本文为 scikit-learn机器学习(第2版)学习笔记
K 近邻法(K-Nearest Neighbor, K-NN) 常用于 搜索和推荐系统。
1. KNN模型
- 确定距离度量方法(如欧氏距离)
- 根据 K 个最近的距离的邻居样本,选择策略做出预测
- 模型假设:距离相近的样本,有接近的响应值
2. KNN分类
根据身高、体重对性别进行分类
import numpy as np
import matplotlib.pyplot as plt
X_train = np.array([
[158, 64],
[170, 86],
[183, 84],
[191, 80],
[155, 49],
[163, 59],
[180, 67],
[158, 54],
[170, 67]
])
y_train = ['male', 'male', 'male', 'male', 'female', 'female', 'female', 'female', 'female']
plt.figure()
plt.title('Human Heights and Weights by Sex')
plt.xlabel('Height in cm')
plt.ylabel('Weight in kg')
for i, x in enumerate(X_train):
if y_train[i] == 'male':
c1 = plt.scatter(x[0], x[1], c='k', marker='x')
else:
c2 = plt.scatter(x[0], x[1], c='r', marker='o')
plt.grid(True)
plt.legend((c1,c2),('male','female'),loc='lower right')
# plt.show()
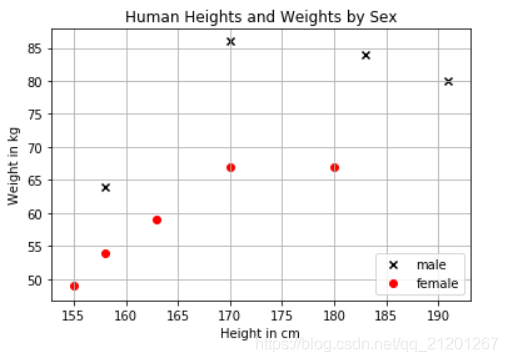
- 对身高 155cm,体重 70 kg的人进行性别预测
- 设置 KNN 模型 k = 3
计算距离
x = np.array([[155,70]])
dis = np.sqrt(np.sum((X_train-x)**2 ,axis = 1))
dis
选取最近k个
nearset_k_neighbor = dis.argsort()[0:3]
k_genders = [y_train[i] for i in nearset_k_neighbor]
k_genders # ['male', 'female', 'female']
计算最近的k个的标签
from collections import Counter
# b = Counter(np.take(y_train, dis.argsort()[0:3]))
b = Counter(k_genders)
b # Counter({'male': 1, 'female': 2})
性别为女性占多数
# help(Counter.most_common)
# most_common(self, n=None)
# List the n most common elements and their counts from the most
# common to the least. If n is None, then list all element counts.
b.most_common(2) # [('female', 2), ('male', 1)]
b.most_common(1)[0][0] # 'female'
3. 使用sklearn KNN分类
标签(male,female)数字化(0,1)
from sklearn.preprocessing import LabelBinarizer
from sklearn.neighbors import KNeighborsClassifier
lb = LabelBinarizer()
y_train_lb = lb.fit_transform(y_train)
y_train_lb
######
array([[1],
[1],
[1],
[1],
[0],
[0],
[0],
[0],
[0]])
预测前面的例子的性别
K=3
clf = KNeighborsClassifier(n_neighbors=K)
clf.fit(X_train,y_train_lb.ravel())
pred_gender = clf.predict(x)
pred_gender # array([0])
pred_label_gender = lb.inverse_transform(pred_gender)
pred_label_gender # array(['female'], dtype='<U6')
在test集上验证
X_test = np.array([
[168, 65],
[180, 96],
[160, 52],
[169, 67]
])
y_test = ['male', 'male', 'female', 'female']
y_test_lb = lb.transform(y_test)
pred_lb = clf.predict(X_test)
print('Predicted labels: %s' % lb.inverse_transform(pred_lb))
# Predicted labels: ['female' 'male' 'female' 'female']
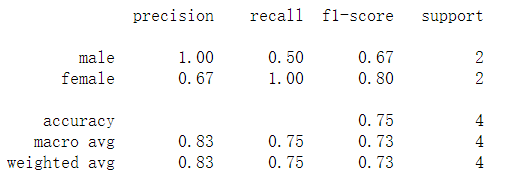
计算评价指标
准确率:预测对了的比例3/4
from sklearn.metrics import accuracy_score
accuracy_score(y_test_lb, pred_lb) # 0.75
精准率:正类为男,男预测为男/(男预测男+女预测男)
from sklearn.metrics import precision_score
precision_score(y_test_lb, pred_lb) # 1.0
召回率: 男预测男/(男预测男+男预测女)
from sklearn.metrics import recall_score
recall_score(y_test_lb, pred_lb) # 0.5
F1 得分是:精准率和召回率的均衡
from sklearn.metrics import f1_score
f1_score(y_test_lb, pred_lb) # 0.6667
评价报告
from sklearn.metrics import classification_report
# help(classification_report)
# classification_report(y_true, y_pred, labels=None, target_names=None, s
# ample_weight=None, digits=2, output_dict=False, zero_division='warn')
print(classification_report(y_test_lb, pred_lb, target_names=['male','female'], labels=[1,0]))
4. KNN回归
根据身高、性别,预测其体重
from sklearn.neighbors import KNeighborsRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error,r2_score
X_train = np.array([
[158, 1],
[170, 1],
[183, 1],
[191, 1],
[155, 0],
[163, 0],
[180, 0],
[158, 0],
[170, 0]
])
y_train = [64,86,84,80,49,59,67,54,67]
X_test = np.array([
[168, 1],
[180, 1],
[160, 0],
[169, 0]
])
y_test = [65,96,52,67]
K = 3
clf = KNeighborsRegressor(n_neighbors=K)
clf.fit(X_train, y_train)
predictions = clf.predict(np.array(X_test))
predictions # array([70.66666667, 79. , 59. , 70.66666667])
# help(r2_score)
# R^2 (coefficient of determination)
r2_score(y_test, predictions) # 0.6290565226735438
平均绝对值误差
mean_absolute_error(y_test, predictions) # 8.333333333333336
平均平方误差
mean_squared_error(y_test, predictions) # 95.8888888888889
- 数据没有标准化的影响
from scipy.spatial.distance import euclidean
# help(euclidean) # 欧氏距离
X_train = np.array([
[1700,1],
[1600,0]
])
X_test = np.array([1640,1]).reshape(1,-1)
print(euclidean(X_train[0,:], X_test))
print(euclidean(X_train[1,:], X_test))
# 60.0
# 40.01249804748511
X_train = np.array([
[1.7,1],
[1.6,0]
])
X_test = np.array([1.64,1]).reshape(1,-1)
print(euclidean(X_train[0,:], X_test))
print(euclidean(X_train[1,:], X_test))
# 0.06000000000000005
# 1.0007996802557444
可以看出不同单位下的欧式距离差异很大
- 进行数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
print(X_train)
print(X_train_scaled)
[[158 1]
[170 1]
[183 1]
[191 1]
[155 0]
[163 0]
[180 0]
[158 0]
[170 0]]
[[-0.9908706 1.11803399]
[ 0.01869567 1.11803399]
[ 1.11239246 1.11803399]
[ 1.78543664 1.11803399]
[-1.24326216 -0.89442719]
[-0.57021798 -0.89442719]
[ 0.86000089 -0.89442719]
[-0.9908706 -0.89442719]
[ 0.01869567 -0.89442719]]
- 标准化特征后 模型误差更低
pred = clf.predict(X_test_scaled)
pred # array([78. , 83.33333333, 54. , 64.33333333])
# R^2 (coefficient of determination)
r2_score(y_test, pred) # 0.6706425961745109
# 平均绝对值误差
mean_absolute_error(y_test, pred) # 7.583333333333336
# 平均平方误差
mean_squared_error(y_test, pred) # 85.13888888888893