机器学习-数据科学库:Pandas总结(1)
Pandas
pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.
pandas的常用数据类型
- Series 一维,带标签数组
- DataFrame 二维,Series容器
pandas之Series创建
In [4]: import pandas as pd
In [5]: import string
In [6]: t = pd.Series(np.arange(10), index = list(string.ascii_uppercase[:10]))
In [7]: t
Out[7]:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int64
In [8]: type(t)
Out[8]: pandas.core.series.Series
In [4]: import pandas as pd
In [5]: import string
In [6]: t = pd.Series(np.arange(10), index = list(string.ascii_uppercase[:10]))
In [7]: t
Out[7]:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int64
In [8]: type(t)
Out[8]: pandas.core.series.Series
In [12]: pd.Series(a, index=list(string.ascii_uppercase[5:15]))
Out[12]:
F 5.0
G 6.0
H 7.0
I 8.0
J 9.0
K NaN
L NaN
M NaN
N NaN
O NaN
dtype: float64
注:pandas会自动根据数据类型修改dtype的类型。
pandas之Series切片和索引
In [13]: t
Out[13]:
A 0
B 1
C 2
D 3
E 4
F 5
G 6
H 7
I 8
J 9
dtype: int64
In [14]: t[1:10:2]
Out[14]:
B 1
D 3
F 5
H 7
J 9
dtype: int64
In [8]: t[t[t>4]]
Out[8]:
F 5
G 6
H 7
I 8
J 9
dtype: int64
切片:直接传入start end 或者步长即可。
索引:一个的时候直接传入序号或者index,多个的时候传入序号或者index的列表。
对于一个陌生的series类型,我们如何知道他的索引和具体的值呢?
In [9]: t.values
Out[9]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int64)
In [10]: t.index
Out[10]: Index(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype='object')
In [11]: type(t.index)
Out[11]: pandas.core.indexes.base.Index
In [12]: type(t.values)
Out[12]: numpy.ndarray
Series对象本质上由两个数组构成, 一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键->值。
ndarray的很多方法都可以运用于Series类型,比如argmax,clip。
series具有where方法,但是结果和ndarray不同。
In [14]: t.argmax()
Out[14]: 9
In [15]: t.clip(5,8)
Out[15]:
A 5
B 5
C 5
D 5
E 5
F 5
G 6
H 7
I 8
J 8
dtype: int64
In [16]: t.where(t<5)
Out[16]:
A 0.0
B 1.0
C 2.0
D 3.0
E 4.0
F NaN
G NaN
H NaN
I NaN
J NaN
dtype: float64
In [18]: t.where((t<5)&(t>3))
Out[18]:
A NaN
B NaN
C NaN
D NaN
E 4.0
F NaN
G NaN
H NaN
I NaN
J NaN
dtype: float64
pandas之读取外部数据
现在假设我们有一个组关于狗的名字的统计数据,那么为了观察这组数据的情况,我们应该怎么做呢?
我们的这组数据存在csv中,我们直接使用pd. read_csv即可。
和我们想象的有些差别,我们以为他会是一个Series类型,但是他是一个DataFrame,那么接下来我们就来了解这种数据类型。
import pandas as pd
file_path = "./dogNames2.csv"
dog_names = pd.read_csv(file_path)
print(dog_names)
Row_Labels Count_AnimalName
0 RENNY 1
1 DEEDEE 2
2 GLADIATOR 1
3 NESTLE 1
4 NYKE 1
... ...
4159 ALEXXEE 1
4160 HOLLYWOOD 1
4161 JANGO 2
4162 SUSHI MAE 1
4163 GHOST 3
[4164 rows x 2 columns]
pandas之DataFrame
In [23]: import numpy as np
In [24]: t = pd.DataFrame(np.arange(12).reshape(3,4))
In [25]: t
Out[25]:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
In [28]: t = pd.DataFrame(np.arange(12).reshape(3,4), index=list(string.ascii_lowercase[:3]), columns=list(string.ascii
...: _uppercase[-4:]))
In [29]: t
Out[29]:
W X Y Z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
DataFrame还可以通过字典创建:
In [31]: a = {
"name":['zhangsan','lisi'],"age":[30,31],"job":["teacher","scientist"]}
In [32]: a
Out[32]:
{
'name': ['zhangsan', 'lisi'],
'age': [30, 31],
'job': ['teacher', 'scientist']}
In [34]: t1 = pd.DataFrame(a)
In [35]: t1
Out[35]:
name age job
0 zhangsan 30 teacher
1 lisi 31 scientist
和一个ndarray一样,我们通过shape,ndim,dtype了解这个ndaray的基本信息,那么对于DataFrame我们有什么方法了解呢?

DataFrame排序
那么回到之前读取的狗名字统计的数据上,尝试一下刚刚的方法。
那么问题来了:
使用次数最高的前几个名字是什么呢?
import pandas as pd
file_path = "./dogNames2.csv"
dog_names = pd.read_csv(file_path)
print(dog_names.sort_values(by="Count_AnimalName",ascending=False))
Row_Labels Count_AnimalName
858 BELLA 112
4134 MAX 82
3273 LUCY 82
843 BUDDY 79
433 SADIE 77
... ...
1654 RUBY ROSE 1
1655 MOO MOO 1
1656 KYLIE 1
1657 JEEP 1
2082 ANIOT 1
[4164 rows x 2 columns]
按照某一列排序
d = {
'A': [3, 6, 6, 7, 9], 'B': [2, 5, 8, 0, 0]}
df = pd.DataFrame(data=d)
print('排序前:\n', df)
'''
排序前:
A B
0 3 2
1 6 5
2 6 8
3 7 0
4 9 0
'''
res = df.sort_values(by='A', ascending=False)
print('按照A列的值排序:\n', res)
'''
按照A列的值排序:
A B
4 9 0
3 7 0
1 6 5
2 6 8
0 3 2
'''
按照多列排序
d = {
'A': [3, 6, 6, 7, 9], 'B': [2, 5, 8, 0, 0]}
df = pd.DataFrame(data=d)
print('排序前:\n', df)
'''
排序前:
A B
0 3 2
1 6 5
2 6 8
3 7 0
4 9 0
'''
res = df.sort_values(by=['A', 'B'], ascending=[False, False])
print('按照A列B列的值排序:\n', res)
'''
按照A列B列的值排序:
A B
4 9 0
3 7 0
2 6 8
1 6 5
0 3 2
'''
pandas之loc
经过pandas优化的选择方式:
- df.loc通过标签索引行数据
- df.iloc通过位置获取行数据
In [38]: t.loc[['a','c']]
Out[38]:
W X Y Z
a 0 1 2 3
c 8 9 10 11
In [40]: t.loc[['a','c'],['W','X']]
Out[40]:
W X
a 0 1
In [41]: t.loc['a':'c',['W','Y']]
Out[41]:
W Y
a 0 2
b 4 6
c 8 10
注:冒号在loc里面是闭合的,即会选择到冒号后面的数据。但在iloc中不闭合。
In [44]: t.iloc[0:2,1:4]
Out[44]:
X Y Z
a 1 2 3
b 5 6 7
In [45]: t.iloc[[0,2],[1,3]]
Out[45]:
X Z
a 1 3
c 9 11
pandas之布尔索引
In [54]: t[t['X']>3]
Out[54]:
W X Y Z
b 4 5 6 7
c 8 9 10 11
In [57]: t[(t['X']>3)&(t['Y']<8)]
Out[57]:
W X Y Z
b 4 5 6 7
注意点:不同的条件之间需要用括号括起来。
pandas之字符串方法

pandas之缺失数据的处理
我们的数据缺失通常有两种情况:
- 一种就是空,None等,在pandas是NaN(和np.nan一样)
- 另一种是我们让其为0,蓝色框中
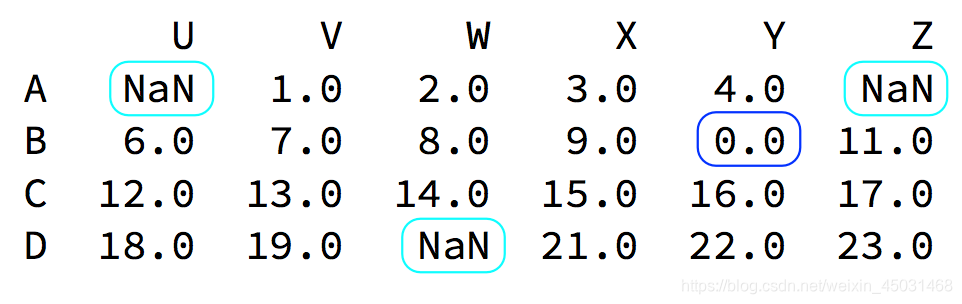
对于NaN的数据,在numpy中我们是如何处理的?
在pandas中我们处理起来非常容易
判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列dropna (axis=0, how=‘any’, inplace=False)
处理方式2:填充数据,t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan
当然并不是每次为0的数据都需要处理
计算平均值等情况,nan是不参与计算的,但是0会。
In [65]: a = {
"name":['zhangsan','lisi','wangwu'],"age":[30,31,np.nan],"numbers":[10086,10087,np.nan]}
In [67]: t3 = pd.DataFrame(a)
In [68]: t3
Out[68]:
name age numbers
0 zhangsan 30.0 10086.0
1 lisi 31.0 10087.0
2 wangwu NaN NaN
In [70]: t3['age'].fillna(t3['age'].mean())
Out[70]:
0 30.0
1 31.0
2 30.5
Name: age, dtype: float64
pandas常用统计方法案例
假设现在我们有一组从2006年到2016年1000部最流行的电影数据,我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
数据来源:https://www.kaggle.com/damianpanek/sunday-eda/data
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
# print(df.columns)
#评分的平均值
print(df['Rating'].mean())
#导演的人数
temp_list = df['Director'].tolist()
n = len(set([i for i in temp_list]))
print(n)
#演员人数
actor_list = df['Actors'].str.split(", ").tolist()
# print(df['Actors'].head(1))
# print(actor_list)
_actor_list = [i for j in actor_list for i in j]
# print(_actor_list)
n2 = len(set(_actor_list))
print(n2)
6.723199999999999
644
2015
对于这一组电影数据,如果我们想runtime的分布情况,应该如何呈现数据?
import pandas as pd
from matplotlib import pyplot as plt
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df.columns)
print(df['Runtime (Minutes)'].max(), df['Runtime (Minutes)'].min(),
df['Runtime (Minutes)'].max()-df['Runtime (Minutes)'].min())
#组距
d = 10
numbins = (df['Runtime (Minutes)'].max()-df['Runtime (Minutes)'].min()) // 5
#设置字体和负号的代码
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
#绘图风格
plt.style.use('ggplot')
#设置x轴的刻度
plt.xticks(range(df['Runtime (Minutes)'].min(), df['Runtime (Minutes)'].max()+d, d))
#绘图
plt.hist(df['Runtime (Minutes)'])
plt.show()

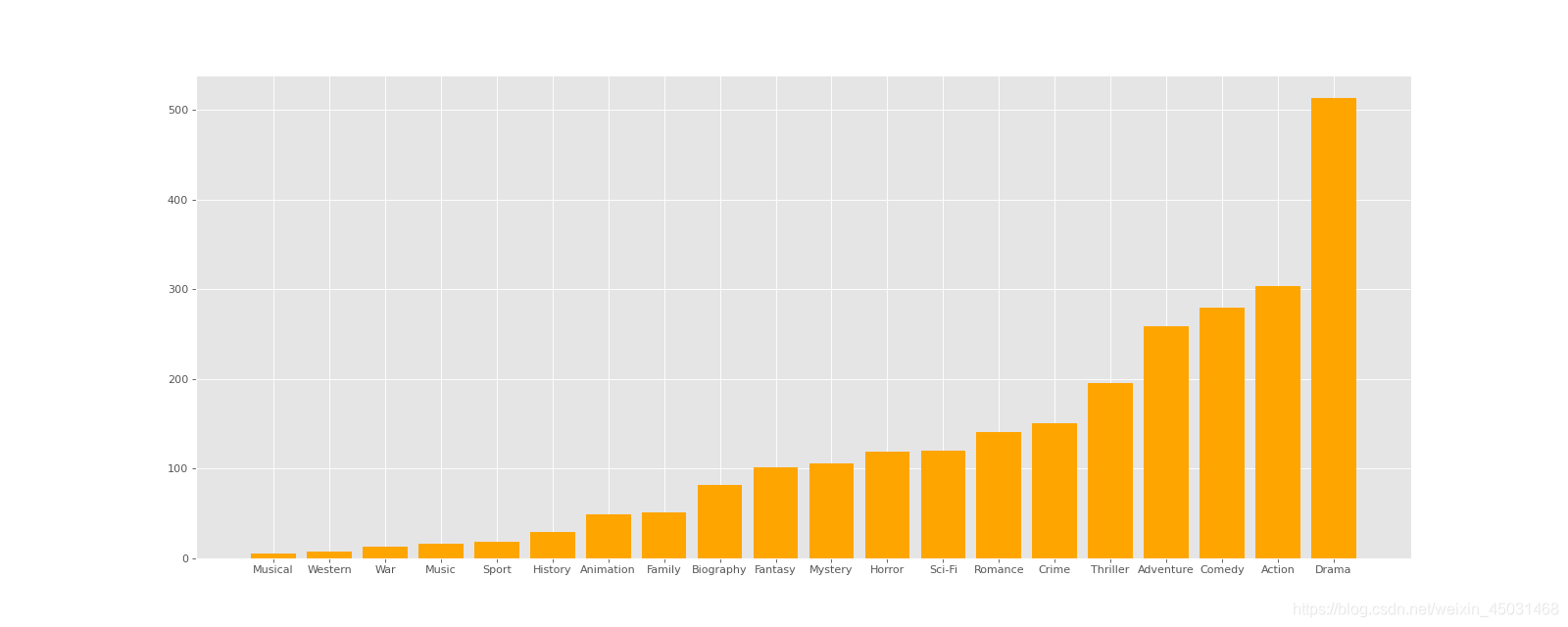
对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
思路:重新构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
file_path = "./IMDB-Movie-Data.csv"
df = pd.read_csv(file_path)
print(df.columns)
print(df["Genre"].head(1))
genre_list = df["Genre"].str.split(",").tolist()
_genre_set = set([i for j in genre_list for i in j])
_genre_list = list(_genre_set)
n = len(_genre_list)
# print(n)
# print(_genre_list)
t = pd.DataFrame(np.zeros((df.shape[0], n)), columns=_genre_list)
# print(t.head())
for i in range(t.shape[0]):
t.loc[i,genre_list[i]] = 1
# print(t.head())
genre_count = t.sum(axis=0)
print(genre_count)
#排序
genre_count = genre_count.sort_values()
_x = genre_count.index
_y = genre_count.values
#画图
plt.style.use('ggplot')
plt.figure(figsize=(20,8),dpi=80)
plt.bar(range(len(_x)),_y,width=0.8,color="orange")
plt.xticks(range(len(_x)),_x)
plt.show()