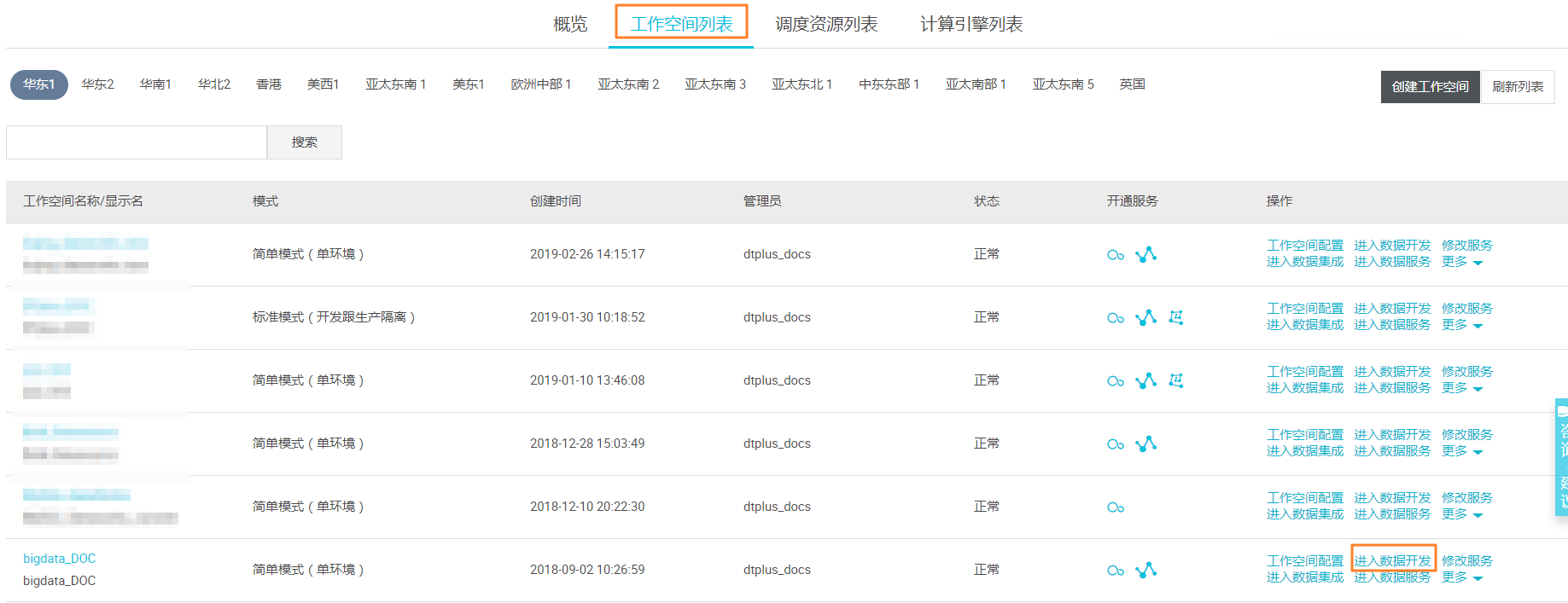
直接点击 临时查询,右键 临时查询,点击 新建节点 > ODPS SQL。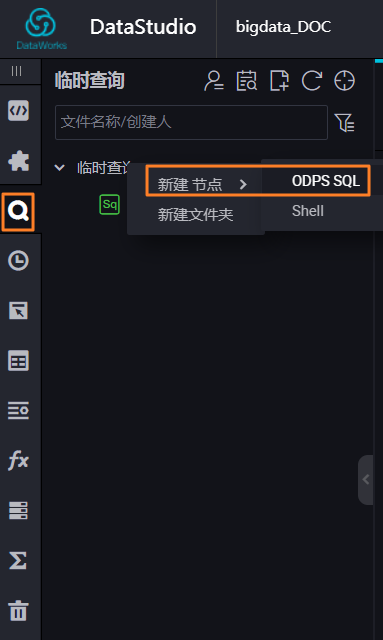
在弹框中输入节点名称,点击 提交,创建您的临时查询节点。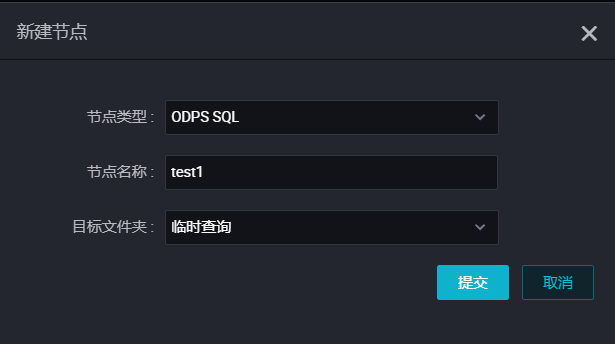
运行SQL
现在您可以在刚刚创建的临时查询节点中运行MaxCompute支持的SQL语句了,我们以运行一个DDL语句创建表为例。
输入建表语句,点击 运行即可。
create table if not exists sale_detail
(
shop_name string,
customer_id string,
total_price double
)
partitioned by (sale_date string,region string);
-- 创建一张分区表sale_detail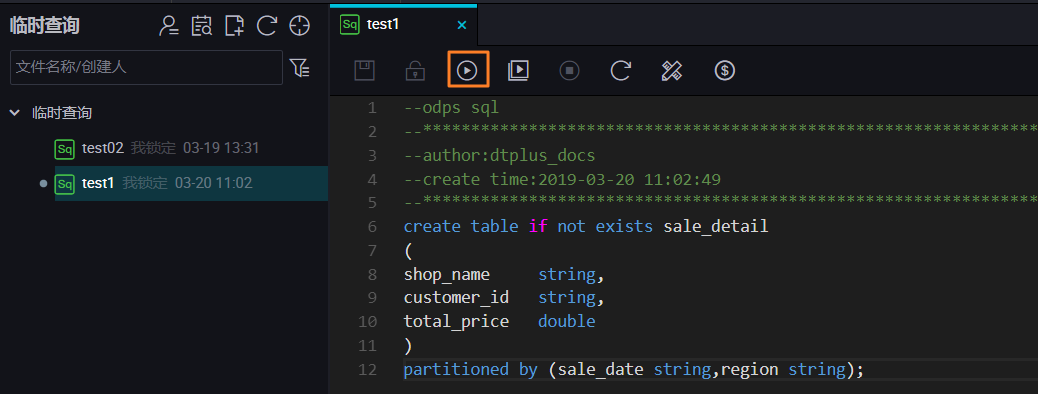
在弹框中您可以看到本次运行的费用预估,继续点击 运行。
您可以在下方的日志窗口,看到运行情况和最终结果:本次运行成功,结果为 OK。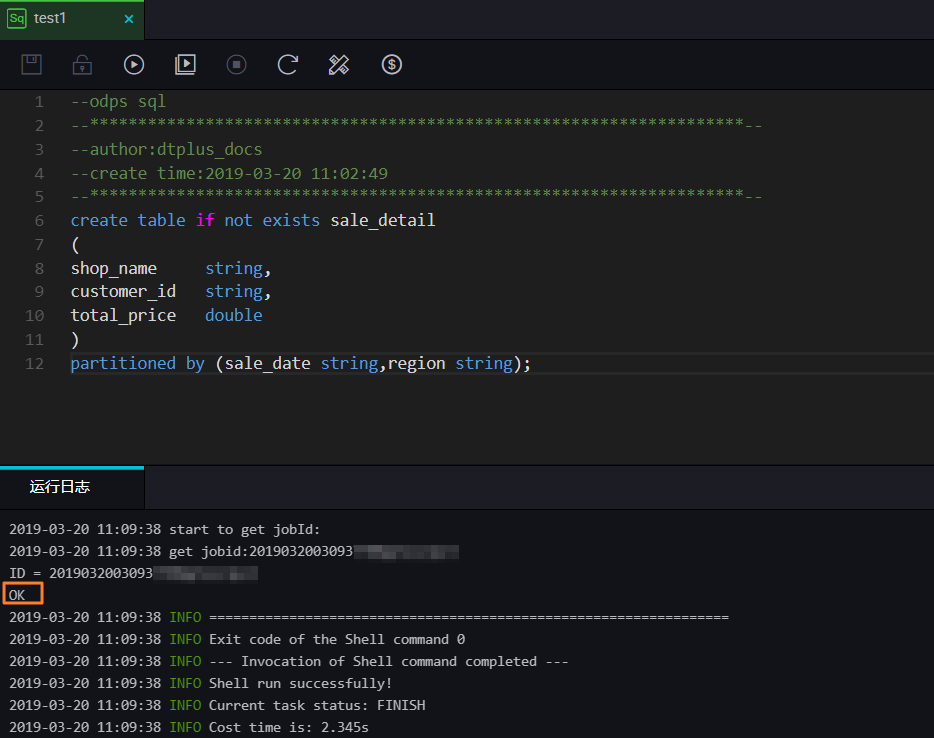
使用同样的方法,您也可以执行查询语句。