一、实验内容
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
输入如下所示:
1)file1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2)file2:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
输出如下所示:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
二、实验过程
1、在HDFS下创建一个名称为datatoheavy的目录
./bin/hdfs dfs -mkdir datatoheavy

2、创建并编辑file1.txt和file2.txt文本文件
gedit file1.txt
dedit file2.txt

3、cat命令显示file1.txt和file2.txt文本文件的具体内容
./bin/hdfs dfs -cat ./datatoheavy/file2.txt

4、在HDFS下创建一个名称为datatoheavy/input的目录
./bin/hdfs dfs -mkdir datatoheavy/input

5、把file1.txt和file2.txt文本文件上传到hdfs的datatoheavy/input目录下
./bin/hdfs dfs -put ./file1.txt datatoheavy/input
./bin/hdfs dfs -put ./file2.txt datatoheavy/input

6、查看datatoheavy下的目录有哪些
(运行eclipse前应该没有output文件夹,不然后面运行相应的工程时会报错,output是运行时自动创建的)
./bin/hdfs dfs -ls datatoheavy/input

在localhost:50070中的/user/hadoop/datatoheavy/input目录下

数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。
7、我创建了DataToHeavy的Map/Reduce工程,以及它里面的类DedupMapper.java、DedupReducer.java、DataToHeavy.java。
8、DataToHeavy.java程序如下
package org.apache.hadoop.examples;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.itcast.hadoop.mr.dedup.DedupMapper;
import cn.itcast.hadoop.mr.dedup.DedupReducer;
public class DataToHeavy {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(DataToHeavy.class);
job.setMapperClass(DedupMapper.class);
job.setReducerClass(DedupReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000//user/hadoop/datatoheavy/input"));
// 指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000//user/hadoop/datatoheavy/output"));
job.waitForCompletion(true);
}
}

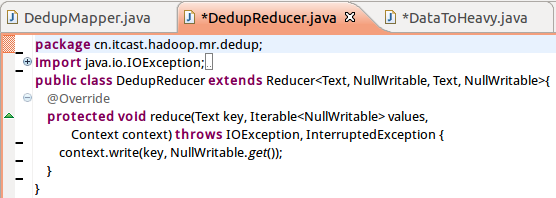
9、DedupReducer.java程序如下
package cn.itcast.hadoop.mr.dedup;
import java.io.IOException;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DedupReducer extends Reducer<Text, NullWritable, Text, NullWritable>{
@Override
protected void reduce(Text key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
10、DedupMapper.java程序如下
package cn.itcast.hadoop.mr.dedup;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DedupMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private static Text field = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
field = value;
context.write(field, NullWritable.get());
}
}

11、点击刚创建的DataToHeavy.java,选择Run As -> Run Configurations,设置运行时的相关参数如下

12、在localhost:50070中的/user/hadoop/datatoheavy/output目录下,运行完成出现两个文件

13、用cat命令查看运行完成时的part-r-00000文件,结果如下
./bin/hdfs dfs datatoheavy/output/part-r-00000

可见,该数据已经成功去重(没有重复的数据了)!

加油!
