视频目标检测之后处理方法
之前的文章介绍了视频目标检测是什么,以及有哪几种方法,从这篇开始,正式从论文出发介绍各个方法。这篇文章要介绍的就是后处理方法啦,包括了三篇论文,分别是:
- T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
- Seq-NMS for Video Object Detection
- Improving Video Object Detection by Seq-Bbox Matching
T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
1. 摘要
由于静态目标检测器没有用到时序和上下文的信息,所以直接将它用在视频目标检测上有以下两点局限:
- 置信度有很大的浮动,比如下图(a)中的小猫,他的置信度有一个很大的波动。而我们更加希望同一个目标的置信度都是相似的
- 背景检测错误。比如下图(b)中将背景检测为Turtle

为了解决上面两个局限,显然要利用到时序和上下文的信息。
作者提出,直觉上可以从两个方面提高时序一致性:
- 将检测结果传播到相邻帧,以减少检测结果的突变。如果某一帧确定有目标,那么下一帧很有可能在临近的位子也有目标,并且置信度相似。即检测结果可以根据运动信息传播到相邻帧防止漏检。(这里的相邻帧只能提供一个短期的时间约束)。
- 对检测结果施加长期约束(long term constraints)。上图(a)中在每一帧都检测出小猫,而这些目标检测框就构成了tubelets。将每个tubelet当做一个单元并施加长期约束(如果施加后面会介绍)。
如何利用上下文的信息:
- 视频很长,有丰富的上下文信息,这可以很好地用来抑制FP(具体如何做后面再讲)
简单来说,静态目标检测器在视频目标检测上效果不好,作者就想利用时序和上下文的信息来提高效果。接下来就介绍作者提出的模型,T-CNN。并介绍每一部分具体是怎么操作的。
2. 模型
T-CNN主要包括以下四个模块
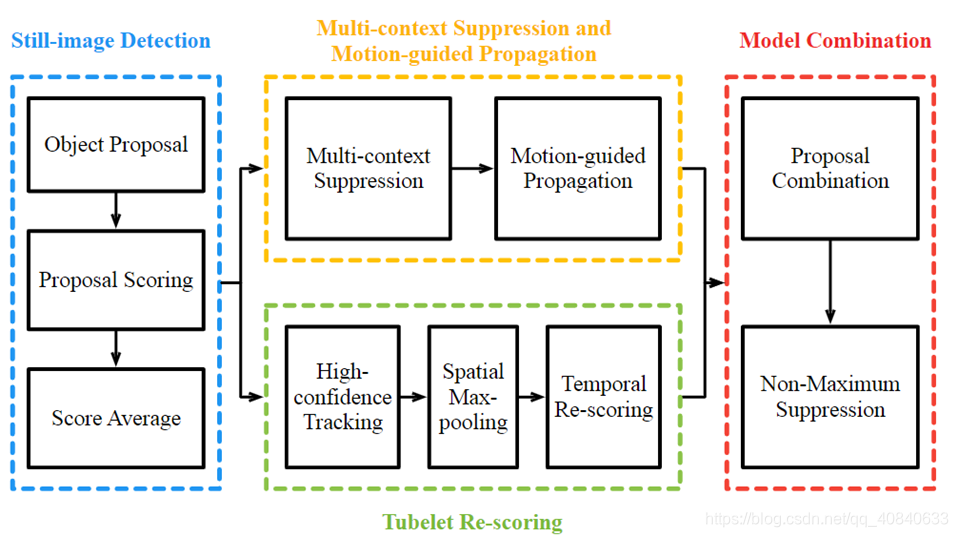
- Still-image Detection: 作者分别尝试使用DeepID-Net(R-CNN的扩张)和CRAFT(faster R-CNN的扩展)。这一步之后我们就得到了很多候选框及对应的类分数。
- Multi-context Suppression and Motion-guided Propagation: 这一部分通过减少FP和FN来提高准确率。这部分包括MCS和MGP两个部分,接下来看下这两部分的具体步骤。
MCS
作者认为一段视频里面会存在K类目标,如果检测出其他类则是检测错误,所以要抑制这些错误的类,从而利用了上下文信息来减少FP(False
Positive)。如下图所示,横向为视频中的帧,在第一个视频中出现了Monkey和cat,则这两类大概率会在后面的帧中也出现,所以也要抑制其他类的出现。
论文中具体做法是:对所有帧所有候选框按照类分数排序,分数大于阈值的则为高置信度类,类分数保持不变;低于类分数的为低置信度类,类分数减去一个固定值。
MGP
减少FN来提高准确率。产生FN的原因有两个:1.候选区不够多,不能覆盖所有的目标;2. 目标上检测出候选框,但类分数很低。
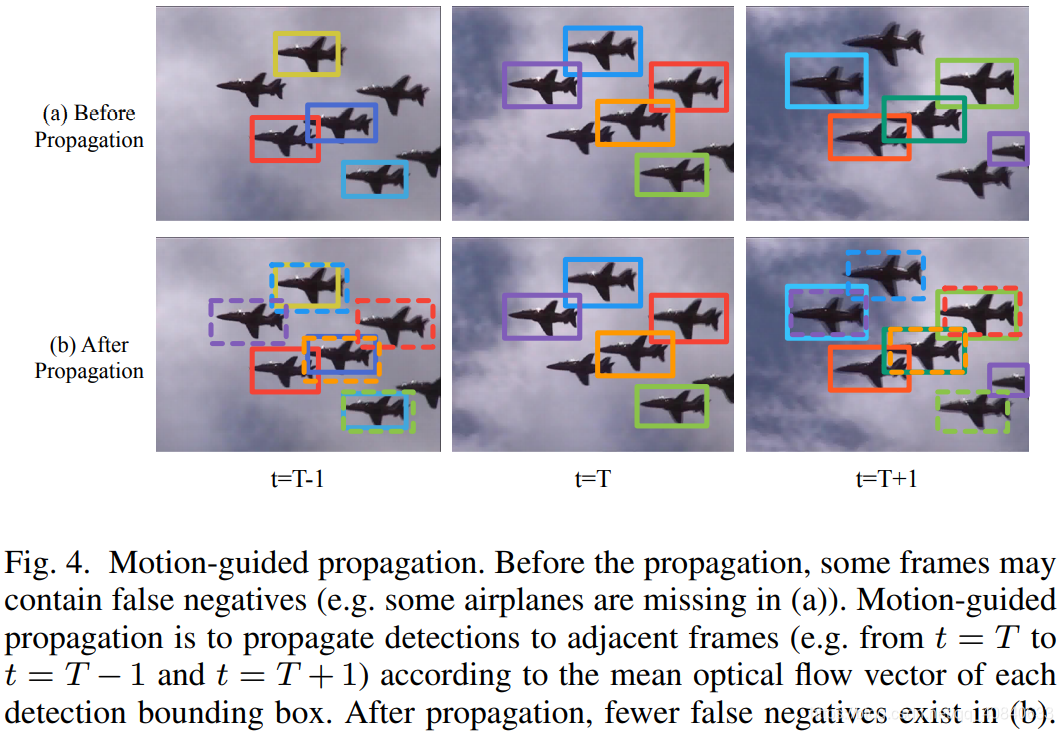
显而易见,当某个物体静止或者低速运动,则他会在相邻帧的相似位置出现。所以可以通过传播相邻帧的候选框和分数(根据运动信息)来减少FN。比如下图,假设我们现在在时刻t=T,
(a)是没有运动传播,可以看到t=T-1时刻最左边的飞机和t=T+1最上面的飞机都没有被候选框选出。通过将t=T的候选框传播到相邻帧得到了图(b),虚线即是新产生的候选框。
论文中具体做法是:1. 对于某一帧的每个候选框,计算mean optical flow
vector;2.将候选框根据vector传播到相邻帧,分数保持不变。
- Tubelet Re-scoring MGP虽然显著得减少了FN,但只用到短期时间约束(相邻帧)。为了用到长期时间约束还需要用到tublet(最开始已经解释过啦,不清楚的往前翻)。这一模块包含三个部分:1.
High-confidence Tracking; 2. Spatial Max-pooling; 3.Temporal
Re-scoring.
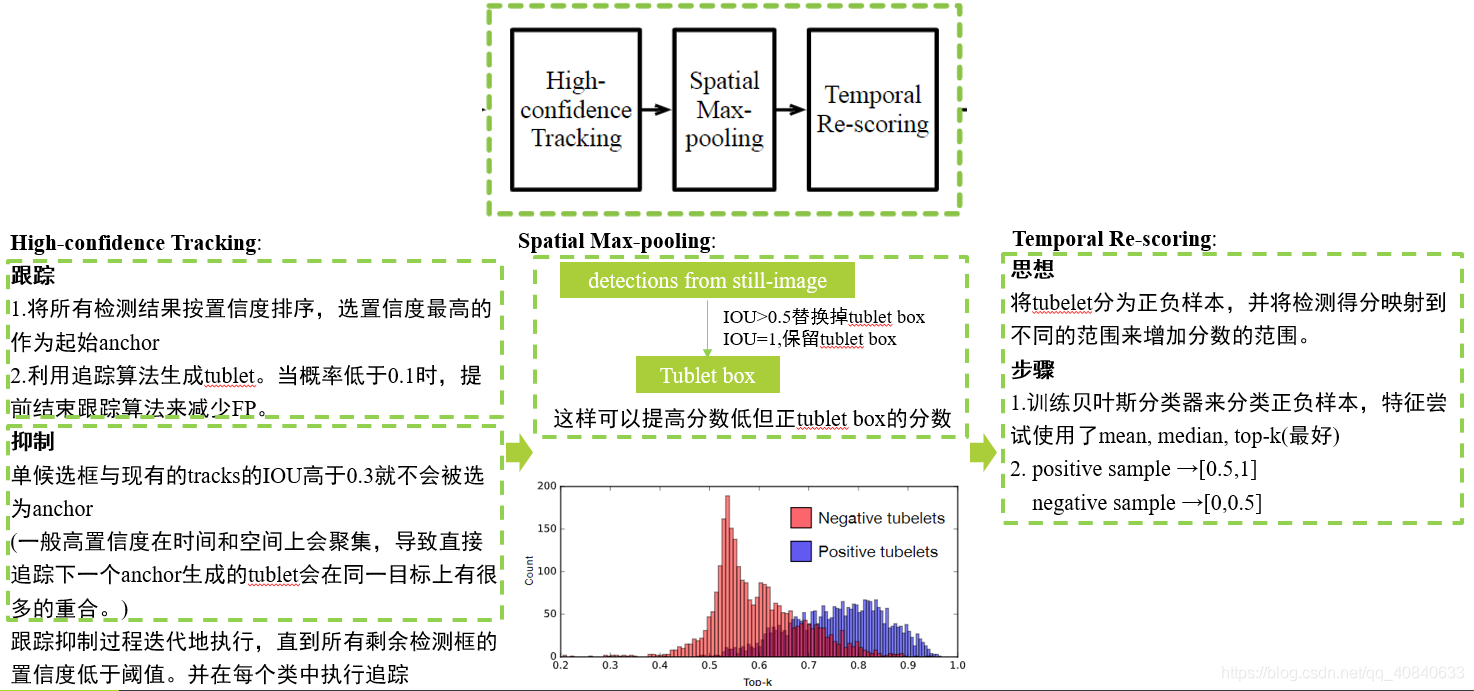
High-confidence Tracking 具体步骤是:
1.跟踪:将所有检测结果按置信度排序,选置信度最高的作为起始anchor,利用追踪算法生成tublet。当概率低于0.1时,提前结束跟踪算法来减少FP。
2.抑制:一般高置信度候选框在时间和空间上会聚集,导致直接追踪下一个anchor生成的tublet会在同一目标上有很多的重合。所以当候选框与现有的tublets的IOU高于0.3就不会被选为anchor。简单地说会有好几个候选框都框出了同一个目标,为了不重复在同一个目标上追踪,所以需要抑制。
跟踪抑制过程迭代地执行,直到所有剩余检测框的置信度低于阈值。
Spatial Max-pooling 上一步我们产生了很多候选框,但这些候选框不一定是完全合理的(比如和目标位置是有偏差的,类分数较低),所以这一步就是来校正上一步的结果。论文认为从静态目标检测器的见过是更加准确地,所以当从静态目标检测器得到的候选框和tublet中的候选框的IOU>0.5时,就用静态目标检测器的候选框代替掉tublet中的候选框(位置和类分数),特殊情况IOU=1时,则什么也不操作。
Temporal Re-scoring 由于得到的tublet不一定是正确的,所以将tubelet分为正负样本,并将检测得分映射到不同的范围来增加分数的范围。具体是用SVM进行分类,将正样本映射到[0.5,1],负样本映射到[0,0.5]。- Model Combination 最后一步,首先将所有的候选框归一到[0,1]之间,在使用NMS,得到最终的结果。 不清楚NMS的可参考:NMS


3. 结果
Data表示两个数据集,作者在ILSVRC2015比赛中取得了第一名。

Seq-NMS for Video Object Detection
这篇文章比较简单,所以就不像上一篇展开讲了。作者发现,直接将静态目标检测器用在视频中,往往使用NMS的时候会选择错误的候选框,所以作者利用时序信息来对候选框重新打分。整个过程分为三步:
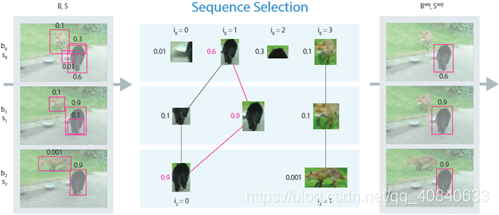
- Sequence Selection 选择目标序列 相邻帧之间的候选框,如果他们的IoU大于某个阈值,则认为它们是有联系的,如上图黑线和红线。在这些有联系的序列中,通过最大化序列分数(如图中0.6+0.9+0.9是最大的)找到目标序列(红线)。
- Sequence Re-scoring 找到目标序列之后,需要对序列重新打分,可采用取平均值或者最大化。平均值指的是求出目标序列的平均值,让每个候选框类分数都为这个值;最大化指让每个候选框类分数等于序列中的最大值。
- Suppression 最后采用NMS得到最终的候选框。

作者在ILSVRC2015比赛中取得了第三名,虽然效果没那么好,但整个处理简单。

Improving Video Object Detection by Seq-Bbox Matching
这一篇论文也比较简单,和seq-NMS有相似之处。同样分为3步:
- Seq-Bbox Matching 作者首先提出了如何计算两个候选框的距离。显然分母出现0,则距离为无穷大。接着计算相邻帧所有候选框的距离,保存所有距离不为无穷大候选框对(无穷大代表候选框没有联系)
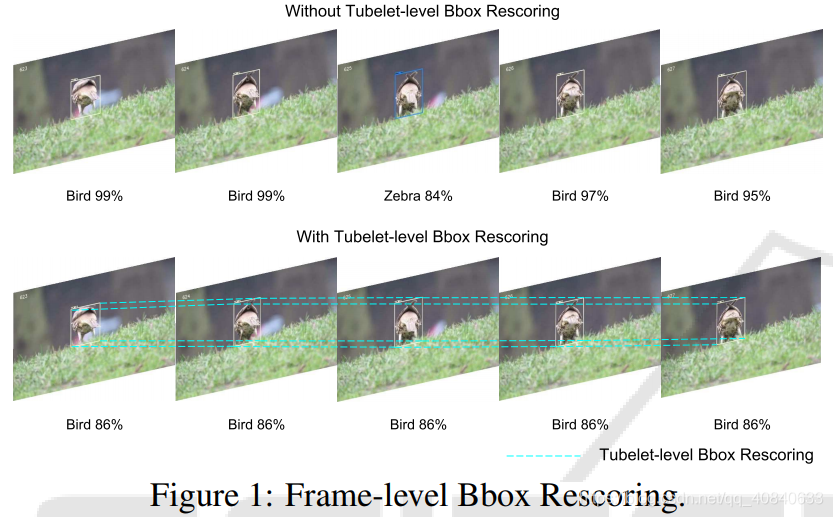
- Frame-level Bbox Rescoring 根据第一步得到的tublet,对类分数进行平均。
- Tubelet-level Bbox Linking 可以看到前两步和Seq-NMS是类似的。不同之处就是这一步。如果前 tublet的最后一帧与后tublet的第一帧重合,且两个tublet中间帧数不超过k,利用插值法补充中间空缺帧。如图中紫色部分。
具体公式如下: f代表前一个tublet, l代表后一个tublet。
作者还通过改变该公式,使该方法可以直接用于online(可以直接实时处理视频流)。
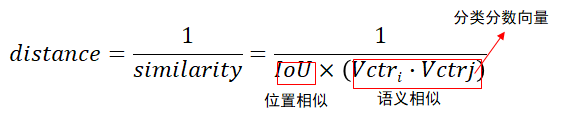


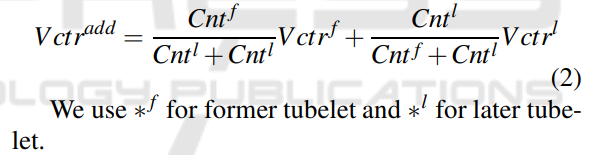
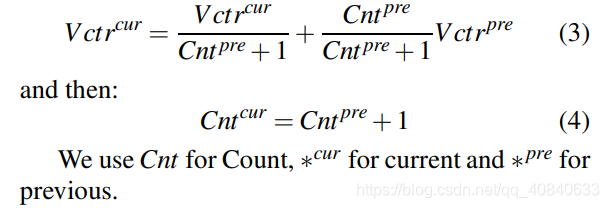
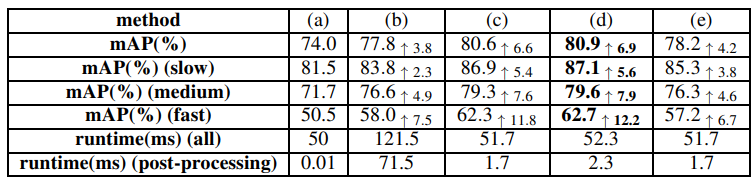
最后来看下这个方法的效果:
(a) 静态目标检测器
(b) Seq-NMS
© 本文加上第二步方法
(d) 本文加上第二步,第三步方法
(e) 本文online方法
总结
我们介绍了T-CNN,seq-NMS, Seq-Bbox三种用于视频目标检测的后处理方法。后处理方法可以直接用到已有的静态目标检测器上。Seq-NMS相对来说比较简单,效果相对来说也没有那么好。T-CNN和Seq-Bbox相对于Seq-NMS都产生了新的候选框,正确率也较高。但T-CNN比较复杂。所以实际使用过程,个人更加推荐Seq-Bbox方法。最后附上代码链接