综述
在Kafka中,topic是逻辑上的概念,而partition是物理上的概念。不用担心,这些对用户来说是透明的。 生产者(producer)只关心自己将消息发布到哪个topic,而消费者(consumer)只关心自己订阅了哪个topic上的消息,至少topic上的消息分布在哪些partition节点上,它本身并不关心。
设想一下,如果在Kafka中没有分区的话,那么topic的消息集合将集中于某一台服务器上,单节点的存储性能将马上成为瓶颈,当访问该topic存取数据时,吞吐也将成为瓶颈。
介于此,kafka的设计方案是,生产者在生产数据的时候,可以为每条消息人为地指定key,这样消息被发送到broker时,会根据分区规则选择消息将被存储到哪一个分区中。如果分区规则设置合理,那么所有的消息将会被均匀/线性的分布到不同的分区中,这样就实现了负载均衡和水平扩展。
另外,在消费者端,同一个消费组可以多线程并发的从多个分区中同时消费数据。
上述分区规则,实际上是实现了 org.apache.kafka.clients.producer.Partitioner 接口,这个实现类可以根据自己的业务规则进行自定义制定分区,如根据hash算法指定分区的分布规则。
比如在以下的案例类中,我们先获取key的hashcode值,再跟分区数量partitionsNum-1做模运算,结果值作为分区存储位置,这样可以实现数据均匀线性的分布。
下面我们以一个小的案例来介绍Kafka自定义分区器的使用。
1、 创建Maven工程,导入以下依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.0</version>
</dependency>
2、 编写自定义分区器类,实现Partitioner接口
package com.xsluo;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import org.apache.kafka.common.PartitionInfo;
import java.util.List;
import java.util.Map;
/**
* @author:xsluo
* @date:2020/7/10
* @aim:自定义分区器
*/
public class MyPartitioner implements Partitioner {
/**
* 自定义kafka分区主要解决用户分区数据倾斜问题 提高并发效率(假设 3 分区)
* @param topic 消息队列名
* @param key 用户传入key
* @param keyBytes key字节数组
* @param value 用户传入value
* @param valueBytes value字节数组
* @param cluster 当前kafka节点数
* @return 如果3个分区,返回 0 1 2
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
//获取topic的partitions信息
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(topic);
int partitionsNum = partitionInfos.size();
//为特定的key自定义分区规则
if (key.toString().equals("key666") || key.toString().equals("key888")) {
//分配到最后一个分区
return partitionsNum - 1;
}
//其它的key采用默认分区规则
return key.toString().hashCode() % (partitionsNum - 1);
// return key.toString().hashCode() % (partitionsNum);
}
public void close() {
}
public void configure(Map<String, ?> map) {
}
}
3、 编写一个Kafka生产者来使用自定义分区器
package com.xsluo;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.Random;
import java.util.concurrent.ExecutionException;
/**
* @author:xsluo
* @date:2020/7/10
* @aim:测试自定义分区器
*/
public class MyProducer {
private final static String[] allKeys = new String[]{
"k100",
"k101",
"k102",
"k103",
"k104",
"key666",
"key666",
"key888",
"key888",
"key888",
"key666",
"key666",
"k105",
"k106",
"k107",
"k108",
"k109"
};
public static void main(String[] args) throws ExecutionException, InterruptedException {
//定义配置信息
Properties props = new Properties();
//kafka地址,多个地址用逗号分隔
props.put("bootstrap.servers", "weekend110:9092,weekend01:9092,weekend02:9092");
props.put("acks", "all");// 记录完整提交,最慢的但是最大可能的持久化
props.put("retries", 3);// 请求失败重试的次数
props.put("batch.size", 16384);// batch的大小
props.put("linger.ms", 1);// 默认情况即使缓冲区有剩余的空间,也会立即发送请求,设置一段时间用来等待从而将缓冲区填的更多,单位为毫秒,producer发送数据会延迟1ms,可以减少发送到kafka服务器的请求数据
props.put("buffer.memory", 33554432);// 提供给生产者缓冲内存总量
//设置分区器
props.put("partitioner.class", "com.xsluo.MyPartitioner");
//设置序列化类,可以写类的全路径
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int length = allKeys.length;
for (int i = 0; i < 20; i++) {
Random random = new Random();
String oneKey = allKeys[random.nextInt(length)];
// 三个参数分别为topic, key,value,send()是异步的,添加到缓冲区立即返回,更高效。
ProducerRecord<String, String> record = new ProducerRecord<String, String>("topic-Test", oneKey, oneKey);
producer.send(record);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
producer.close();
}
}
4、 编写一个消费者来消费数据
package com.xsluo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* @author:xsluo
* @date:2020/7/10
* @aim:消费者:读取kafka数据
*/
public class MyConsumer {
private static KafkaConsumer<String, String> consumer;
private final static String TOPIC = "topic-Test";
public MyConsumer(){
Properties props = new Properties();
props.put("bootstrap.servers", "weekend110:9092,weekend01:9092,weekend02:9092");
//每个消费者分配独立的组号
props.put("group.id", "g2");
//如果value合法,则自动提交偏移量
props.put("enable.auto.commit", "true");
//设置多久一次更新被消费消息的偏移量
props.put("auto.commit.interval.ms", "1000");
//设置会话响应的时间,超过这个时间kafka可以选择放弃消费或者消费下一条消息
props.put("session.timeout.ms", "30000");
//自动重置offset
//earliest 在偏移量无效的情况下 消费者将从起始位置读取分区的记录
//latest 在偏移量无效的情况下 消费者将从最新位置读取分区的记录
props.put("auto.offset.reset","earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<String, String>(props);
}
public void consume() throws Exception {
//消费消息
consumer.subscribe(Arrays.asList(TOPIC));
try {
while (true){
//拉取records
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("partition = %d , offset = %d, key = %s, value = %s", record.partition(),
record.offset(), record.key(), record.value());
System.out.println();
}
}
} finally {
consumer.close();
}
}
public static void main(String[] args) throws Exception {
new MyConsumer().consume();
}
}
5、 创建测试用的topic和指定分区数(这里为topic指定3个分区)
bin/kafka-topics.sh --create --zookeeper weekend110:2181,weekend01:2181,weekend02:2181 --replication-factor 2 --partitions 3 --topic topic-Test
./bin/kafka-topics.sh --zookeeper weekend110:2181,weekend01:2181,weekend02:2181 --describe --topic topic-Test

6、分别运行生产者和消费者代码并查看测试结果
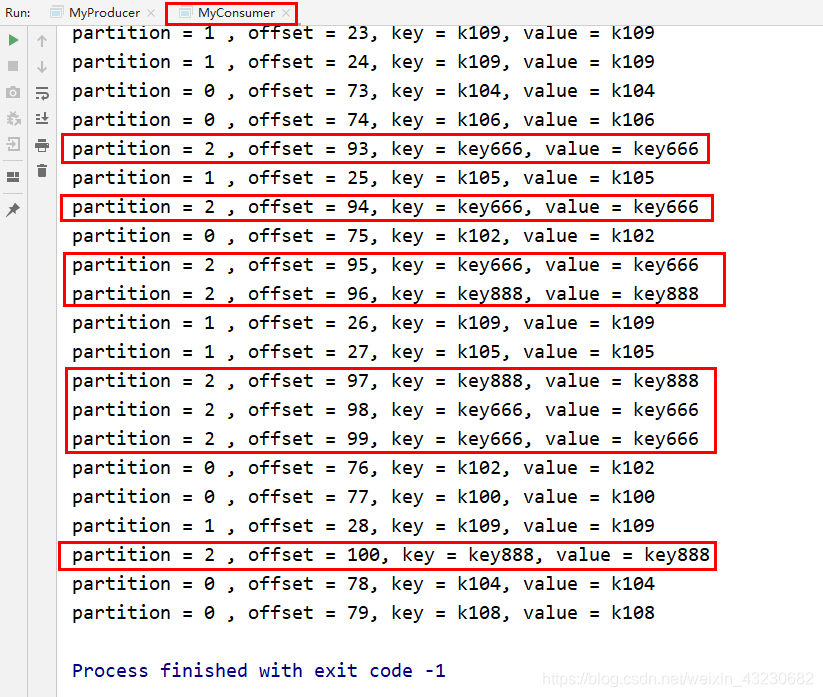
可见,被指定的key666和key888消息都被分配到了“2”号分区。

测试完毕。