文本分类一般可以分为二分类、多分类、多标签分类三种情况,二分类是指将一组文本分成两个类(0或1),比较常见的应用如垃圾邮件分类、电商网站的用户评价数据的正负面分类等,多分类是指将文本分成若干个类中的某一个类,比如说门户网站新闻可以归属到不同的栏目中(如政治、体育、社会、科技、金融等栏目)去。多标签分类指的是可以将文本分成若干个类中的多个类,比如一篇文章里即描写政治又描写金融等内容,那么这篇文章可能会别贴上政治和金融两个标签。今天我尝试使用Python和sklearn来实现一下文本的多标签分类实战开发,我们要预测StackOverflow帖子的标签
数据探索与分析(EDA)
你可以在这里下载我们的数据,首先加载所需要的包,然后查看我们的数据。
%matplotlib inline
from ast import literal_eval
import pandas as pd
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy import sparse as sp_sparse
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.multiclass import OneVsRestClassifier
from sklearn.linear_model import LogisticRegression, RidgeClassifier
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
import nltk
import re
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))def read_data(filename):
data = pd.read_csv(filename, sep='\t')
data['tags'] = data['tags'].apply(literal_eval)
return data
train = read_data('./data/Multil_label_data/train.tsv')
validation = read_data('./data/Multil_label_data/validation.tsv')
print(len(train))
print(len(validation))
train.sample(10) 
我们加载了两个表train和validation,train中有10万条记录,validation中有3万条记录。train表中包含了两个字段,title和tags,其中title是Stackoverflow帖子的标题,tags表示该标题对应的栏目。很明显,此处一个title可以对应多个tag,如果我们要预测一个title对应哪些tag的话,那这就是典型的多标签分类的问题,下面我们来查看一下标签(tags)的分布情况。
tags = train['tags'].values
tag_dic={}
for tag_list in tags:
for tag in tag_list:
if tag not in tag_dic:
tag_dic[tag]=1
else:
tag_dic[tag]+=1
df = pd.DataFrame(list(tag_dic.items()), columns=['tag', 'count']).sort_values(by = 'count',axis = 0,ascending = False)
print('标签总数:',len(df))
df.head(10)
我们可以看到总共有100种标签,我们同时列出了前10个标签出现的次数
#前10个数量最多的标签分布
df[:10].plot(x='tag', y='count', kind='bar', legend=False, grid=True, figsize=(10, 6),fontsize=18)
plt.title("每个标签的分布",fontsize=18)
plt.ylabel('出现次数', fontsize=18)
plt.xlabel('标签', fontsize=18)
我们看到标签的分布非常不均匀,javascript,c#,java的出现次数最多。接下来我们看看标签个数的分布情况
tagCount=train['tags'].apply(lambda x : len(x))
x = tagCount.value_counts()
#plot
plt.figure(figsize=(8,5))
ax = sns.barplot(x.index, x.values)
plt.title("标签数量分布",fontsize=15)
plt.ylabel('数量', fontsize=15)
plt.xlabel('标签数', fontsize=15)
我们看到2个标签的出现次数最多,5个标签出现次数最少。
接下来我要查看一下title长度的分布情况。
lens = train.title.str.len()
lens.hist(bins = 30,figsize=(10, 6),grid=False) 
我们看到title的长度在40个单词左右的数量最多,个别title的长度为160
接下来我们查看一下数据中的空值情况:

还好,数据中没有空值。
数据预处理
数据预处理是在训练分类器模型之前的一个必要过程,对于像英语这样的文本,数据预处理一般包含下面几个步骤:
- 将英文字母小写化处理,
- 删除文本中所有的标点符号.
- 删除文本中包含的英语停用词.
- 提取词干(stemming),单词被简化为根形式,如cats-->cat,meeting-->meet,等
- 词形还原(Lemmatization),第三人称的单词转换成第一人称单词,动词的过去式和将来式将转换成现在式。
- 文本特征抽取(CountVectorizer,TfidfVectorizer)
为了让本文更加简洁,stemming和Lemmatization我们就暂时不做了.
#用空格替换各种符号
REPLACE_BY_SPACE_RE = re.compile('[/(){}\[\]\|@,;]')
#删除各种符号
BAD_SYMBOLS_RE = re.compile('[^0-9a-z #+_]')
STOPWORDS = set(stopwords.words('english'))
#定义数据清洗函数
def text_prepare(text):
text = text.lower() # 字母小写化
text = REPLACE_BY_SPACE_RE.sub(' ',text)
text = BAD_SYMBOLS_RE.sub('',text)
text = ' '.join([w for w in text.split() if w not in STOPWORDS]) # 删除停用词
return text我们会用空格来替换一些符号,空格可以用来分隔单词,我们还要删除一些特殊符号(如一些不可见符号,回车,换行符之类的),此处要注意一点,我们匹配的是除了“0-9a-z”和“#+_”之外的所有符号,那也就是说“0-9a-z”和“#+_”会被保留下来,为什么要保留“#+_”这些符号呢,大家可以思考一下。然后我们还要删除停用词。接下来我们开始清洗数据:
X_train, y_train = train.title, train.tags
X_val, y_val = validation.title, validation.tags
#开始进行数据清洗
X_train = [text_prepare(x) for x in X_train]
X_val = [text_prepare(x) for x in X_val]
X_train[:10]
数据经过清洗以后,变得"干净"了,接下来我们要对它们进行量化处理。
特征抽取
我们的文本数据不能直接喂给分类器,因为分类器"消化"不了文本数据,所以必须对文本数据进行量化处理,量化处理文本数据有两种方式,一种是计算单词词频的方式,我们使用sklearn的CountVectorizer方法来统计文本中所有单词在文本中出现的次数即词频。第二种方式是计算TF-IDF,即计算每个词的逆向词频的权重,换句话说TF-IDF值表示的是每个单词在文本中的重要程度,我们使用sklearn的TfidfVectorizer方法来计算每个单词的TF-IDF值。这两种方法都是对文本量化处理的基本方法,只有经过这两种方法量化处理过的文本才能被"喂"给分类器模型进行学习和训练。不过我们只要任选其中的一种方法就可以实现对模型的训练和预测。为了让大家能够了解这两种方法,我们把这两种方法都介绍一下。
- CountVectorizer
计算文本中每个单词的词频(wordcount),并生成基于词频的稀疏矩阵,其中参数:
min_df : 过滤掉那些词频小于指定阈值的单词,如min_df=5表示过滤掉词频小于5次的单词(绝对值)
max_df : 过滤掉那些词频大于指定阈值的单词,如max_df=0.9表示过滤掉词频大于那些在90%以上文档中都出现的单词(相对值)
token_pattern : CountVectorizer在分隔单词的一种取舍模式。
min_df和max_df的值如果是整数则表示绝对值,表示次数,如果是浮点型则表示相对值,表示相对与所有文档的百分比。之所以要设置这两个参数,是因为通过设定min_df 可以过滤掉一些由于笔误造成的错误单词。通过设定max_df可以过滤掉一些词频教高的常用词,这些词频较高的常用词,它们的TF-IDF值会很低,即意味着它们对文本来说是无关紧要的,如一些感叹词,语助词什么的,如果不过滤这些词,则因为特征(feature)的数量太多。从而增加计算的复杂度,和系统开销。
token_pattern参数是一个正则表达式,它告诉CountVectorizer在分词的时候按照给定的正则表达式来分词。token_pattern= '(\S+)'表示匹配任意多个符号,如“c++”、"c#"会被匹配到,如果不设置token_pattern参数那么文本中的“c++”、"c#"都会被匹配成"c",这会给我们的预测带来很大的误差。
cv = CountVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')
feature = cv.fit_transform(X_train)
print(feature.shape)
print()
print(feature) 
我们将文本数据进行了量化处理从中抽取了文本的特征(feature),feature是一个稀疏矩阵它的维度是(100000,18300),即表示为有10万个文本,18300个单词。feature中有两列,第一列表示文本中的单词在词汇表中的索引,第二列表示该单词在该文本中出现的次数,其中1表示只出现了1次。接下来我们用TfidfVectorizer也来抽取一下文本的特征:
- TfidfVectorizer
计算文本中每个单词的逆向词频权重,并生成基于权重的稀疏矩阵,其中参数与CountVectorizer类似,这里不再赘述。
tfidf = TfidfVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')
feature = tfidf.fit_transform(X_train)
print(feature.shape)
print()
print(feature)
TfidfVectorizer从文本中抽取特征的方式和CountVectorizer相似,只是得到的不再是词频,而是TF-IDF的权重值用浮点数表示。
- MultiLabelBinarizer
处理完feature接下来我们要来处理标签数据,因为目前的标签数据的存储方式,对于我们训练分类器来说使用起来很不方便,因此我们要将标签数据转换成词袋(BOW)的格式,我们使用sklearn的MultiLabelBinarizer方法对tags进行二值化转换。
#生成多标签的词袋矩阵
mlb = MultiLabelBinarizer(classes=sorted(tag_dic.keys()))
y_train = mlb.fit_transform(y_train)
y_val = mlb.fit_transform(y_val)
print(y_train.shape)
print(train.tags[0])
print(y_train[0])
标签经过二值化转换以后维度变成了(100000,100),其中100000表示有10万条记录,100表示我们有100种标签,我们看到原来第一条记录的标签是'r',经过转换以后变成了‘0 0 ...0 1 0 0...0’,这里面不是全0哦,其中1所在的位置就是这100个标签中‘r’所在的位置。
抽取了特征(feature)和标签以后,就可以开始训练我们的分类器了。训练分类模型并不是一件很复杂的事情,我们可以使用sklearn提供的管道命令(Pipeline),它可以以批处理的方式实现对模型进行训练,不过在训练之前我们先定义一个评估函数,用来评估我们的预测结果的准确率.
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import average_precision_score
from sklearn.metrics import recall_score
def print_evaluation_scores(y_val, predicted):
accuracy=accuracy_score(y_val, predicted)
f1_score_macro=f1_score(y_val, predicted, average='macro')
f1_score_micro=f1_score(y_val, predicted, average='micro')
f1_score_weighted=f1_score(y_val, predicted, average='weighted')
print("accuracy:",accuracy)
print("f1_score_macro:",f1_score_macro)
print("f1_score_micro:",f1_score_micro)
print("f1_score_weighted:",f1_score_weighted)模型的选择
机器学习中常用的文本分类模型有支持向量机,朴素贝叶斯,逻辑回归等,而我们的特征(feature)又可以分成两种,CountVectorizer的特征和TfidfVectorizer的特征。我们将这两种特征分别喂给这三个模型,从而可以得到一种最优的特征和模型的组合。同时我们要使用sklearn的OneVsRestClassifier的多类/多标签策略来实现多标签分类,好吧,废话少说,咱们撸起袖子干起来!
1.TF-IDF+朴素贝叶斯
#朴素贝叶斯模型
NB_pipeline = Pipeline([
('tfidf', TfidfVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')),
('clf', OneVsRestClassifier(MultinomialNB())),
])
NB_pipeline.fit(X_train,y_train)
predicted = NB_pipeline.predict(X_val)
print_evaluation_scores(y_val,predicted)
2. TF-IDF+线性支持向量机
SVC_pipeline = Pipeline([
('tfidf', TfidfVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')),
('clf', OneVsRestClassifier(LinearSVC(), n_jobs=1)),
])
SVC_pipeline.fit(X_train,y_train)
predicted = SVC_pipeline.predict(X_val)
print_evaluation_scores(y_val,predicted)
3.TF-IDF+逻辑回归
LogReg_pipeline = Pipeline([
('tfidf', TfidfVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')),
('clf', OneVsRestClassifier(LogisticRegression(), n_jobs=1)),
])
LogReg_pipeline.fit(X_train,y_train)
predicted = LogReg_pipeline.predict(X_val)
print_evaluation_scores(y_val,predicted)
4. CountVectorizer+朴素贝叶斯
NB_pipeline = Pipeline([
('cv', CountVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')),
('clf', OneVsRestClassifier(MultinomialNB(
fit_prior=True, class_prior=None))),
])
NB_pipeline.fit(X_train,y_train)
predicted = NB_pipeline.predict(X_val)
print_evaluation_scores(y_val,predicted)
5. CountVectorizer+线性支持向量机
SVC_pipeline = Pipeline([
('cv', CountVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')),
('clf', OneVsRestClassifier(LinearSVC(), n_jobs=1)),
])
SVC_pipeline.fit(X_train,y_train)
predicted = SVC_pipeline.predict(X_val)
print_evaluation_scores(y_val,predicted)
6. CountVectorizer+逻辑回归
LogReg_pipeline = Pipeline([
('cv', CountVectorizer(min_df=5,max_df=0.9,ngram_range=(1,2),token_pattern= '(\S+)')),
('clf', OneVsRestClassifier(LogisticRegression(), n_jobs=1)),
])
LogReg_pipeline.fit(X_train,y_train)
predicted = LogReg_pipeline.predict(X_val)
print_evaluation_scores(y_val,predicted)
模型的评估
1.Accuracy
Accuracy=正确的分类样本量 / 样本总量。在多标签分类中,样本的每个分类全部都分对才算正确分类。例如:
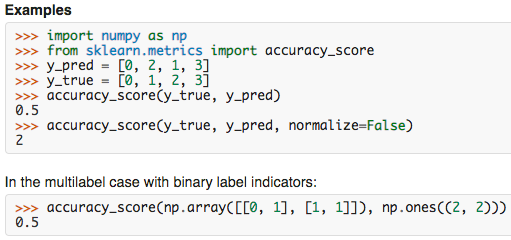
我们看到在我们的6个模型的组合中,第二种组合: TF-IDF+线性支持向量机 组合的accuracy最高,不过也只有0.376。在多分类和多标签分类中,Accuracy不是一个非常好的评估指标,当我们的样本中的各个类分布不均匀时,Accuracy不能反应出模型的实际表现。所以在多分类和多标签分类中,我们会采样如F1-score和ROC这样的评估指标,它们能更加全面的评估模型的表现。
2.F1-score


我们看到在我们的6个模型的组合中,第二种组合: TF-IDF+线性支持向量机 组合的f1_score_macro, f1_score_micro, f1_score_weighted都是最高的,分别达到了0.52,0.68,0.66
宗上所述,最优的模型组合是TF-IDF+线性支持向量机
尽管TF-IDF+线性支持向量机是最优组合,但是F1分数并不是很高,还存在优化的空间。等以后有时间我们再来对它进行优化。
总结
我们完成了对数据探索和分析(EDA),我们分析了各个标签的分布,标签数的分布以及标题(title)长度的分布。然后我们学会了如何使用CountVectorizer和TfidfVectorizer抽取文本的特征。最后我们还学会了如何利用sklearn的管道命令训练我们的模型组合并通过对评估找出了最优的组合。尽管找到最优的模型组合,但是模型还存在优化的空间...