跳跃表
- 跳跃表(skiplist) 是一种有序数据结构, 它通过在每个节点中维持多个指向其他节点的指针, 从而达到快速访问节点的目的。
- 跳跃表支持平均O(logN) 、 最坏O(N) 复杂度的节点查找, 还可以通过顺序性操作来批量处理节点。
- 在大部分情况下, 跳跃表的效率可以和平衡树相媲美, 并且因为跳跃表的实现比平衡树要来得更为简单, 所以有不少程序都使用跳跃表来代替平衡树。
- Redis使用跳跃表作为有序集合键的底层实现之一, 如果一个有序集合包含的元素数量比较多(默认情况是大于128个使用跳表), 又或者有序集合中元素的成员(member) 是比较长的字符串时, Redis就会使用跳跃表来作为有序集合键的底层实现。
- 在redis的实现中,在有序集合键和集群节点中使用跳表
跳表结构
- zskiplist结构用来保存跳跃表节点的相关信息。
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾节点指针
unsigned long length; // 跳跃表的长度
int level; // 目前跳跃表内,层数最大的节点的层数(不包括头结点)
} zskiplist;
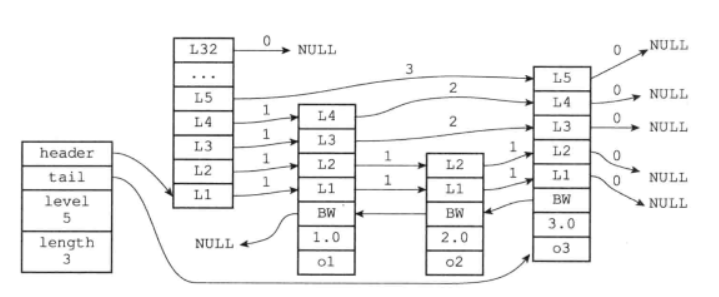
跳表节点结构
- 存储节点的结构与数据,ele就是对应的数据。
typedef char *sds;
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele;
double score; // 分值
struct zskiplistNode *backward; //后退指针
// 跳表的层
struct zskiplistLevel {
struct zskiplistNode *forward; // 前进指针
unsigned long span; // 跨度
} level[];
} zskiplistNode;
-
层
- 跳跃表节点的level数组可以包含多个元素, 每个元素都包含一个指向其他节点的指针,程序可以通过这些层来加快访问其他节点的速度, 一般来说, 层的数量越多, 访问其他节点的速度就越快。
- 每次创建一个新跳跃表节点的时候, 程序都根据幂次定律(power law, 越大的数出现的概率越小) 随机生成一个介于1和32之间的值作为level数组的大小, 这个大小就是层的“高度”。
-
前进指针
- 每个层都有一个指向表尾方向的前进指针(level[i].forward属性) , 用于从表头向表尾方向访问节点。
-
跨度
- 层的跨度(level[i].span属性) 用于记录两个节点之间的距离:
- 两个节点之间的跨度越大, 它们相距得就越远。
- 指向NULL的所有前进指针的跨度都为0, 因为它们没有连向任何节点。
- 初看上去, 很容易以为跨度和遍历操作有关, 但实际上并不是这样, 遍历操作只使用前进指针就可以完成了, 跨度实际上是用来计算排位(rank) 的: 在查找某个节点的过程中,将沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。
-
后退指针
- 节点的后退指针(backward属性) 用于从表尾向表头方向访问节点: 跟可以一次跳过多个节点的前进指针不同, 因为每个节点只有一个后退指针, 所以每次只能后退至前一个节点。
-
分值
- 节点的分值(score属性) 是一个double类型的浮点数, 跳跃表中的所有节点都按分值从小到大来排序。如果分值相同,通过节点的ele成员的字典序排序。
-
SDS
- 节点的成员对象(obj属性) 是一个字符指针, 它指向一个字符串对象。
- 注意,分值可以相同,这个sds对象必须唯一。