【图算法】社区发现算法——Fast unfolding
参考博客:https://blog.csdn.net/google19890102/article/details/48660239
1. 社区划分问题的定义:
在社交网络中,用户相当于每一个点,用户之间通过互相的关注关系构成了整个网络的结构,在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏,在这样的的网络中,连接较为紧密的部分可以被看成一个社区,其内部的节点之间有较为紧密的连接,而在两个社区间则相对连接较为稀疏,这便称为社团结构。如何去划分上述的社区便称为社区划分的问题。
如图:

整个网络被划分成了两个部分(红色和黑色),其中,这两个部分的内部连接较为紧密,而这两个社区之间的连接则较为稀疏。
如何去划分上述的社区便称为社区划分问题。
2. 社区划分的评价标准:
社区划分的目标是使得划分后的社区内部的连接较为紧密,而在社区之间的连接较为稀疏。
通过模块度的可以刻画这样的划分的优劣,模块度越大,则社区划分的效果越好 。
模块度的公式如下所示:
其中:
- 表示网络中权重之和;
- 表示节点 和节点 之间的权重;
- 表示与节点 相连的边的权重和;
- 表示节点分配到的社区;
- 判断节点 和节点 是否划分到同一个社区,若是,返回 ;否则,返回 ;
因此,模块度也可以理解为网络中连接社区结构内部顶点的边所占的比例,减去在同样的社团结构下任意连接这两个节点的比例的期望值。
3. Fast unfolding算法:
3.1 Fast Unfolding算法的基本思路:
Fast Unfolding算法是一种迭代的算法,主要目标是不断划分社区使得划分后的整个网络的模块度不断增大。
3.2 算法流程:
主要分为两个阶段:
第一阶段称为Modularity Optimization,主要是将每个节点划分到与其邻接的节点所在的社区中,以使得模块度的值不断变大;
第二阶段称为Community Aggregation,主要是将第一步划分出来的社区聚合成为一个点,即根据上一步生成的社区结构重新构造网络。重复以上的过程,直到网络中的结构不再改变为止。
具体的算法过程如下所示:
-
初始化,将每个点划分在不同的社区中;
-
对每个节点,将每个点尝试划分到与其邻接的点所在的社区中,计算此时的模块度,判断划分前后的模块度的差值 是否为正数,若为正数,则接受本次的划分,若不为正数,则放弃本次的划分;
-
重复以上的过程,直到不能再增大模块度为止;
-
构造新图,新图中的每个点代表的是步骤3中划出来的每个社区,继续执行步骤2和步骤3,直到社区的结构不再改变为止。

4. 代码实现:
4.1 Python实现:
import networkx as nx
from itertools import permutations
from itertools import combinations
from collections import defaultdict
class Louvain(object):
def __init__(self):
self.MIN_VALUE = 0.0000001
self.node_weights = {} #节点权重
@classmethod
def convertIGraphToNxGraph(cls, igraph):
node_names = igraph.vs["name"]
edge_list = igraph.get_edgelist()
weight_list = igraph.es["weight"]
node_dict = defaultdict(str)
for idx, node in enumerate(igraph.vs):
node_dict[node.index] = node_names[idx]
convert_list = []
for idx in range(len(edge_list)):
edge = edge_list[idx]
new_edge = (node_dict[edge[0]], node_dict[edge[1]], weight_list[idx])
convert_list.append(new_edge)
convert_graph = nx.Graph()
convert_graph.add_weighted_edges_from(convert_list)
return convert_graph
def updateNodeWeights(self, edge_weights):
node_weights = defaultdict(float)
for node in edge_weights.keys():
node_weights[node] = sum([weight for weight in edge_weights[node].values()])
return node_weights
def getBestPartition(self, graph, param=1.):
node2com, edge_weights = self._setNode2Com(graph) #获取节点和边
node2com = self._runFirstPhase(node2com, edge_weights, param)
best_modularity = self.computeModularity(node2com, edge_weights, param)
partition = node2com.copy()
new_node2com, new_edge_weights = self._runSecondPhase(node2com, edge_weights)
while True:
new_node2com = self._runFirstPhase(new_node2com, new_edge_weights, param)
modularity = self.computeModularity(new_node2com, new_edge_weights, param)
if abs(best_modularity - modularity) < self.MIN_VALUE:
break
best_modularity = modularity
partition = self._updatePartition(new_node2com, partition)
_new_node2com, _new_edge_weights = self._runSecondPhase(new_node2com, new_edge_weights)
new_node2com = _new_node2com
new_edge_weights = _new_edge_weights
return partition
def computeModularity(self, node2com, edge_weights, param):
q = 0
all_edge_weights = sum(
[weight for start in edge_weights.keys() for end, weight in edge_weights[start].items()]) / 2
com2node = defaultdict(list)
for node, com_id in node2com.items():
com2node[com_id].append(node)
for com_id, nodes in com2node.items():
node_combinations = list(combinations(nodes, 2)) + [(node, node) for node in nodes]
cluster_weight = sum([edge_weights[node_pair[0]][node_pair[1]] for node_pair in node_combinations])
tot = self.getDegreeOfCluster(nodes, node2com, edge_weights)
q += (cluster_weight / (2 * all_edge_weights)) - param * ((tot / (2 * all_edge_weights)) ** 2)
return q
def getDegreeOfCluster(self, nodes, node2com, edge_weights):
weight = sum([sum(list(edge_weights[n].values())) for n in nodes])
return weight
def _updatePartition(self, new_node2com, partition):
reverse_partition = defaultdict(list)
for node, com_id in partition.items():
reverse_partition[com_id].append(node)
for old_com_id, new_com_id in new_node2com.items():
for old_com in reverse_partition[old_com_id]:
partition[old_com] = new_com_id
return partition
def _runFirstPhase(self, node2com, edge_weights, param):
# 计算所有边上的权重之和
all_edge_weights = sum(
[weight for start in edge_weights.keys() for end, weight in edge_weights[start].items()]) / 2
self.node_weights = self.updateNodeWeights(edge_weights) #输出一个字典,每个node对应node上边的权重和
status = True
while status:
statuses = []
for node in node2com.keys(): # 逐一选择节点和周边连接的节点进行比较
statuses = []
com_id = node2com[node] # 获取节点对应的社团编号
neigh_nodes = [edge[0] for edge in self.getNeighborNodes(node, edge_weights)] #获取连接的所有边节点
max_delta = 0. # 用于计算比对
max_com_id = com_id # 默认当前社团id为最大社团id
communities = {}
for neigh_node in neigh_nodes:
node2com_copy = node2com.copy()
if node2com_copy[neigh_node] in communities:
continue
communities[node2com_copy[neigh_node]] = 1
node2com_copy[node] = node2com_copy[neigh_node] # 把node对应的社团id放到临近的neigh_node中
delta_q = 2 * self.getNodeWeightInCluster(node, node2com_copy, edge_weights) - (self.getTotWeight(
node, node2com_copy, edge_weights) * self.node_weights[node] / all_edge_weights) * param
if delta_q > max_delta:
max_delta = delta_q # max_delta 选择最大的增益的node
max_com_id = node2com_copy[neigh_node] # 对应 max_com_id 选择最大的增益的临接node的id
node2com[node] = max_com_id
statuses.append(com_id != max_com_id)
if sum(statuses) == 0:
break
return node2com
def _runSecondPhase(self, node2com, edge_weights):
"""
:param node2com: 第一层phase 构建完之后的node->社团结果
:param edge_weights: 社团边字典
:return:
"""
com2node = defaultdict(list)
new_node2com = {}
new_edge_weights = defaultdict(lambda: defaultdict(float))
for node, com_id in node2com.items():
#生成了社团:--->节点映射
com2node[com_id].append(node) #添加同一一个社团id对应的node
if com_id not in new_node2com:
new_node2com[com_id] = com_id
nodes = list(node2com.keys())
node_pairs = list(permutations(nodes, 2)) + [(node, node) for node in nodes]
for edge in node_pairs:
new_edge_weights[new_node2com[node2com[edge[0]]]][new_node2com[node2com[edge[1]]]] += edge_weights[edge[0]][
edge[1]]
return new_node2com, new_edge_weights
def getTotWeight(self, node, node2com, edge_weights):
"""
:param node:
:param node2com:
:param edge_weights:
:return:
"""
nodes = [n for n, com_id in node2com.items() if com_id == node2com[node] and node != n]
weight = 0.
for n in nodes:
weight += sum(list(edge_weights[n].values()))
return weight
def getNeighborNodes(self, node, edge_weights):
"""
:param node: 输入节点
:param edge_weights: 边字典
:return: 输出每个节点连接点边集合
"""
if node not in edge_weights:
return 0
return edge_weights[node].items()
def getNodeWeightInCluster(self, node, node2com, edge_weights):
neigh_nodes = self.getNeighborNodes(node, edge_weights)
node_com = node2com[node]
weights = 0.
for neigh_node in neigh_nodes:
if node_com == node2com[neigh_node[0]]:
weights += neigh_node[1]
return weights
def _setNode2Com(self,graph):
"""
:return: 节点->团,edge_weights 形式:{'a': defaultdict(<class 'float'>, {'c': 1.0, 'b': 1.0})}
"""
node2com = {}
edge_weights = defaultdict(lambda: defaultdict(float))
for idx,node in enumerate(graph.nodes()):
node2com[node] = idx #给每一个节点初始化赋值一个团id
for edge in graph[node].items():
edge_weights[node][edge[0]] = edge[1]['weight']
return node2com,edge_weights
4.2 算法测试:
测试:
import networkx as nx
from fast_unfolding import *
import matplotlib.pyplot as plt
from collections import defaultdict
import random
def makeSampleGraph():
'''
生成图
'''
g = nx.Graph()
g.add_edge("a", "b", weight=1.)
g.add_edge("a", "c", weight=1.)
g.add_edge("b", "c", weight=1.)
g.add_edge("b", "d", weight=1.)
return g
def random_Graph():
'''
生成随机图
'''
g = nx.Graph()
node_num = random.randint(10, 15)
node_chars = [chr(ord('a')+i) for i in range(node_num)]
for n in node_chars:
g.add_node(n)
for _ in range(20):
v = random.sample(node_chars, 2)
w = 1
while w==1 or w==0:
w = round(random.random(), 2)
g.add_edge(v[0], v[1], weight=w)
return g
if __name__ == "__main__":
# sample_graph = makeSampleGraph()
sample_graph = random_Graph()
print(sample_graph.nodes,sample_graph.edges)
print(sample_graph['a'])
louvain = Louvain()
partition = louvain.getBestPartition(sample_graph)
p = defaultdict(list)
for node, com_id in partition.items():
p[com_id].append(node)
for com, nodes in p.items():
print(com, nodes)
edge_labels=dict([((u,v,),d['weight']) for u,v,d in sample_graph.edges(data=True)])
pos=nx.spring_layout(sample_graph)
nx.draw_networkx_edge_labels(sample_graph,pos,edge_labels=edge_labels)
# print(edge_labels)
nx.draw_networkx(sample_graph,pos)
plt.show()
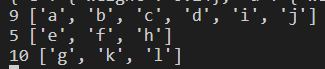
4.3 测试结果:
生成的随机图:

测试结果: