文章目录
译者注
这篇论文在MS COCO和UAVDT上都取得了很好的效果,是目前的state-of-the-art。该文章的方法是two-stage的,但是在分类方面却使用了anchor-free的方式计算位置偏移量,并且使用实例分割参与了目标定位的修正,这点想法非常有趣。另外在分类方面,该文章提出了判别性特征并不是等距地分布在图像上,并且引入变形卷积来获得对分类有帮助的判别性特征。总的来说,这篇工作对于目标检测的定位和分类任务都提出了比较好的方法,也取得比较好的效果,值得一读。
论文:D2Det: Towards High Quality Object Detection and Instance Segmentation
github:https://github.com/JialeCao001/D2Det
摘要
我们提出了一个新颖的two-stage检测方法——D2Det,这个方法同时解决了精确定位和准确分类。对于精确定位,我们引入了一种dense local reression方法(密集局部回归,此处翻译采用了直译,但为避免出现歧义,此类名词后面都将使用原英文),这种方法是用来预测每一个目标候选框的多个dense box offsets(密集的框位置偏移量)。与采用传统回归和记于关键点定位的two-stage方法不同的是,我们的dense local regression不仅仅在一个固定区域去量化一系列的关键点,而且能够回归位置敏感的真实dense offsets值,这样会使定位更加精确。dense local regression还使用一种binary overlap prediction(二值交叠预测)策略,binary overlap prediction策略可以减少背景区域对于最后位置偏移量回归时的影响。对于准确分类,我们引入了一种discriminative RoI pooling scheme(判别性RoI池化方法),对一个候选区域来说,它可以从不同的子区域采样,然后计算时赋予自适应权重,得到判别性特征。
在MS COCO test-dev上,我们的D2Det的单模型使用ResNet101作为主干网络,其表现以45.4AP超过了之前所有的two-stage方法。当进行多尺度训练和推理时,D2Det获得了50.1的AP。除了检测之外,我们将D2Det用于语义分割,也获得了40.2的mask AP,并且在速度方面,比state-of-the-art快了2倍。我们也阐述了D2Det在航空遥感图像上的有效性,这一部分在UAV图片上的目标检测实验和在卫星图像上的语义分割实验可以看到。
引言
近些年,目标检测领域取得了长足的进步,这可以归功于深度神经网络的发展。现代目标检测可以大致分为single-stage和two-stage方法。two-stage检测方法的步骤是:首先生成一系列的候选框,然后对这些候选框进行分类和回归。另一方面,single-stage方法是:在图片上进行规则的网格采样,然后对这些采样出来的默认框进行回归和分类。通常来说,在标准benchmarks的准确率上,two-stage方法要优于single-stage方法。
高质量目标检测要求定位精准和分类准确。之前大部分two-stage检测算法在定位部分都采用了相似的设计。大部分two-stage算法选择一种比较经典设计:回归模型,例如有流行的Faster R-CNN。这种回归模型使用了少量的全连接层去预测一系列候选框的偏移量。最近,Grid R-CNN把回归和预测分离到两个分支上,扩展了Faster R-CNN,因为Faster R-CNN使用的是共享网络。相比于Faster R-CNN使用回归来修正定位,Grid R-CNN则引进了一种基于全卷积网络的定位策略,这种策略是在固定大小的区域寻找系列关键点去识别目标边界。
在这篇文章中,我们引入了dense local regression进行精确定位。不同于Faster R-CNN中所采用的使用全连接层去预测偏移量的传统回归策略,我们的dense local regression使用全卷积网络预测多个局部框的偏移量(local box offsets),也叫作dense box offsets。相比于Grid R-CNN使用基于关键点的定位,我们的dense local regression可以更精确地定位目标,原因在于它能够回归任意偏移量的真实值,因此不会局限于固定大小的区域去量化关键点。此外,虽然Grid R-CNN提高了定位能力,但是我们的方法不仅可以精确定位目标,而且集成了更强的目标分类能力。对于分类,我们引入了一种discriminative RoI pooling,它抽取候选区域的不同子区域的特征,然后计算时赋予自适应权重,得到判别性特征。
贡献点
我们提出了一种two-stage检测方案——D2Det,该方法实现了目标的精确定位和准确分类。对于精确目标定位,我们引入了一种dense local regression,这种方法可以对一个候选框的每个子区域预测其每个子区域自己的box offsets(与ground-truth相比的四个方向上的偏移量)。因此,多个dense local box offsets是由全卷积网络得到的,对于box offsets预测来说,这样可以保留位置敏感性特征。为了更进一步提高我们dense local regression能力,我们还引入了一种binary overlap prediction,它可以识别一个候选框的每个子区域是属于目标区域还是属于背景区域,这样就可以减少背景区域的影响。binary overlap prediction的训练需要假设ground-truth里所有的区域都属于目标。对于目标的准确分类来说,我们引入了一种discriminative RoI pooling,它抽取候选区域的不同子区域的特征,然后计算时赋予自适应权重,得到判别性特征。
实验使用的数据集是MS COCO和UAVDT。我们D2Det在这些数据集上达到了新的state-of-the-art。在MS COCO test-dev上,就单模型精度来说,我们的方法超过了之前的所有two-stage方法,使用ResNet101作为backbone达到了45.4的COCO style AP。更进一步来说,相比于state-of-the-art,我们的方法在[email protected]上比他们高了3.0%,这足以说明我们方法的定位能力。而且D2Det使用更强的backbone进行多尺度训练和推理时,达到了50.1的COCO style AP。除此之外,在调整我们检测方法的dense local regression分支和使用实例mask标注之后,我们还对语义分割的结果做了报告。在两个语义分割数据集(MS COCO和最近的iSAID)上,我们做了相关实验。我们的方法在这两个数据集上,比之前的方法也获得了明显的进步。在MS COCO test-dev上,我们的方法比state-of-the-art方法HTC快了两倍,并且达到了40.2的MASK AP。
相关工作
近些年,two-stage检测方法的检测精度在标准benchmarks上持续提升。在之前的two-stage检测方法中,Faster R-CNN是最流行的目标检测框架之一。在第一阶段,Faster R-CNN使用region proposal network(RPN)生成类别不可知的region proposal(区域候选框)。第二阶段,与Fast R-CNN的做法相似,抽取固定大小区域(RoI)的特征表示,然后再去计算类别置信度和每一个框(proposal bounding-box)坐标位置的回归。最近的一些工作通过其他方法拓展Faster R-CNN框架,例如有增加特征金字塔表示、多阶段检测和集成一个掩膜(mask for instance segmentation)分支等。
大部分two-stage检测器都是使用预定义好的anchor box来表示图像上的每一个目标。还有另外一种就是single-stage方法使用anchor box free的策略,放弃了anchor box表示。这通常涉及到使用成对的关键点和关键点估计去检测目标的bounding-box。这些方法是自底向上的,因为关键点的生成通常是基于整张图像的,而非预定义好的目标实例。不同于这些自底向上的方法,Grid R-CNN是自上而下的two-stage方法,它首先定义实例,然后使用grid guided keypoint-based localization(基于关键点的网格引导定位)生成bounding-box的关键点。这种策略在一个固定大小的区域内寻找一系列的关键点去识别目标边界。然而,即使扩展了映射区域可能无法囊括整个目标,这要看与ground-truth相对应的proposal的位置。具体来说,在一个固定分辨率的特征空间中(56*56)寻找关键点,这样对于大目标来说可能会有问题。比如说有这样一个例子,有一幅图像,其目标大小都是大于100*100,那么与其相关的关键点搜索空间比较小的话会导致定位失准。而且Grid R-CNN只关注提升定位能力,而对分类分支不做改变,仍然使用与Faster R-CNN相似的方法。在MS COCO上,我们的dense local regression(不加上对分类分支的改进)对于大目标的检测,比Grid R-CNN提升了3.7%。
最初的Faster R-CNN使用RoI Pool去对候选框进行特征的固定池化。近来,RoIAlign在一些工作中取代了RoIPool,包括最近的Faster R-CNN的变体和Grid R-CNN。RoIAlign把候选框均等分成多个子区域,并考虑子区域里的特征。在每个子区域内获得4个采样点,并对所有采样点分配相等的权值进行平均。这可能会降低分类性能,因为区分区域可能不会出现在等距的子区域中。与RoIAlign不同,变形RoI pooling从候选方案的各个子区域中获得分类和回归所使用的特征,而不考虑它们之间的距离。在这里,我们介绍一种方法,执行自适应加权,以增强区分特征分类。
我们的方法
我们的方法是基于标准Faster R-CNN框架。在我们的方法中,proposed dense local regression代替了Faster R-CNN中传统的box offset regression,而分类则使用discriminative RoI pooling进行改进。我们的two-stage检测框架的整体结构如图2(a)所示。在第一阶段,我们使用RPN(region proposal network);在第二阶段,我们使用两个独立的分类和回归分支(图2(b))。dense local regression分支用于精确定位目标,而基于disriminative RoI pooling(图2(c))的分类分支则对proposal的分类准确性有帮助。

3.1 Dense Local Regression
在一个two-stage检测框架中,bounding-box regression branch的目标是找到一个贴近目标周围的框。令P(xP,yP,wP,hP)是一个目标候选框,且G(xG,yG,wG,hG)是目标ground-truth。Faster R-CNN中传统regression预测单个框的偏移量(∆x,∆y,∆w,∆h):
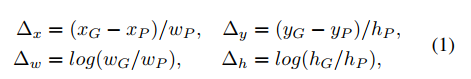
这里的(x,y)代表框的中心,(w,h)代表给定框的宽和高。对于每一个候选框P,特征池化策略例如RoIPool或者RoIAlign,都可以用来从proposal中相等大小的k*k子区域获得对应的固定大小的RoI特征。标准的Faster R-CNN把这些RoI特征当做一个向量,被称作全局特征表示,然后传入一些全连接层预测一个全局框的偏移量。
不同于前面提到的策略,我们的dense local regression方法把k*k维的RoI特征当做k2 空间邻接局部特征。一个局部特征如图2(b)的pi所示。然后这些局部RoI特征传入全卷积网络去预测多个local box offsets,被称作dense box offsets。dense box offsets表示每一个局部特征pi在(xi,yi)处到ground-truth bounding box G的左上角和右下角的距离。令(xl, yt)和(xr,yb)表示ground-truth bounding box的左上角和右下角。

与ground-truth bounding box对应的proposal的子区域或者局部特征的数量取决于proposal和其对应的ground-truth的交叠度的大小。但是即使在很高交叠度的情况下(大部分的k2局部特征属于对应的ground-truth bounding box),依然会存在一些不需要的特征(例如背景特征)。因此,这些背景特征会降低dense box offsets的精度,需要另外的方法来抑制这些不需要的特征。为了达到这个目标,我们将在dense local regression内引入binary overlap prediction来分辨每一个局部特征是属于ground-truth bounding box区域还是背景,如图2(a)绿色的部分和图2(b)所示。这个binary overlap prediction要引入一个额外的输出 m ^ \widehat m m
,和dense box offsets一起。ground-truth bounding box G和proposal P之间的交叠区域中的局部特征按照如下方式分配ground-truth 标签1。
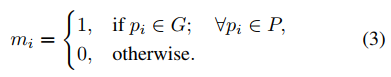
由于在通用目标检测中的ground-truth像素级实例模板不可用,我们假设ground-truth bounding box G的所有区域都是目标。
和 m = {mi:i∈[1, k2]}。在训练时,binary overlap prediction 在位置i处的 m ^ i \widehat m_i m
i传入sigmoid函数(σ),用来与ground-truth label mi计算二值交叉熵损失。


3.2 Discriminative RoI Pooling
这里,我们描述discriminative RoI pooling(图2©)在我们的分类分支。不同于回归,分类任务需要高判别性特征。discriminative RoI pooling的创新是受到了变形卷积的启发,通过以下两种方式提高分类性能。首先,我们使用轻量化权重的偏移量预测,与变形RoI池化中的标准便宜预测相比,只有其1/4的参数量。这个标准偏移量预测使用了RoIAlign操作来从k*k的子区域来获得特征,然后再将这些特征传入三个全连接层。相反,轻量化权重偏移量预测只使用一个大小为(k/2) * (k/2)的RoI,再连接全连接层(轻量化权重是因为输入的向量更小)。
在预测偏移量以后, 标准的变形RoI池化使用RoIAlign, 每个子区域得到四个采样点,然后给它们分配相同的权重再平均。相比较之下,我们的weighted pooling适应性地给更加具备判别性的采样点分配更高的权重。这里,原始采样点下的RoIAlign特征,i.e. F∈R^2k x 2k^ ,被用于预测与其对应的权重W(F) ∈R^2k x 2k^ ,这代表了在所有k x k的空间子区域中采样点的判别性能力。图2©展示了一些采样点和它们对应的自适应权重。一个候选区域的权重RoI特征 F ~ \widetilde F F
通过下面的式子得到:
这里 ⊙ \odot ⊙是哈达玛积,注意到W(F)是从F中使用卷积操作计算得到,而非是固定的权重。因此我们使用一个步长为2的平均池化对 F ~ \widetilde F F
操作,就得到了大小为k * k的discriminative RoI feature。可以将一个候选区域经过discriminative RoI池化后的特征看作是一个一维全局向量,因为在标准Faster R-CNN中,经过最后两个全连接层来得到候选区域的分类结果。
经过偏移量预测和discriminative RoI pooling后,所抽取的特征很可能包含与目标和上下文都相关的判别性特征,这对进一步提高分类性能很有帮助。
3.3 实例分割
我们推荐的方法可以很容易的扩展到实例分割,只需要修改我们的dense local regression 分支。相比于假设所有的regions都在某个目标的ground-truth bounding box G内,这个用于实例分割的ground-truth mask原本是用于标注局部特征pi∈P(见公式3),因此,基于mask的ground-truth binary overlap m 是用于训练binary overlap prediction m ^ \widehat m m 和dense regression分支的偏移量预测。进一步,我们使用两个反卷积层把输出分辨率放大到4倍(i.e. 从77到2828),还会用两个全连接层去有效的给mask打分。我们的方法提供了一种有效的实例分割框架,其表现也是比较好的。
实验
4.1 数据集和实现细节
