日常开发需求中,为了更好排查问题,我们常常需要把多台服务器的日志数据进行集中式收集,一来这样便于集中查看处理日志打印,也更方便我们排查问题,定位问题点。
今天我们主要聊聊如何从Kids到ELK的集中式日志收集方法。
谈谈Kids
首先我们来谈谈Kids是什么?Kids是知乎14年开源的日志收集系统,采用Scribe的消息聚合模型和Redis的pub/sub模型。特点:无第三方依赖,实时订阅,使用Redis协议等。
因为上面这些原因,团队在一开始就把Kids作为主要的集中式日志收集管理平台。
下面是主要的配置步骤:
用docker进行安装(也可以源码安装)客户端及服务端
在客户端应用App代码配置logging handler,配置好对应的应用的日志level,topic。(通过topic配置可以把应用日志各种状态都分类收集起来)
应用App的logging日志打印到kids服务端得到日志文件,实现统一收集
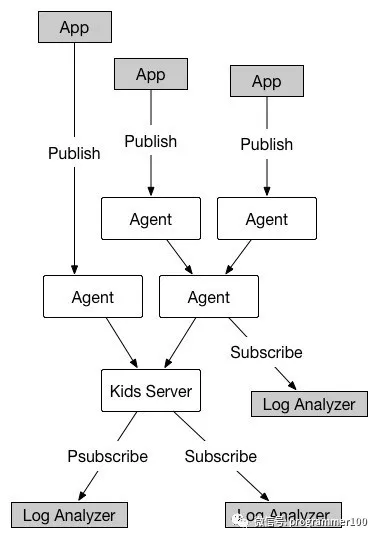
上图来自官方架构图,更多参考:
https://github.com/zhihu/kids/blob/master/README.zh_CN.md
最后上一张日志效果图,其中日志的压缩是运行了自动化shell加密脚本与kids本身无关。

使用ELK+Filebeat收集日志
通过kids配置使用,就能把各个应用日志统一进行收集分析了,但是随着需求越来越多,对日志要求也越来越高,需要各种类型日志来源,需要可视化,需要集中挖掘各个日志数据信息,比如数据库慢查询日志,nginx请求日志,错误日志。这个时候轻量级的Kids系统就有些力不从心了。
这个时候就需要用到ELK+Filebeat这种重量级装备了。
ELK是一个软件集合,由Elasticsearch(简称ES 负责存储搜索聚合),Logstash(数据收集过滤), Kibana(数据分析及可视化)三款开源软件组成,现在已成为目前最为流行的日志解决方案。
而Filebeat是ELK 家族新成员Beats下面分支,一个更轻量级的日志文件收集器,用来替换Logstash,通过Filebeat收集数据更加节约服务器资源。
Filebeat主要场景是在需要采集日志的服务器上面安装服务,指定好对应的日志文件,读取文件数据发送到Logstash解析或者发送到ES,Redis进行存储。
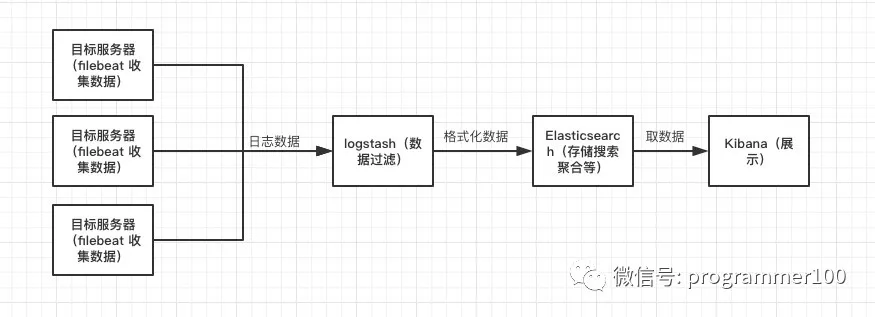
上图是整个日志的流转过程,首先通过从各个服务器收集到的数据发送到logstash集中处理,存储到ES,最后再通过Kibana进行数据展示,生成图表。
知道整个数据流转情况,下面简要讲下Filebeat及Logstash下安装配置过程:
安装配置步骤如下:
使用docker安装指定版本的镜像
配置对应的配置命令挂载指定的路径
使用docker-compose up -d 启动管理容器
# docker-compose.yml
version: '2'
services:
logstash:
image: docker.elastic.co/logstash/logstash:5.6.10
hostname: logstash
container_name: logstash
restart: always
ports:
- "5044:5044"
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
filebeat:
image: docker.elastic.co/beats/filebeat:5.6.10
hostname: filebeat
container_name: filebeat
command: filebeat -e -strict.perms=false # 其中strict.perms=false 表示filebeat忽略权限
restart: always
volumes:
- ./settings/filebeat.yml:/usr/share/filebeat/filebeat.yml
- ./yourselfdir:/usr/share/filebeat/yourselfdir
# 下面是filebeat.yml配置
filebeat.prospectors:
- input_type: log
paths:
- /usr/share/filebeat/yourselfdir/*/*.log
#document_type: 'test1' # 在5.X版本用document_type区分不同日志来源6.0被废弃,使用fields
#fields: # 这里是在6.0版本使用 fields来自定义进行区分来源
#type: test1
#fields_under_root:true #如果自定义字段和原有字段重名,是否覆盖原有字段
#output.elasticsearch:
# hosts: ['xx':9200']
output.logstash:
hosts: ["xx:5044"]
#tail_files: true 默认为false从文件末尾开始读取而不是开始,适用大文件日志读取
-------------
# 下面是 logstash.yml配置
input {
beats {
port => 5044
codec => "json"
add_field => {"myid"=>"nginx"} # 通过logstash特定端口add_field也能区分不同日志来源,相对来说不够优雅
}
}
filter {
if [myid] == "nginx" {
grok {
match => ["message", "%{HTTPDATE:logdate}"]
}
}
date {
match => ["@timestamp", "yyyy-MM-dd HH:mm:ss"]
}
}
output {
if [myid] == "nginx" {
elasticsearch {
hosts => "XX:9200"
manage_template => false
index => "nginx-log-%{+YYYY.MM.dd}"
document_type => "nginx-log"
}
}
}
其中注意的是:ducument_type参数已经在5.5版本建议丢弃,6.0中彻底废弃,使用fields代替,通过fields_under_root属性,替换原始type属性,上面演示了其实通过logstash端口号也能区分不同日志来源。
由于笔者已经装好ES及Kibana,这里就简单罗列了基本日志配置文件(实际生产环境较为复杂),需要注意事项较多,尤其是安全相关认证,数据加密等这些都是重点需要关注的。
通过把不同来源的数据日志进行集中整合及可视化操作,让我们对我们的应用服务了解的更为透彻。
写在后面
开发技术都是在不断变化迭代的,Kids简单方便但功能较单一,ELK复杂臃肿但是功能强大,每个时间点都有适合自己的技术,不是越时髦越好,而是最适合团队业务场景和技术水平。
由于篇幅有限,大家如果有问题可以微信留言或者加我微信pengtaotalk,大家一起探讨。