前言:
看了那么多关于mpi4py使用的,却没见到一个能够举例在实际情况中的使用,笔者也是初学者,于是花了一整个下午来找例子并详细解答,希望能帮助想用mpi4py的后来者
提醒:这里不讨论如何使用mpi4py里面的函数,只举例mpi4py在实际中的应用
关于mpi4py的函数,可以见官网(英文)以及一些博客或者知乎
以下是例子,有时间会随时更新更多例子…
文章目录
例1,计算
例1,计算
, 参考自Parallel programming in Python: mpi4py
这里采用的计算
的式子是(维基-pi):以防有人不能进维基百科,截图如下:
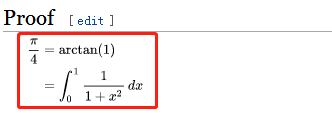
如果我们只是为了知道
的值,可以调用积分包计算即可,但是我们的目的是要多进程并行计算这个积分,所以不调用包。对于单进程而言,我们可以使用求和代替积分:
在解释代码之前,笔者需要提到的是,使用numpy的程序通过数组计算也是非常快的
import numpy as np
import time
def pi_comput(step):
partial_pi = 0
dx = 1/step
for i in np.arange(0,1,dx):
partial_pi += 4/(1+i*i)*dx
return partial_pi
t0 = time.time()
print('pi is :>>> ',pi_comput(10000000))
t1 = time.time()
print('time cost: %s sec'%(t1-t0))
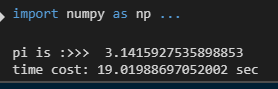
可以看到当我们取10000000步长时,已经可以比较准确的计算出pi了,但是时间却花了19秒,我们的目标是减少时间使用
上面的公因子dx可以提前(下文也会提到),将函数改为:
def pi_comput(step):
partial_pi = 0
dx = 1/step
for i in np.arange(0, 1, dx):
partial_pi += 4/(1+i*i)
return partial_pi*dx
这样时间减到了16秒
(注:像这种简单的问题,我们实际上借助numpy的数组计算是非常快的,只花了0.1376秒,比多进程还快,这里使用6个进程花了0.938秒;具体可以参考笔者另一博文3.2节)
以下代码保留原作者的英文注释,笔者加入中文注释
from mpi4py import MPI
import time
import math
t0 = time.time()
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
nprocs = comm.Get_size()
#上面都是mpi4py多进程的标准输入,每次开头如此输入即可
# number of integration steps
nsteps = 10000000
# step size
dx = 1.0 / nsteps
if rank == 0:
# determine the size of each sub-task
# 这里divmod可以同时得到商和余数,如divmod(10,3)得到3和1
ave, res = divmod(nsteps, nprocs)
#counts得到的是每个进程计算的数量个数,如第一个进程算前1000个,第二个进程算1000以后
counts = [ave + 1 if p < res else ave for p in range(nprocs)]
# determine the starting and ending indices of each sub-task
starts = [sum(counts[:p]) for p in range(nprocs)]
ends = [sum(counts[:p+1]) for p in range(nprocs)]
# save the starting and ending indices in data
data = [(starts[p], ends[p]) for p in range(nprocs)]
else:
data = None
data = comm.scatter(data, root=0)
# compute partial contribution to pi on each process
partial_pi = 0.0
for i in range(data[0], data[1]):
x = (i + 0.5) * dx
partial_pi += 4.0 / (1.0 + x * x)
partial_pi *= dx
partial_pi = comm.gather(partial_pi, root=0)
if rank == 0:
print('pi is :>>> ',sum(partial_pi)) 笔者加的
print('pi computed in {:.3f} sec'.format(time.time() - t0))
print('error is {}'.format(abs(sum(partial_pi) - math.pi)))
分步解释
1)前期处理
if rank == 0:
ave, res = divmod(nsteps, nprocs) # ave=16,res=4
#
counts = [ave + 1 if p < res else ave for p in range(nprocs)]
# determine the starting and ending indices of each sub-task
starts = [sum(counts[:p]) for p in range(nprocs)]
ends = [sum(counts[:p+1]) for p in range(nprocs)]
# save the starting and ending indices in data
data = [(starts[p], ends[p]) for p in range(nprocs)]
else:
data = None
这里以步长为100,进程数为6来说明。
则上面的

- nsteps = 100
- nprocs = 6
- dx = 0.01
则在第一个if语句中计算得到:
- ave = 16
- res = 4
p in range(6)即表示p=array([0,1,2,3,4,5]), p是一个数组,当p<res时,counts=ave+1否则counts=ave;则可以得到counts为
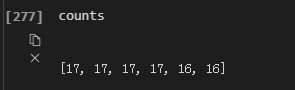
表示前4个进程计算17个步长数,后两个进程计算16个步长数
同理可以得到starts,ends的值
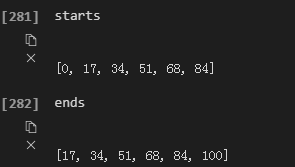
分别表示进程进行的开始和结束位置。现在将开始和结束位置表示在一个元组里面,即data的值
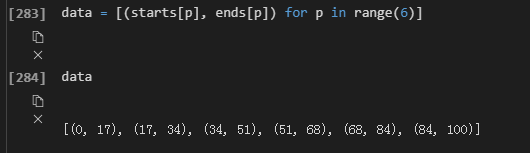
上面可以作为多进程运算的模板,以后计算进程的开始和结束位置时可用。
到此我们已经结束了当rank=0时的表述,我们输入进程个数(即mpirun -np 6 python xxx.py里面的6)时,首先进行的是rank=0。
2)分工计算
这里只需要一句代码即可,即使用scatter来分发数据,分到6个进程中
data = comm.scatter(data, root=0) #root=0表示从rank=0的进程来分发
3)计算
下面的partial_pi指的是被积函数
partial_pi = 0.0 初始化partial_pi=0
for i in range(data[0], data[1]):
x = (i + 0.5) * dx
partial_pi += 4.0 / (1.0 + x * x)
partial_pi *= dx
在scatter分发完后,每个进程有一个计算区间,如第一个进程的区间是(0,17),则data[0]=0,data[1]=17;
所以对于第一个进程,上面为:
for i in range(0,17)
关于
x = (i+0.5)*dx
这一句实际上应该是x=i*dx,作者加了0.5是因为python里面的range不包括最后一个数,所以作者自己加了0.5这个数,需要记住的是,这个数很小,所以关系不大,也可以直接用x=i*dx这样比较直观。
最后一句作者写的是:
partial_pi *= dx
这是因为公因子可以提前,在笔者另一博文3.2节也提到过。
于是上面的6个进程分别计算对应的区间,得到6个结果
4)合并结果
partial_pi = comm.gather(partial_pi, root=0)
每个进程分工计算完成之后,得到了6个结果,现在要将结果合并,使用gather函数,这个函数合并之后的结果是一个列表,比如这6个进程的结果分别是a,b,c,d,e,f,g,那么gather之后是
[a,b,c,d,e,f,g]
因此对partial_pi合并,并放到root=0即第一个进程中,所以在后面if语句输出时,只要找到rank=0即可输出;
最后需要提醒的是,由于我们得到的是列表,而最后pi是一个值,我们需要用sum函数将这个列表求和。
if rank == 0:
print('pi is :>>> ',sum(partial_pi))
print('pi computed in {:.3f} sec'.format(time.time() - t0))
print('error is {}'.format(abs(sum(partial_pi) - math.pi)))
5)结果
使用6个进程计算的结果是0.94秒(注:不同计算机的运行时间会有一定偏差)

如前往所说,这个计算结果赶不上使用数值计算快。
那么是否有更快的方法?答案是肯定的,因为我们使用多进程提高了运算速度,使用numpy又提高了运算速度,那最好的办法就是将两者同时使用。
6)进一步提升
我们借鉴笔者另一博文3.2节(建议看一看),将for循环使用数组来代替,则下面的代码:
for i in range(data[0], data[1]):
x = (i + 0.5) * dx
partial_pi += 4.0 / (1.0 + x * x)
partial_pi *= dx
改为:
x = np.arange(data[0],data[1])*dx
partial_pi = np.sum(4/1+x*x)*dx
注意在开始要import numpy;另外这里我不使用作者的+0.5处理;运行时间降到了0.052!!!

这是我们最后的程序:
from mpi4py import MPI
import time
import math
import numpy as np
t0 = time.time()
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
nprocs = comm.Get_size()
# number of integration steps
nsteps = 10000000
# step size
dx = 1.0 / nsteps
if rank == 0:
# determine the size of each sub-task
ave, res = divmod(nsteps, nprocs)
counts = [ave + 1 if p < res else ave for p in range(nprocs)]
# determine the starting and ending indices of each sub-task
starts = [sum(counts[:p]) for p in range(nprocs)]
ends = [sum(counts[:p+1]) for p in range(nprocs)]
# save the starting and ending indices in data
data = [(starts[p], ends[p]) for p in range(nprocs)]
else:
data = None
data = comm.scatter(data, root=0)
# compute partial contribution to pi on each process
partial_pi = 0.0
x = np.arange(data[0],data[1])*dx
partial_pi = np.sum(4/(1+x*x))*dx
partial_pi = comm.gather(partial_pi, root=0)
if rank == 0:
print('pi is :>>> ',sum(partial_pi))
print('pi computed in {:.3f} sec'.format(time.time() - t0))
print('error is {}'.format(abs(sum(partial_pi) - math.pi)))
7)总结
我相信详细看完了博文的朋友收获应该是比较大的。
- 这里我们使用for来求pi的值,花了19秒,然后在此基础上将公因子提出来改进代码,之后运行花了16秒
- 我们采用了多进程的方法之后,将时间缩短到了0.94秒(巨大进步)
- 我们采用numpy数组的方法(另一博文3.2节)花了0.165秒,在此基础上将公因子提出来改进代码,之后运行花了0.138秒(numpy的进步也是巨大的)
- 最后我们结合多进程和numpy同时使用,改进代码之后花了0.052秒(提高了365倍!!)
8) appendix
上面我们给每个进程分区间的时候基本是等比例分的,而现实中会出现很多不等比例分的情况,比如当x比较小的时候运算很快,但是x比较大的时候运算很慢,这个时候我们希望将x比较大的部分多分一些给多个进程。
从上面的例子我们可以看到,实际上就是data中的数组自己定义即可,比如将上面的程序中的if部分改为:
即将:
if rank == 0:
# determine the size of each sub-task
# 这里divmod可以同时得到商和余数,如divmod(10,3)得到3和1
ave, res = divmod(nsteps, nprocs)
#counts得到的是每个进程计算的数量个数,如第一个进程算前1000个,第二个进程算1000以后
counts = [ave + 1 if p < res else ave for p in range(nprocs)]
# determine the starting and ending indices of each sub-task
starts = [sum(counts[:p]) for p in range(nprocs)]
ends = [sum(counts[:p+1]) for p in range(nprocs)]
# save the starting and ending indices in data
data = [(starts[p], ends[p]) for p in range(nprocs)]
else:
data = None
改为
if rank == 0:
data = [(0,round(1/10*nsteps)),(round(1/10*nsteps),round(3/10*nsteps)),(round(3/10*nsteps),nsteps)]
else:
data = None
或者直接为
if rank == 0:
data = [(0,10),(10,30),(30,100)]
else:
data = None
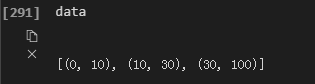
此时我们运行的时候-np后面只能接3,表示3个进程,因为我们分成了3个,如果要将进程变成一个变量,则需要将nprocs引进来。
比如对于
从lmin到lmax,要求对进程每次任务对半分。比如有5个进程,
为100,第一个进程处理到一半即从lmin到50,第二个进程处理到剩下的一半,即从50到75,第三个进程又处理到剩下的一半,即从75到88(四舍五入),…如此分法,一直到结束lmax,相当于是
。
下面这个函数可以实现这个功能(临时写的,肯定有更好的写法)
import numpy as np
import copy
lmin = 2
lmax = 100
nprocs = 5
def binary_split(nprocs):
frac = 0
end = []
for i in range(1, nprocs):
frac += 1/np.power(2, i)
end.append(frac)
end = list(np.round(np.array(end)*lmax))
end.append(lmax)
end = [int(x) for x in end]
start = copy.copy(end)
start.insert(0,lmin)
start.pop(-1)
data = [(start[i],end[i]) for i in range(nprocs)]
return start,end,data
print(binary_split(nprocs))
