参考--极客时间 深入剖析kubernetes
容器隔离使用namespace技术,将容器进程和宿主机进程隔离。
普通进程:pid = clone(main_function, stack_size, SIGCHLD, NULL);
容器进程:int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
使用CLONE_NEWPID参数,使容器进程无法查看宿主机其他进程,并且将自己的pid设置为1。
Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace。
linux内核无法被namespace化的资源和对象:
时间:使用settimeofday(2)系统调用修改时间,整个宿主机的时间也被修改
=====
Cgroups: Linux内核用来为进程设置资源限制的功能。
Cgroups以文件和目录的方式组织在操作系统 /sys/fs/cgroup路径下,Ubuntu可以使用mount命令将其展示出来:
# mount -t cgroup cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd) cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma) cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb) cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory) cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset) cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices) cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio) cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio) cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct) cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event) cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer) cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
/sys/fs/cgroup/目录下有很多子目录(子系统),显示本主机可以限制的资源种类。以cpu为例:
# ls /sys/fs/cgroup/cpu cgroup.clone_children cpuacct.stat cpuacct.usage_percpu cpuacct.usage_sys cpu.cfs_quota_us docker system.slice cgroup.procs cpuacct.usage cpuacct.usage_percpu_sys cpuacct.usage_user cpu.shares notify_on_release tasks cgroup.sane_behavior cpuacct.usage_all cpuacct.usage_percpu_user cpu.cfs_period_us cpu.stat release_agent user.slice
cfs_period 和 cfs_quota组合使用,表示在cfs_period时间内,只能分配到cfs_quota总量的CPU使用时间。
blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
cpuset,为进程分配单独的 CPU 核和对应的内存节点;
memory,为进程设定内存使用的限制
使用:
只需要在每个子系统下面,为每一个容器创建一个控制组(即新创建一个目录),然后启动容器后,将进程pid写入到对应控制组的tasks文件中即可。
$ echo <PID> > /sys/fs/cgroup/cpu/container/tasks
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash # 100ms(100000us)的时间内,只能使用20ms(20000us)的CPU时间,即20%的CPU带宽
一个容器的本质就是一个进程,用户的应用进程实际上就是容器里 PID=1 的进程,也是其他后续创建的所有进程的父进程。这就意味着,在一个容器中,你没办法同时运行两个不同的应用,除非你能事先找到一个公共的 PID=1 的程序来充当两个不同应用的父进程,这也是为什么很多人都会用 systemd 或者 supervisord 这样的软件来代替应用本身作为容器的启动进程。
=====
mount namespace:
mount namespace和其他namespace略有不同,它对容器视图的改变,一定伴随着挂载操作(mount)才能生效。
Linux操作系统有chroot命令可以帮助在shell中完成根目录的挂载(change root file system),即rootfs
chroot /path /bin/bash
容器大概流程:
1. 启用Linux namespace配置,
2. 设置指定的cgroups参数,
3. 切换进程根目录rootfs(change root)(优先pivot_root,没有使用chroot)
???
docker create 没有创建系统挂载点?启动之后才会创建??
为什么podman create 后就可以使用podman mount container返回系统挂载点??
???
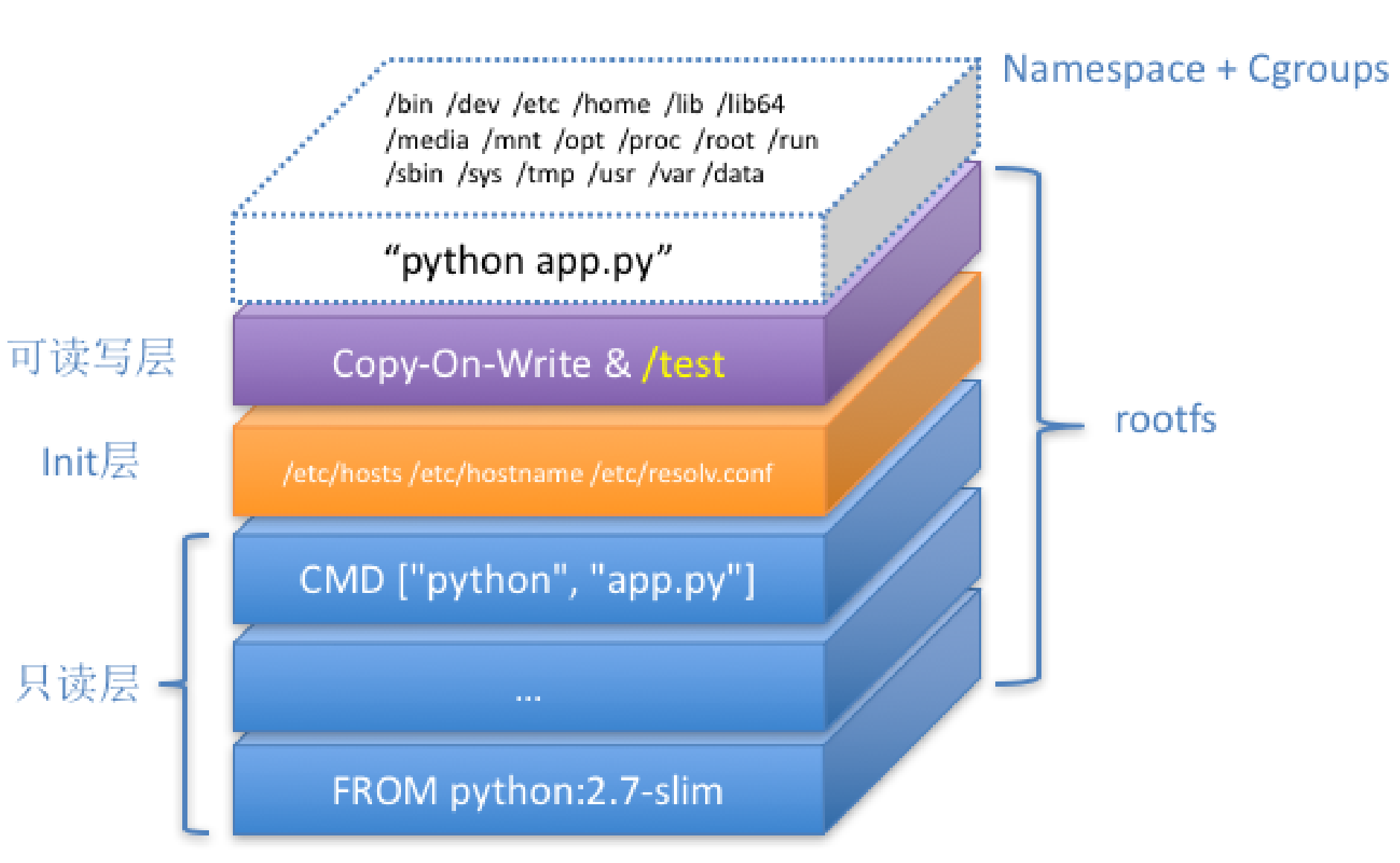
镜像层 ro+wh(read only + whitout)
要删除只读镜像层的内容只需在rw层添加.wh.filename

init 层用来存放/etc/hosts, /etc/resolv.conf 等信息,这些信息只对当前容器有效,commit时不会携带此层
使用下面命令来查看容器pid:
docker inspect --format '{{ .State.Pid }}' <containerId>
查看宿主机proc文件来查看进程对应的namespace
ls -l /proc/PID/ns
# ls -l /proc/11520/ns total 0 lrwxrwxrwx 1 root root 0 May 27 21:30 cgroup -> 'cgroup:[4026531835]' lrwxrwxrwx 1 root root 0 May 27 21:30 ipc -> 'ipc:[4026532432]' lrwxrwxrwx 1 root root 0 May 27 21:30 mnt -> 'mnt:[4026532430]' lrwxrwxrwx 1 root root 0 May 27 21:30 net -> 'net:[4026532435]' lrwxrwxrwx 1 root root 0 May 27 21:30 pid -> 'pid:[4026532433]' lrwxrwxrwx 1 root root 0 May 27 21:30 pid_for_children -> 'pid:[4026532433]' lrwxrwxrwx 1 root root 0 May 27 21:30 user -> 'user:[4026531837]' lrwxrwxrwx 1 root root 0 May 27 21:30 uts -> 'uts:[4026532431]'
使用setns()系统调用来讲一个进程加入到已有的namespace中,达到docker exec的效果。
docker提供了--net 参数允许一个容器加入到另外一个容器network namespace中,
docker run -it --net container:<containerId> <image> <command>
如果使用--net=host,则不会为此容器建立network namespace,直接共享主机网络栈
Copy-on-Write:
在容器中对rootfs做的任何修改,都会被操作系统先拷贝到可读写层,然后再修改。
Volume:
docker run -v /test... #此方式会创建一个临时目录/var/lib/docker/[volumeId]/_data,然后挂载到/test上 docker run -v /path:/path
挂载数据卷,在容器执行chroot/pivot_root之前,容器是可以查看到宿主机的全部文件系统,只需要在rootfs准备好后,执行chroot或pivot_root之前,将指定宿主机的目录,挂载到容器目录/test(overlay2 对应/var/lib/docker/overlay2/[可读写层ID]/merged/test上、aufs在/var/lib/docker/aufs/mnt/[可读写层ID]/test上),因为执行这个操作时,mount namespace已经创建,所以挂载事件只能在容器内可见,而宿主机不可见。
以上操作都是docker创建的初始化进程dockerinit进行的,dockerinit负责根目录的准备,挂载设备和目录,配置hostname等一系列在容器内进行的初始化操作,随后通过调用execv()系统调用,让应用进程取代自己,成为pid 1的进程。
使用的挂载技术就是Linux绑定挂载(mount --bind)

mount --bind /home /test 会将/home挂载到/test上,所做的修改都是对被挂载目录的修改,一旦执行unmount命令,/test 目录原来的内容就会恢复。
并且宿主机并不知道这个挂载的存在,所以在宿主机眼中,容器在宿主机上对应/test目录始终是空的。因为docker commit是在宿主机视角去执行的,因此不会携带/test目录里的内容,但是/test目录还是会被提交并出现在新的镜像中。