论文地址:https://arxiv.org/abs/2001.08095
论文总结
本文比较不同的地方就是将ASPP(Atrous Spatial Pyramid Pooling)应用在了pose检测中,通过并行化的不同空洞率的空洞率扩大感受野,最终下采样只在stride=8的地方开始上采样。虽然下采样最大只到了8,但只是ResNet101后两个blocks中的stride=1,这并没有减少卷积的操作,也没有增加运算量(虽然feature map变大了,但channel变少了)在论文展示的网络中,上采样的decoder也只是在stride=8的feature进行直接双线性上采样到输入分辨率。另外,本文的网络输入分辨率为 960 ∗ 720 960*720 960∗720(文中说是 1280 ∗ 720 1280*720 1280∗720,但这个数字对不上),这分辨率对于需要实时性的应用场景来说不实用。也因为网络的输入分辨率不同,其最后的结果展示不一定具有意义。可能本文能展示的另一个意义是,在pose检测中,低分辨率下的feature map不一定有用,所以这种在stride=8上的操作能有效进行。
 Decoder
Decoder
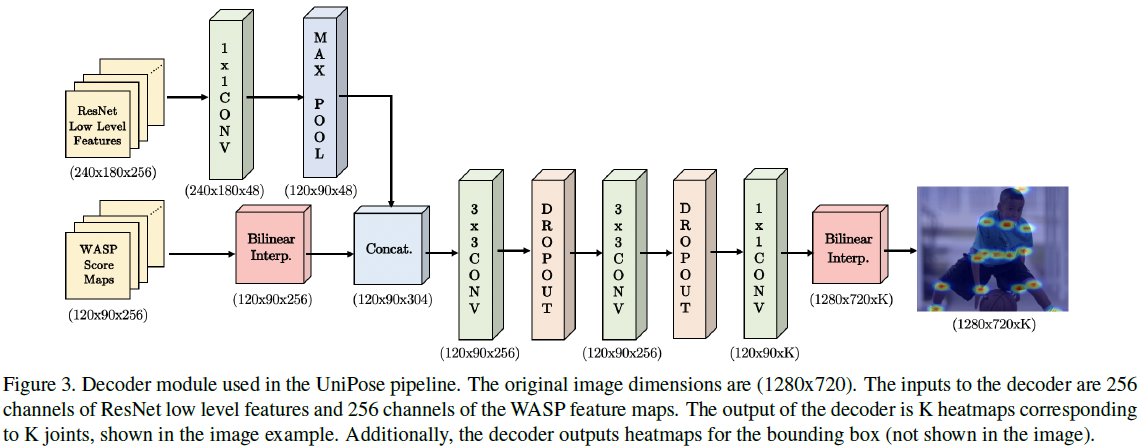
上图中的decoder中的ResNet Low Level Features,是ResNet101中第一个blocks的输出。feature map的size和输入输出的size,最起码有一个数字是错的。 720 / 8 = 90 , 1280 / 8 = 160 720/8=90,1280/8=160 720/8=90,1280/8=160。实际应用中,上图中的最后一层 1 ∗ 1 1*1 1∗1卷积层的输出是 n u m _ c l a s s + 5 + 1 num\_class+5+1 num_class+5+1,也就是文中所说的,融合了分割和bounding box检测,却没有额外的分支。
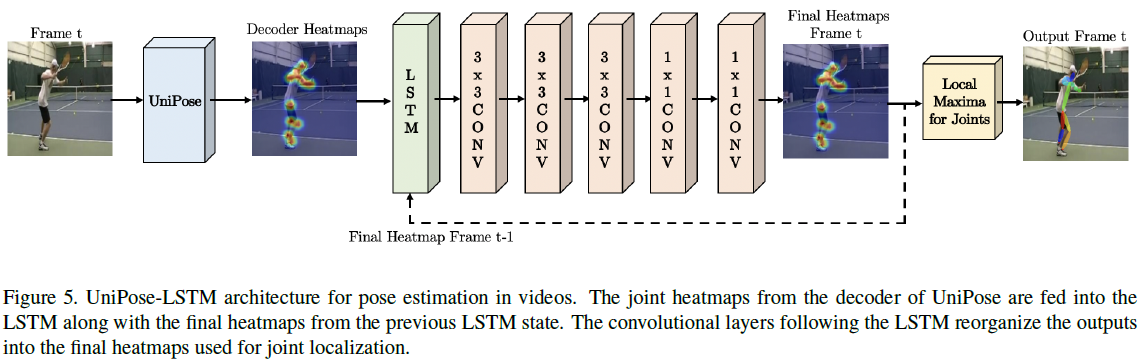
在视频处理上,作者采用LSTM结构,将UniPose扩展成了UniPose-LSTM,来学习融合前面帧的信息,以解决运动模糊的问题和平滑帧预测。文中的LSTM结构输入帧数为5。
论文介绍
UniPose
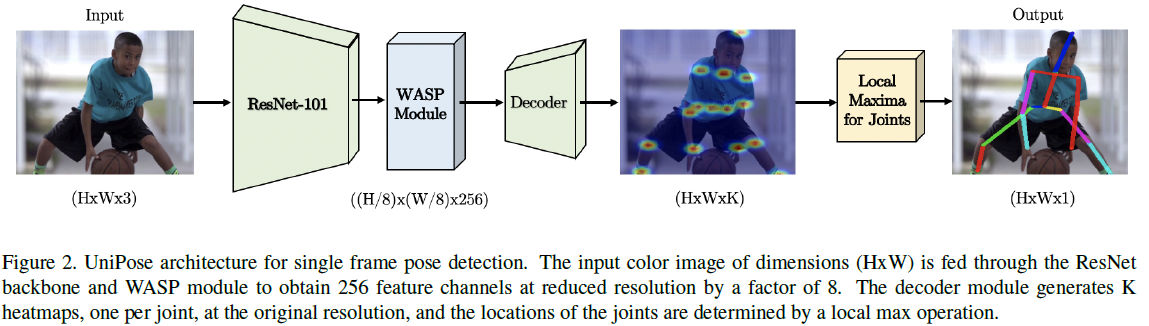
UniPose的网络管道如上面的图所示,ResNet101的最后一层由WASP模块所代替,然后再通过decoder产生heatmaps,最终由softmax产生概率。decoder执行双线性插值恢复原来的分辨率,再接局部最大值操作用于关节定位。网络结构上比较不同的是,UniPose产生一个bounding box预测,但不适用后处理或独立分支。
decoder接收的是WASP产生的 256 256 256通道的score maps,以及来自ResNet第一个blocks产生的256通道low level表示的feature maps。
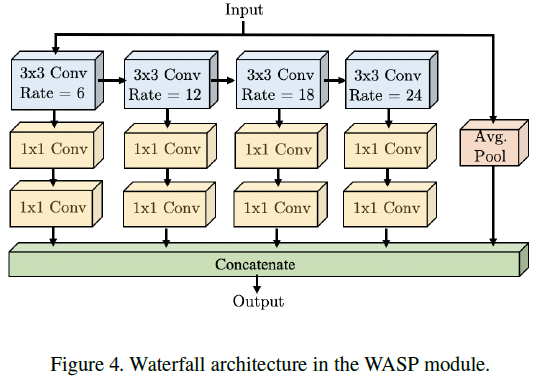
WASP的灵感是合并ASPP、Cascade和Res2Net模块。WSAP所依赖的atrous convolution是ASPP的基础,以维持大的感受野,用不断增加的空洞率来提高效率。WASP有减少参数的目的,以解决内存限制和空洞卷积的主要限制。不同分值的空洞率不同,即不同分值有不同的感受野大小。WASP模块中 4 4 4个空洞卷积的分支,空洞率分辨为 6 / 12 / 18 / 24 6/12/18/24 6/12/18/24。
UniPose-LSTM
将UniPose结合LSTM处理视频帧。LSTM接收的是前一帧的最终heatmap和当前帧decoder产生的heatmap。UniPose-LSTM允许使用先前处理过的帧的信息,而不会显著增加网络总大小。最终使用的历史帧为5帧。
论文实验
原图大小的heatmap,使用的高斯核大小为3,初始学习率为 1 0 − 4 10^{-4} 10−4
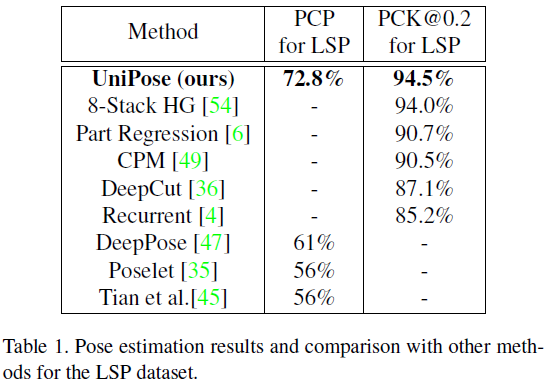
在LSP数据集上的表现为:

在MPII中,使用detectron2用于分割和检测个体,然后用UniPose检测个体pose。


在Penn Action数据集,比当前最好的算法高1.6%:

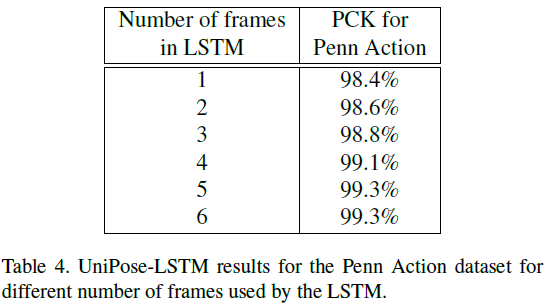
实验不同的数量帧在LSTM下的准确率,帧数的提高是有用的,在帧数为5时达到上升饱和:

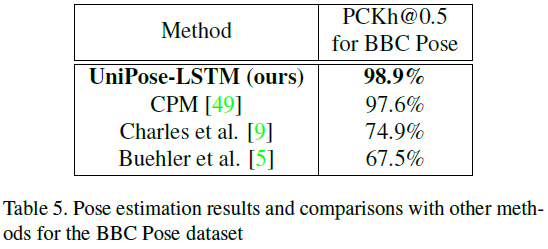
在BBC数据集上的表现: