基本概念和IO入门
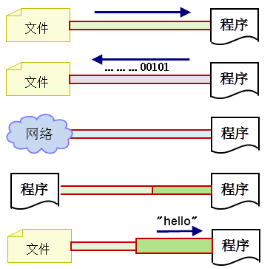
对于任何程序设计语言而言,输入输出(Input/Output)系统都是非常核心的功能。程序运行需要数据,数据的获取往往需要跟外部系统进行通信,外部系统可能是文件、数据库、其他程序、网络、IO设备等等。外部系统比较复杂多变,那么我们有必要通过某种手段进行抽象、屏蔽外部的差异,从而实现更加便捷的编程。
Jvm虚拟机主要打交道的io操作是文件,内存,网络
输入(Input)指的是:可以让程序从外部系统获得数据(核心含义是“读”,读取外部数据)。常见的应用:
Ø 读取硬盘上的文件内容到程序。例如:播放器打开一个视频文件、word打开一个doc文件。
Ø 读取网络上某个位置内容到程序。例如:浏览器中输入网址后,打开该网址对应的网页内容;下载网络上某个网址的文件。
Ø 读取数据库系统的数据到程序。
Ø 读取某些硬件系统数据到程序。例如:车载电脑读取雷达扫描信息到程序;温控系统等。
输出(Output)指的是:程序输出数据给外部系统从而可以操作外部系统(核心含义是“写”,将数据写出到外部系统)。常见的应用有:
Ø 将数据写到硬盘中。例如:我们编辑完一个word文档后,将内容写到硬盘上进行保存。
Ø 将数据写到数据库系统中。例如:我们注册一个网站会员,实际就是后台程序向数据库中写入一条记录。
Ø 将数据写到某些硬件系统中。例如:导弹系统导航程序将新的路径输出到飞控子系统,飞控子系统根据数据修正飞行路径。
java.io包为我们提供了相关的API,实现了对所有外部系统的输入输出操作,这就是我们这章所要学习的技术。
数据源
数据源data source,提供数据的原始媒介。常见的数据源有:数据库、文件、其他程序、内存、网络连接、IO设备。如图10-1所示。
数据源分为:源设备、目标设备。
\1. 源设备:为程序提供数据,一般对应输入流。
\2. 目标设备:程序数据的目的地,一般对应输出流。
流
流是一个抽象、动态的概念,是一连串连续动态的数据集合。
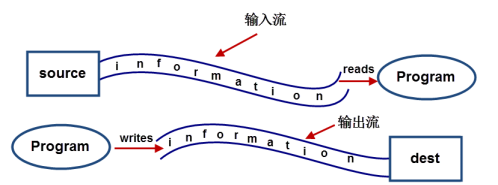
对于输入流而言,数据源就像水箱,流(stream)就像水管中流动着的水流,程序就是我们最终的用户。我们通过流(A Stream)将数据源(Source)中的数据(information)输送到程序(Program)中。
对于输出流而言,目标数据源就是目的地(dest),我们通过流(A Stream)将程序(Program)中的数据(information)输送到目的数据源(dest)中。

输入/输出流的划分是相对程序而言的,并不是相对数据源。
输入流输出流
\1. 输入流:数据流向是数据源到程序(以InputStream、Reader结尾的流)。
\2. 输出流:数据流向是程序到目的地(以OutPutStream、Writer结尾的流)。
按处理的数据单元分类:
- \1. 字节流:以字节为单位获取数据,命名上以Stream结尾的流一般是字节流,如
FileInputStream、FileOutputStream。 - \2. 字符流:以字符为单位获取数据,命名上以Reader/Writer结尾的流一般是字符流,如
FileReader、FileWriter。
按处理对象不同分类:
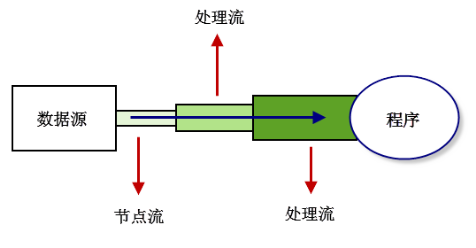
- \1. 节点流:可以直接从数据源或目的地读写数据,如FileInputStream、FileReader、DataInputStream等。
- \2. 处理流:不直接连接到数据源或目的地,是”处理流的流”。通过对其他流的处理提高程序的性能,如BufferedInputStream、BufferedReader等。处理流也叫包装流。
节点流处于IO操作的第一线,所有操作必须通过它们进行;处理流可以对节点流进行包装,提高性能或提高程序的灵活性。
四大IO抽象类
InputStream是接口,Java IO 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
- InputStream接口: 继承自InputSteam的流都是用于向程序中输入数据,且数据的单位为字节(8 bit)。
- 要求子类重写
read()等方法。读取一个字节的数据,并将字节的值作为int类型返回(0-255之间的一个值)。如果未读出字节则返回-1(返回值为-1表示读取结束)。 - 要求子类重写
void close():关闭输入流对象,释放相关系统资源。
- 要求子类重写
- OutputStream接口: 此抽象类是表示字节输出流的所有类的父类。输出流接收输出字节并将这些字节发送到某个目的地。
- 要求子类重写
write(int n)等方法,用于写单个字节或者字节数组 - void close():关闭输出流对象,释放相关系统资源。
- 要求子类重写
- Reader接口:用于读取的字符流抽象类,数据单位为字符。
- 读取汉字的时候,如果用字节流就会导致读出来乱码
- int read(): 读取一个字符的数据,并将字符的值作为int类型返回(0-65535之间的一个值,即Unicode值)。如果未读出字符则返回-1(返回值为-1表示读取结束)。
- void close() : 关闭流对象,释放相关系统资源。
- Writer接口:用于写入的字符流抽象类,数据单位为字符。
- void write(int n): 向输出流中写入一个字符。
- void close() : 关闭输出流对象,释放相关系统资源。
但是,我们通常不会用到read() write()这些方法,它们之所以存在是因为别的类可以使用它们,以便提供更有用的接口。因此,我们很少使用单一的类来创建流对象,而是通过叠合多个对象来提供所期望的功能(这是装饰器设计模式)。实际上,Java中“流”类库让人迷惑的主要原因就在于:创建单一的结果流,却需要创建多个对象。
流的常用方法
read()、read(arr[])
读一个字节
// in是输入流,out是输出流
// 从输入流中读取一个字节
in.read();
// read()返回的是该字符串的ASCII值,即是个0-255的int;如果没读到字节,返回-1
//(char)in.read();
// 判断读完了没有
while((len = inputstream.read()) != -1)
byte[] by = new byte[4];
in.read(by);//把流中的数据读取到数组中 // 返回值:返回值为实际读取的字节数;没读取到值返回-1;数组长度为0返回0
示例
import java.io.*;
public class TestIO1 {
public static void main(String[] args) {
try {
//创建输入流
FileInputStream fis = new FileInputStream("d:/a.txt"); // a.txt文件内容是:abc
//一个字节一个字节的读取数据
int s1 = fis.read(); // 打印输入字符a对应的ascii码值97
int s2 = fis.read(); // 打印输入字符b对应的ascii码值98
int s3 = fis.read(); // 打印输入字符c 对应的ascii码值99
int s4 = fis.read(); // 由于文件内容已经读取完毕,返回-1
System.out.println(s1);//97
System.out.println(s2);//98
System.out.println(s3);//99
System.out.println(s4);//-1
// 流对象使用完,必须关闭!不然,总占用系统资源,最终会造成系统崩溃!
fis.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
从上面代码我们了解到文件最后的结果是-1,可以用给他判断文件结尾
import java.io.*;
public class TestIO2 {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("d:/a.txt"); // 内容是:abc
StringBuilder sb = new StringBuilder();
int temp = 0;
//当temp等于-1时,表示已经到了文件结尾,停止读取
while ((temp = fis.read()) != -1) {
sb.append((char) temp);
}
System.out.println(sb);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
//这种写法,保证了即使遇到异常情况,也会关闭流对象。
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
flush()
https://blog.csdn.net/AnneQiQi/article/details/51295218
使用write()方法写入到了内核缓存区,flush()会把数据从内核缓冲区写到硬盘
这个是缓冲区的问题
java在使用流时,都会有一个缓冲区,按一种它认为比较高效的方法来发数据:把要发的数据先放到缓冲区,缓冲区放满以后再一次性发过去,而不是分开一次一次地发.
而flush()表示强制将缓冲区中的数据发送出去,不必等到缓冲区满.
java.io.OutputStream.flush() 方法刷新此输出流并强制将所有缓冲的输出字节被写出。刷新的常规协定是,调用它是一个迹象表明,如果以前写的任何字节都被缓冲的输出流的实现,如字节应立即写入到它们的目的地。
此流的预期目标是由底层的操作系统,例如一个文件,然后刷新流保证提供了一个抽象只是先前写入的字节流传递给操作系统进行写入;它并不能保证他们实际上写的是一个物理设备,如磁盘驱动器。
- FileStream.Flush 方法:清除该流的所有缓冲区,使得所有缓冲的数据都被写入到基础设备。
针对上述回答,给出了精准的回答
FileOutPutStream继承outputStream,并不提供flush()方法的重写,所以无论内容多少write都会将二进制流直接传递给底层操作系统的I/O,flush无效果而Buffered系列的输入输出流函数单从Buffered这个单词就可以看出他们是使用缓冲区的,应用程序每次IO都要和设备进行通信,效率很低,因此缓冲区为了提高效率,当写入设备时,先写入缓冲区,等到缓冲区有足够多的数据时,就整体写入设备
使用BufferedXXXStream。默认缓冲区大小是8K。读的时候会一直填满缓冲区(或者文件读取完毕),写的时候也是等缓冲区满了之后(或者执行flush操作)才将内容送入内核缓冲区。效率高的原因就是避免了每读一个字节都要陷入操作系统内核(这是个耗时的操作)。具体代码,题主自己查API吧。
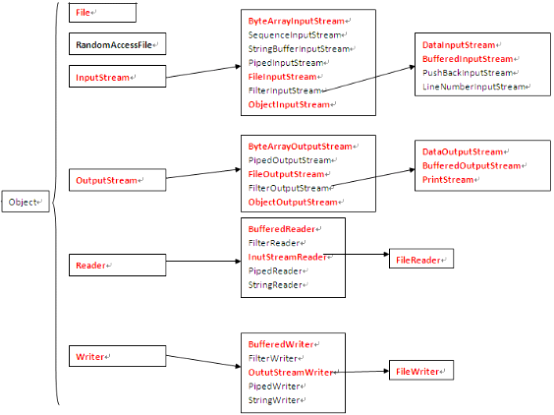
IO流类的体系
按操作方式分类结构图:
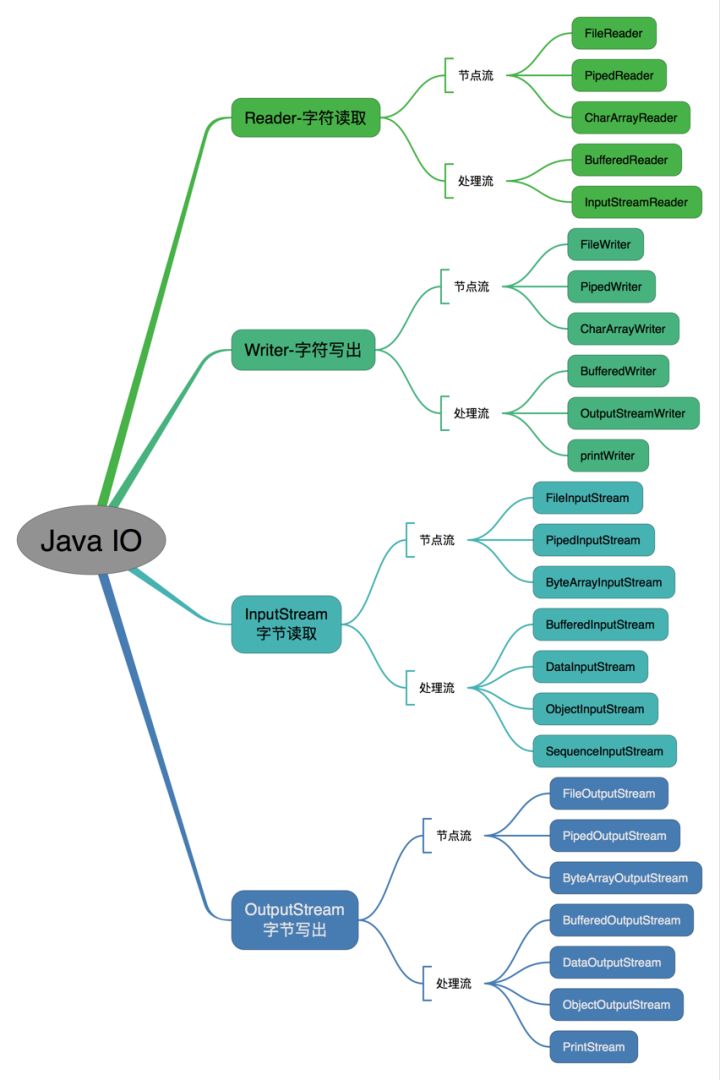
按操作对象分类结构图:
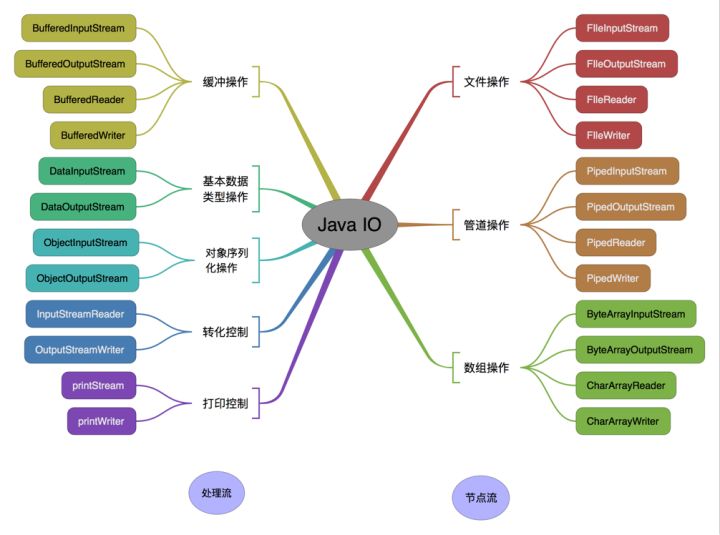
图10-7 Java中的IO流体系
从上图发现,很多流都是成对出现的,比如:FileInputStream/FileOutputStream,显然是对文件做输入和输出操作的。我们下面简单做个总结:
\1. InputStream/OutputStream
字节流的抽象类。
\2. Reader/Writer
字符流的抽象类。
\3. FileInputStream/FileOutputStream
节点流:以字节为单位直接操作“文件”。
\4. ByteArrayInputStream/ByteArrayOutputStream
节点流:以字节为单位直接操作“字节数组对象”。
\5. ObjectInputStream/ObjectOutputStream
处理流:以字节为单位直接操作“对象”。
\6. DataInputStream/DataOutputStream
处理流:以字节为单位直接操作“基本数据类型与字符串类型”。
\7. FileReader/FileWriter
节点流:以字符为单位直接操作“文本文件”(注意:只能读写文本文件)。
\8. BufferedReader/BufferedWriter
处理流:将Reader/Writer对象进行包装,增加缓存功能,提高读写效率。
\9. BufferedInputStream/BufferedOutputStream
处理流:将InputStream/OutputStream对象进行包装,增加缓存功能,提高 读写效率。
\10. InputStreamReader/OutputStreamWriter
处理流:将字节流对象转化成字符流对象。
\11. PrintStream
处理流:将OutputStream进行包装,可以方便地输出字符,更加灵活。
文件字节流FileOutputStream
- FileInputStream通过字节的方式读取文件,适合读取所有类型的文件(图像、视频、文本文件等)。Java也提供了FileReader专门读取文本文件。
- FileOutputStream 通过字节的方式写数据到文件中,适合所有类型的文件。Java也提供了FileWriter专门写入文本文件。
【示例10-3】将文件内容读取到程序中
参考【示例10-2】即可。
【示例10-4】将字符串/字节数组的内容写入到文件中
import java.io.FileOutputStream;
import java.io.IOException;
public class TestFileOutputStream {
public static void main(String[] args) {
FileOutputStream fos = null;
String string = "北京尚学堂欢迎您!";
try {
// true表示内容会追加到文件末尾;false表示重写整个文件内容。
fos = new FileOutputStream("d:/a.txt", true);
//该方法是直接将一个字节数组写入文件中; 而write(int n)是写入一个字节
fos.write(string.getBytes());
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
在示例10-4中,用到一个write方法:void write(byte[ ] b),该方法不再一个字节一个字节地写入,而是直接写入一个字节数组;另外其还有一个重载的方法:void write(byte[ ] b, int off, int length),这个方法也是写入一个字节数组,但是我们程序员可以指定从字节数组的哪个位置开始写入,写入的长度是多少。
执行结果如图10-8所示:
现在我们已经学习了使用文件字节流分别实现文件的读取与写入操作,接下来我们将两种功能综合使用就可以轻松实现文件的复制了。
【示例10-5】利用文件流实现文件的复制
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestFileCopy {
public static void main(String[] args) {
//将a.txt内容拷贝到b.txt
copyFile("d:/a.txt", "d:/b.txt");
}
/**
* 将src文件的内容拷贝到dec文件
* @param src 源文件
* @param dec 目标文件
*/
static void copyFile(String src, String dec) {
FileInputStream fis = null;
FileOutputStream fos = null;
//为了提高效率,设置缓存数组!(读取的字节数据会暂存放到该字节数组中)
byte[] buffer = new byte[1024];
int temp = 0;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dec);
//边读边写
//temp指的是本次读取的真实长度,temp等于-1时表示读取结束
while ((temp = fis.read(buffer)) != -1) {
/*将缓存数组中的数据写入文件中,注意:写入的是读取的真实长度;
*如果使用fos.write(buffer)方法,那么写入的长度将会是1024,即缓存
*数组的长度*/
fos.write(buffer, 0, temp);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//两个流需要分别关闭
try {
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
执行结果如图10-9和图10-10所示:

图10-9 示例10-5运行后d盘部分目录

注意
在使用文件字节流时,我们需要注意以下两点:
\1. 为了减少对硬盘的读写次数,提高效率,通常设置缓存数组。相应地,读取时使用的方法为:read(byte[] b);写入时的方法为:write(byte[ ] b, int off, int length)。
\2. 程序中如果遇到多个流,每个流都要单独关闭,防止其中一个流出现异常后导致其他流无法关闭的情况。
文件字符流FileReader
前面介绍的文件字节流可以处理所有的文件,但是字节流不能很好的处理Unicode字符,经常会出现“乱码”现象。所以,我们处理文本文件,一般可以使用文件字符流,它以字符为单位进行操作
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TestFileCopy2 {
public static void main(String[] args) {
// 写法和使用Stream基本一样。只不过,读取时是读取的字符。
FileReader fr = null;
FileWriter fw = null;
int len = 0;
try {
fr = new FileReader("d:/a.txt");
fw = new FileWriter("d:/d.txt");
//为了提高效率,创建缓冲用的字符数组
char[] buffer = new char[1024];
//边读边写
while ((len = fr.read(buffer)) != -1) {
fw.write(buffer, 0, len);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fr != null) {
fr.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
执行结果如图10-11和图10-12所示:

图10-11 示例10-6运行后d盘部分目录

缓冲字节流BufferedInputStream
Java缓冲流本身并不具有IO流的读取与写入功能,只是在别的流(节点流或其他处理流)上加上缓冲功能提高效率,就像是把别的流包装起来一样,因此缓冲流是一种处理流(包装流)。
BufferedInputStream是套在某个其他的InputStream外,起着缓存的功能,用来改善里面那个InputStream的性能(如果可能的话),它自己不能脱离里面那个单独存在。FileInputStream是读取一个文件来作InputStream。所以你可以把BufferedInputStream套在FileInputStream外,来改善FileInputStream的性能。
FileInputStream是字节流,BufferedInputStream是字节缓冲流,使用BufferedInputStream读资源比FileInputStream读取资源的效率高(BufferedInputStream的read方法会读取尽可能多的字节),且FileInputStream对象的read方法会出现阻塞;
FileInputStream是字节流,FileReader是字符流,用字节流读取中文的时候,可能会出现乱码,而用字符流则不会出现乱码,而且用字符流读取的速度比字节流要快;
ObjectOutputStream可以将java对象写入outputstream流中(序列化),然后进行持久化,此对象必须是实现了java.io.Serializable 接口;
ByteArrayOutputStream是将数据写入byte数组中;
BufferedInputStream有可能会读取比您规定的更多的东西到内存,以减少访问IO的次数, 总之您要记住一句话,访问IO的次数越少,性能就越高,原因就在于CPU和内存的速度>>远大于硬盘或其他外部设备的速度。
当对文件或者其他数据源进行频繁的读写操作时,效率比较低,这时如果使用缓冲流就能够更高效的读写信息。因为缓冲流是先将数据缓存起来,然后当缓存区存满后或者手动刷新时再一次性的读取到程序或写入目的地。
因此,缓冲流还是很重要的,我们在IO操作时记得加上缓冲流来提升性能。
BufferedInputStream和BufferedOutputStream这两个流是缓冲字节流,通过内部缓存数组来提高操作流的效率。
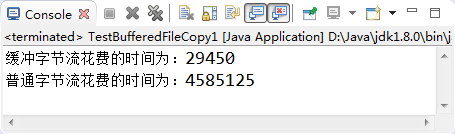
下面我们通过两种方式(普通文件字节流与缓冲文件字节流)实现一个视频文件的复制,来体会一下缓冲流的好处。
【示例10-7】使用缓冲流实现文件的高效率复制
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestBufferedFileCopy1 {
public static void main(String[] args) {
// 使用缓冲字节流实现复制
long time1 = System.currentTimeMillis();
copyFile1("D:/电影/华语/大陆/尚学堂传奇.mp4", "D:/电影/华语/大陆/尚学堂越
"+"来越传奇.mp4");
long time2 = System.currentTimeMillis();
System.out.println("缓冲字节流花费的时间为:" + (time2 - time1));
// 使用普通字节流实现复制
long time3 = System.currentTimeMillis();
copyFile2("D:/电影/华语/大陆/尚学堂传奇.mp4", "D:/电影/华语/大陆/尚学堂越
"+"来越传奇2.mp4");
long time4 = System.currentTimeMillis();
System.out.println("普通字节流花费的时间为:" + (time4 - time3));
}
/**缓冲字节流实现的文件复制的方法*/
static void copyFile1(String src, String dec) {
FileInputStream fis = null;
BufferedInputStream bis = null;
FileOutputStream fos = null;
BufferedOutputStream bos = null;
int temp = 0;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dec);
//使用缓冲字节流包装文件字节流,增加缓冲功能,提高效率
//缓存区的大小(缓存数组的长度)默认是8192,也可以自己指定大小
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
while ((temp = bis.read()) != -1) {
bos.write(temp);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//注意:增加处理流后,注意流的关闭顺序!“后开的先关闭!”
try {
if (bos != null) {
bos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (bis != null) {
bis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**普通节流实现的文件复制的方法*/
static void copyFile2(String src, String dec) {
FileInputStream fis = null;
FileOutputStream fos = null;
int temp = 0;
try {
fis = new FileInputStream(src);
fos = new FileOutputStream(dec);
while ((temp = fis.read()) != -1) {
fos.write(temp);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (fos != null) {
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fis != null) {
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
缓冲字符流BufferedReader
BufferedReader/BufferedWriter增加了缓存机制,大大提高了读写文本文件的效率,同时,提供了更方便的按行读取的方法:readLine(); 处理文本时,我们一般可以使用缓冲字符流。
为了提高字符流读写的效率,引入了缓冲机制,进行字符批量的读写,提高了单个字符读写的效率。BufferedReader用于加快读取字符的速度,BufferedWriter用于加快写入的速度
BufferedReader和BufferedWriter类各拥有8192个字符的缓冲区。当BufferedReader在读取文本文件时,会先尽量从文件中读入字符数据并放满缓冲区,而之后若使用read()方法,会先从缓冲区中进行读取。如果缓冲区数据不足,才会再从文件中读取,使用BufferedWriter时,写入的数据并不会先输出到目的地,而是先存储至缓冲区中。如果缓冲区中的数据满了,才会一次对目的地进行写出。
需要注意的是:
reader.readLine()方法返回的一行字符中不包含换行符,所以输出的时候要自己加上换行符。
BufferedReader比FileReader高级的地方在于这个,FileReader能一次读取一个字符,或者一个字符数组。而BufferedReader也可以,同时BufferedReader还能一次读取一行字符串。同时,BufferedReader带缓冲,会比FileReader快很多。但是
FileReader使用项目的编码来读取解析字符,不能指定编码,可能会出现编码问题,如果要指定编码可以使用包装InputStreamReader的BufferedReader。这样兼顾效率和编码。
https://blog.csdn.net/qq_21808961/article/details/81561464
构造方法
| 方法 | 描述 |
|---|---|
BufferedReader(Reader in) |
创建一个使用默认大小输入缓冲区的缓冲字符输入流。 |
BufferedReader(Reader in, int sz) |
创建一个使用指定大小输入缓冲区的缓冲字符输入流。 |
成员方法
| 方法 | 描述 |
|---|---|
int read() |
读取单个字符。 |
int read(char[] cbuf, int off, int len) |
将字符读入数组的某一部分。 |
String readLine() |
读取一个文本行。 |
long skip(long n) |
跳过字符。 |
boolean ready() |
判断此流是否已准备好被读取。 |
void close() |
关闭该流并释放与之关联的所有资源。 |
void mark(int readAheadLimit) |
标记流中的当前位置。 |
boolean markSupported() |
判断此流是否支持 mark() 操作(它一定支持)。 |
void reset() |
将流重置到最新的标记。 |
BuffedReader in = new BuffedReader(new InputStreamReader(socket.getInputStream()));
new BufferedReader(new FileReader("d:/a.txt"));
【示例10-8】使用BufferedReader与BufferedWriter实现文本文件的复制
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class TestBufferedFileCopy2 {
public static void main(String[] args) {
// 注:处理文本文件时,实际开发中可以用如下写法,简单高效!!
FileReader fr = null;
FileWriter fw = null;
BufferedReader br = null;
BufferedWriter bw = null;
String tempString = "";
try {
fr = new FileReader("d:/a.txt");
fw = new FileWriter("d:/d.txt");
// 使用缓冲字符流进行包装
br = new BufferedReader(fr);
bw = new BufferedWriter(fw);
// BufferedReader提供了更方便的readLine()方法,直接按行读取文本
// br.readLine()方法的返回值是一个字符串对象,即文本中的一行内容
while ((tempString = br.readLine()) != null) {
//将读取的一行字符串写入文件中
bw.write(tempString);
//下次写入之前先换行,否则会在上一行后边继续追加,而不是另起一行
bw.newLine();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (bw != null) {
bw.close();
}
} catch (IOException e1) {
e1.printStackTrace();
}
try {
if (br != null) {
br.close();
}
} catch (IOException e1) {
e1.printStackTrace();
}
try {
if (fw != null) {
fw.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fr != null) {
fr.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
注意
\1. readLine()方法是BufferedReader特有的方法,可以对文本文件进行更加方便的读取操作。
\2. 写入一行后要记得使用newLine()方法换行。
字节数组流ByteArrayInputStream
ByteArrayInputStream和ByteArrayOutputStream经常用在需要流和数组之间转化的情况!
说白了,FileInputStream是把文件当做数据源。ByteArrayInputStream则是把内存中的”某个字节数组对象”当做数据源。
【示例10-9】简单测试ByteArrayInputStream 的使用
import java.io.ByteArrayInputStream;
import java.io.IOException;
public class TestByteArray {
public static void main(String[] args) {
//将字符串转变成字节数组
byte[] b = "abcdefg".getBytes();
test(b);
}
public static void test(byte[] b) {
ByteArrayInputStream bais = null;
StringBuilder sb = new StringBuilder();
int temp = 0;
//用于保存读取的字节数
int num = 0;
try {
//该构造方法的参数是一个字节数组,这个字节数组就是数据源
bais = new ByteArrayInputStream(b);
while ((temp = bais.read()) != -1) {
sb.append((char) temp);
num++;
}
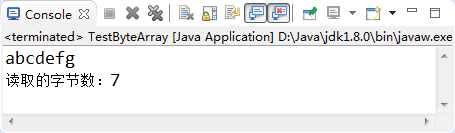
System.out.println(sb);
System.out.println("读取的字节数:" + num);
} finally {
try {
if (bais != null) {
bais.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
数据流DataInputStream
数据流将“基本数据类型与字符串类型”作为数据源,从而允许程序以与机器无关的方式从底层输入输出流中操作Java基本数据类型与字符串类型。
DataInputStream和DataOutputStream提供了可以存取与机器无关的所有Java基础类型数据(如:int、double、String等)的方法。
DataInputStream和DataOutputStream是处理流,可以对其他节点流或处理流进行包装,增加一些更灵活、更高效的功能。
【示例10-10】DataInputStream和DataOutputStream的使用
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestDataStream {
public static void main(String[] args) {
DataOutputStream dos = null;
DataInputStream dis = null;
FileOutputStream fos = null;
FileInputStream fis = null;
try {
fos = new FileOutputStream("D:/data.txt");
fis = new FileInputStream("D:/data.txt");
//使用数据流对缓冲流进行包装,新增缓冲功能
dos = new DataOutputStream(new BufferedOutputStream(fos));
dis = new DataInputStream(new BufferedInputStream(fis));
//将如下数据写入到文件中
dos.writeChar('a');
dos.writeInt(10);
dos.writeDouble(Math.random());
dos.writeBoolean(true);
dos.writeUTF("北京尚学堂");
//手动刷新缓冲区:将流中数据写入到文件中
dos.flush();
//直接读取数据:读取的顺序要与写入的顺序一致,否则不能正确读取数据。
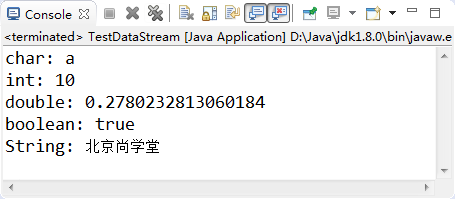
System.out.println("char: " + dis.readChar());
System.out.println("int: " + dis.readInt());
System.out.println("double: " + dis.readDouble());
System.out.println("boolean: " + dis.readBoolean());
System.out.println("String: " + dis.readUTF());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(dos!=null){
dos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if(dis!=null){
dis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if(fos!=null){
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
try {
if(fis!=null){
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
菜鸟雷区
使用数据流时,读取的顺序一定要与写入的顺序一致,否则不能正确读取数
对象流ObjectInputStream
我们前边学到的数据流只能实现对基本数据类型和字符串类型的读写,并不能读取对象(字符串除外),如果要对某个对象进行读写操作,我们需要学习一对新的处理流:ObjectInputStream/ObjectOutputStream。
ObjectInputStream/ObjectOutputStream是以“对象”为数据源,但是必须将传输的对象进行序列化与反序列化操作。
序列化与反序列化的具体内容,请见<10.3 Java对象的序列化和反序列化>。示例10-11仅演示对象流的简单应用。
【示例10-11】ObjectInputStream/ObjectOutputStream的使用
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.util.Date;
public class TestObjectStream {
public static void main(String[] args) throws IOException, ClassNotFoundException {
write();
read();
}
/**使用对象输出流将数据写入文件*/
public static void write(){
// 创建Object输出流,并包装缓冲流,增加缓冲功能
OutputStream os = null;
BufferedOutputStream bos = null;
ObjectOutputStream oos = null;
try {
os = new FileOutputStream(new File("d:/bjsxt.txt"));
bos = new BufferedOutputStream(os);
oos = new ObjectOutputStream(bos);
// 使用Object输出流
//对象流也可以对基本数据类型进行读写操作
oos.writeInt(12);
oos.writeDouble(3.14);
oos.writeChar('A');
oos.writeBoolean(true);
oos.writeUTF("北京尚学堂");
//对象流能够对对象数据类型进行读写操作
//Date是系统提供的类,已经实现了序列化接口
//如果是自定义类,则需要自己实现序列化接口
oos.writeObject(new Date());
} catch (IOException e) {
e.printStackTrace();
} finally {
//关闭输出流
if(oos != null){
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bos != null){
try {
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(os != null){
try {
os.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
/**使用对象输入流将数据读入程序*/
public static void read() {
// 创建Object输入流
InputStream is = null;
BufferedInputStream bis = null;
ObjectInputStream ois = null;
try {
is = new FileInputStream(new File("d:/bjsxt.txt"));
bis = new BufferedInputStream(is);
ois = new ObjectInputStream(bis);
// 使用Object输入流按照写入顺序读取
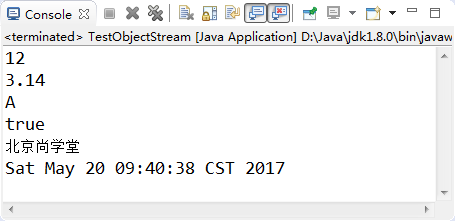
System.out.println(ois.readInt());
System.out.println(ois.readDouble());
System.out.println(ois.readChar());
System.out.println(ois.readBoolean());
System.out.println(ois.readUTF());
System.out.println(ois.readObject().toString());
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭Object输入流
if(ois != null){
try {
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(bis != null){
try {
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if(is != null){
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
注意
\1. 对象流不仅可以读写对象,还可以读写基本数据类型。
\2. 使用对象流读写对象时,该对象必须序列化与反序列化。
\3. 系统提供的类(如Date等)已经实现了序列化接口,自定义类必须手动实现序列化接口。
转换流InputStreamReader
InputStreamReader/OutputStreamWriter用来实现将字节流转化成字符流。比如,如下场景:
System.in是字节流对象,代表键盘的输入,如果我们想按行接收用户的输入时,就必须用到缓冲字符流BufferedReader特有的方法readLine(),但是经过观察会发现在创建BufferedReader的构造方法的参数必须是一个Reader对象,这时候我们的转换流InputStreamReader就派上用场了。
而System.out也是字节流对象,代表输出到显示器,按行读取用户的输入后,并且要将读取的一行字符串直接显示到控制台,就需要用到字符流的write(String str)方法,所以我们要使用OutputStreamWriter将字节流转化为字符流。
reader = new BufferedReader(
new InputStreamReader(new FileInputStream(srcFile),
srcEncoding));
【示例10-12】使用InputStreamReader接收用户的输入,并输出到控制台
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class TestConvertStream {
public static void main(String[] args) {
// 创建字符输入和输出流:使用转换流将字节流转换成字符流
BufferedReader br = null;
BufferedWriter bw = null;
try {
br = new BufferedReader(new InputStreamReader(System.in));
bw = new BufferedWriter(new OutputStreamWriter(System.out));
// 使用字符输入和输出流
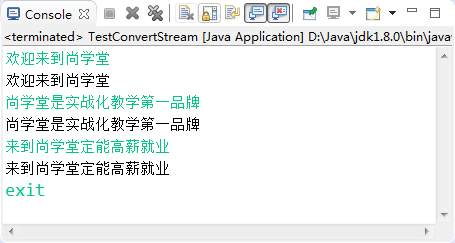
String str = br.readLine();
// 一直读取,直到用户输入了exit为止
while (!"exit".equals(str)) {
// 写到控制台
bw.write(str);
bw.newLine();// 写一行后换行
bw.flush();// 手动刷新
// 再读一行
str = br.readLine();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
// 关闭字符输入和输出流
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (bw != null) {
try {
bw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-otmvtkfe-1609674001044)(https://raw.githubusercontent.com/FermHan/tuchuang/master/20190927233717.png)]
File类
java.io.File类:文件和目录路径名的抽象表示形式,与平台无关
File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
File对象可以作为参数传递给流的构造函数
File类的常见构造方法:
public File(String pathname)
以pathname为路径创建File对象,可以是绝对路径或者相对路径,如果pathname是相对路径,则默认的当前路径在系统属性user.dir中存储。
public File(String parent,String child)
以parent为父路径,child为子路径创建File对象。
File的静态属性String separator存储了当前系统的路径分隔符。
在UNIX中,此字段为‘/’,在Windows中,为‘\’
File 类代表与平台无关的文件和目录。
File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。(可以把日记本放在各种地方,但是不能在日记本中写日记)
iO流用来处理设备之间的数据传输。
Java程序中,对于数据的输入/输出操作以”流(stream)” 的方式进行。
java.io包下提供了各种“流”类和接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。
import java.io.File;
import java.io.IOException;
File.separator //分隔符
File f = new File("D:\\test\\abc\\tt.txt");//此时文件并不一定存在,
f.getName();//文件名
访问文件名:
getName();
getPath()
getAbsoluteFile()
getAbsolutePath()
getParent()//返回当前文件或者文件夹的父级路径
renameTo(File 新名字); //f.renameTo(new File("D:\\test\\abc\\tt1.txt"))
文件检测:
exist()//判断文件或者文件夹是否存在
canWrite()//判断文件是否可写
canRead()
isFile()//判断当前的file对象是不是文件
isDirectory();//判断当前的file对象是不是文件夹或者目录
获取常规文件信息:
lastModify()//获取文件的最后修改时间,返回的是一个毫秒数
length()//返回文件的长度,单位是字节数
文件操作相关:
createNewFile()//new File("D:\\tt.txt");并没有创建文件//没有后缀时用的是mkDir
delete()//删除文件
目标操作相关:
f.mkDir()、f.mkdirs()
list()//返回的是当前文件夹的子集的名称,包括目录和文件 //for(String s : fl)
listFiles()//返回的是当前文件夹的子集的file对象,包括目录和文件 //for(File ff : fs)
File类既能代表一个特定文件的名称,又能代表一个目录。目录的话我们通常使用list()方法,无参时仅仅返回文件夹下的文件列表。如果带参数的话,可以配合list()和FilenameFilter和Pattern类实现过滤,如找.java结尾的文件,详情可以参考java编程思想的525页。
package day12;
import java.io.File;
import java.io.IOException;
public class Test {
public static void main(String[] args) {
// File f = new File("D:\\test\\abc\\tt.txt");//这个时候对象f就是tt.txt文件
// File f4 = new File("D:\\test\\abc");//这个目录
// File f2 = new File("D:/test/abc/tt.txt");
// File f3 = new File("D:" + File.separator + "test\\abc\\tt.txt");
// if(!f8.exists()){
// try {
// f8.createNewFile();//创建新的文件
// } catch (IOException e) {
// e.printStackTrace();
// }
// }
//
// File f9 = new File("D:\\test\\abc\\cc");
// File f9 = new File("D:\\test\\abc\\cc\\dd");
// f9.mkdir();//创建单层目录,如果使用这一方法来创建多层目录,就得一层一层的执行mkdir()
// File f10 = new File("D:\\test\\abc\\a\\b\\c");
// f10.mkdirs();//这个方法是直接用来创建多层目录
//
// File f11 = new File("D:\\test");
// String[] fl = f11.list();//返回的是当前文件夹的子集的名称,包括目录和文件
// for(String s : fl){
// System.out.println(s);
// }
// File[] fs = f11.listFiles();//返回的是当前文件夹的子集的file对象,包括目录和文件
// for(File ff : fs){
// System.out.println(ff);
// }
//遍历d盘下的test文件,把test文件夹下所有的目录与文件全部遍历出来,不论层级有多深,要全部遍历出来
//这个使用递归的方式来实现
File f = new File("D:\\test");
new Test().test(f);
}
/**
* 递归遍历文件
*/
public void test(File file){
if(file.isFile()){
System.out.println(file.getAbsolutePath() + " 是文件");
}else{
System.out.println(file.getAbsolutePath() + " 是文件夹");
//如果是文件夹,这个文件夹里就可能有子文件夹或者文件
File[] fs = file.listFiles();//获取当前文件夹下的子文件夹或者文件的file对象
if(fs != null && fs.length > 0){for(File ff : fs){test(ff);}}//递归
}
}
}
FileInputStream
FileInputStream(File file)
通过打开与实际文件的连接创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。
FileInputStream(FileDescriptor fdObj)
创建 FileInputStream通过使用文件描述符 fdObj ,其表示在文件系统中的现有连接到一个实际的文件。
FileInputStream(String name)
通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
FileInputStream in = new FileInputStream("D:/test/abc/tt1.txt");
in.close();//注意。流在使用完毕之后一段要关闭
FileOutputStream out = new FileOutputStream("D:/test/abc/tt4.txt");//指定行tt4输出数据
out.write(str.getBytes());//把数据写到内存
out.flush();//把内存中的数据刷写到硬盘
out.close();//关闭流
| 返回值 | 输入流方法 |
|---|---|
int |
available() 返回从此输入流中可以读取(或跳过)的剩余字节数的估计值,而不会被下一次调用此输入流的方法阻塞。 |
void |
close() 关闭此文件输入流并释放与流相关联的任何系统资源。 |
protected void |
finalize() 确保当这个文件输入流的 close方法没有更多的引用时被调用。 |
FileChannel |
getChannel() 返回与此文件输入流相关联的唯一的FileChannel对象。 |
FileDescriptor |
getFD() 返回表示与此 FileInputStream正在使用的文件系统中实际文件的连接的 FileDescriptor对象。 |
int |
read() 从该输入流读取一个字节的数据。 |
int |
read(byte[] b) 从该输入流读取最多 b.length个字节的数据为字节数组。 // in.read方法有一个返回值,返回值是读取的数据的长度,如果读取到最后一个数据,还会向后读一个,这个时候返回值就是-1 |
int |
read(byte[] b, int off, int len) 从该输入流读取最多 len字节的数据为字节数组。 |
long |
skip(long n) 跳过并从输入流中丢弃 n字节的数据。 |
| 返回值 | 输出流方法 |
|---|---|
void |
close() 关闭此文件输出流并释放与此流相关联的任何系统资源。 |
protected void |
finalize() 清理与文件的连接,并确保当没有更多的引用此流时,将调用此文件输出流的 close方法。 |
FileChannel |
getChannel() 返回与此文件输出流相关联的唯一的FileChannel对象。 |
FileDescriptor |
getFD() 返回与此流相关联的文件描述符。 |
void |
write(byte[] b) 将 b.length个字节从指定的字节数组写入此文件输出流。 |
void |
write(byte[] b, int off, int len) 将 len字节从位于偏移量 off的指定字节数组写入此文件输出流。 |
void |
write(int b) 将指定的字节写入此文件输出流。 |
| flush | 刷新此输出流并强制任何缓冲的输出字节被写出。flush的一般合同是,呼叫它表明,如果先前写入的任何字节已经通过输出流的实现进行缓冲,则这些字节应该立即被写入到它们的预定目的地。如果此流的预期目标是由底层操作系统(例如文件)提供的抽象,那么刷新流仅保证先前写入流的字节传递到操作系统进行写入; 它并不保证它们实际上被写入物理设备,如磁盘驱动器。 该flush的方法OutputStream什么都不做。 |
package day12;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
public class Test1 {
public static void main(String[] args) {
// Test1.testFileInputStream();
// Test1.testFileOutputStream();
// Test1.copyFile("D:/test/abc/tt1.txt","D:/test/abc/cc/tt1.txt");
Test1.copyFile("D:/test/abc/img.png","D:/test/abc/cc/img.png");
}
/**
* 文件字节输入流FileInputStream
* 在读取文件时,必须保证该文件已存在,否则出异常
*/
public static void testFileInputStream(){
try {
FileInputStream in = new FileInputStream("D:/test/abc/tt1.txt");
byte[] b = new byte[10];//设置一个byte数组接收读取的文件的内容
int len = 0;//设置一个读取数据的长度
// in.read(b);//in.read方法有一个返回值,返回值是读取的数据的长度,如果读取到最后一个数据,还会向后读一个,这个时候返回值就是-1,也就意味着当in.read的返回值是-1的时候整个文件就读取完毕了//也有可能说错了,可能先返回了3个,下次才返回-1
while((len = in.read(b)) != -1){
System.out.println(new String(b,0,len));
//new String(b,0,len),参数1是缓冲数据的数组,参数2是从数组的那个位置开始转化字符串,参数3是总共转化几个字节
}
in.close();//注意。流在使用完毕之后一段要关闭
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件字节输出流FileOutputStream
* 在写入一个文件时,如果目录下有同名文件将被覆盖
*/
public static void testFileOutputStream(){
try {
FileOutputStream out = new FileOutputStream("D:/test/abc/tt4.txt");//指定行tt4输出数据
String str = "knsasjadkajsdkjsa";
out.write(str.getBytes());//把数据写到内存
out.flush();//把内存中的数据刷写到硬盘
out.close();//关闭流
} catch (Exception e) {
e.printStackTrace();
}
}
/** 练习:
* 复制文件到指定位置
* @param inPath 源文件路径
* @param outPanth 复制到的文件夹位置
*/
public static void copyFile(String inPath, String outPanth){
try {
FileInputStream in = new FileInputStream(inPath);//读取的源文件
FileOutputStream out = new FileOutputStream(outPanth);//复制到哪里
byte[] b = new byte[100];
int len = 0;
while((len = in.read(b)) != -1){
out.write(b, 0, len);//参数1是写的缓冲数组,参数2是从数组的那个位置开始,参数3是获取的数组的总长度
}
out.flush();//把写到内存的数据刷到硬盘
out.close();
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
FileReader
文件字符输入流
读取文件操作步骤:
1.建立一个流对象,将已存在的一个文件加载进流。
FileReader fr = new FileReader(“Test.txt”);
2.创建一个临时存放数据的数组。
char[] ch = new char[1024];
3.调用流对象的读取方法将流中的数据读入到数组中。
fr.read(ch);
输出流:
1.创建流对象,建立数据存放文件
FileWriter fw = new FileWriter(“Test.txt”);
2.调用流对象的写入方法,将数据写入流
fw.write(“text”);
2.1 输出流关闭之前需要清空缓存
fw.flush();
3.关闭流资源,并将流中的数据清空到文件中。
fw.close();
package day12;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Test2 {
public static void main(String[] args) {
Test2.testFileReader("D:/test/abc/tt1.txt");
//在写入一个文件时,如果目录下有同名文件将被覆盖。
// Test2.testFileWriter("!!!!!!!", "D:/test/abc/tt5.txt");
// Test2.copyFile("D:/test/abc/tt5.txt", "D:/test/abc/cc/tt5.txt");
}
/**
* 文件字符输入流FileReader
* 在读取文件时,必须保证该文件已存在,否则出异常
* @param inPath
*/
public static void testFileReader(String inPath){
try {
FileReader fr = new FileReader(inPath);//创建文件字符输入流的对象
char[] c = new char[10];//创建临时存数据的字符数组
int len = 0;//定义一个输入流的读取长度
while((len = fr.read(c)) != -1){
System.out.println(new String(c, 0, len));
}
fr.close();//关闭流
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 文件字符输出流FileWriter
* 在写入一个文件时,如果目录下有同名文件将被覆盖
* @param text 输出的内容
* @param outPath 输出的文件
*/
public static void testFileWriter(String text,String outPath){
try {
FileWriter fw = new FileWriter(outPath);
fw.write(text);//写到内存中
fw.flush();//把内存的数据刷到硬盘
fw.close();//关闭流
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 字符流完成拷贝文件,字符流只适合操作内容是字符文件
* @param inPaht
* @param outPath
*/
public static void copyFile(String inPath, String outPath){
try {
FileReader fr = new FileReader(inPath);
FileWriter fw = new FileWriter(outPath);
char[] c = new char[100];
int len = 0;
while((len = fr.read(c)) != -1){//读取数据
fw.write(c,0,len);//写数据到内存
}
fw.flush();
fw.close();
fr.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
RandomAccessFile
RandomAccessFile适用于由大小已知的记录组成的文件,所以我们可以使用seek()将记录从处转移到另一处,然后读取或者修改记录。文件中记录的大小不一定都相同,只要我们能够确定那些记录有多大以及它们在文件中的位置即可。
最初,我们可能难以相信 RandomAccessFile不是 Inputstrean或者 OutputStream继承层次结构中的一部分。除了实现了 DataInput和 DataOutput接口( DataInputStream和 DataOutputStream也实现了这两个接口)之外,它和这两个继承层次结构没有任何关联。它甚至不使用InputStream和 Outputstream类中已有的任何功能。它是一个完全独立的类,从头开始编写其所有的方法(大多数都是本地的)。这么做是因为 RandomAccessFile拥有和别的I/O类型本质不同的
后为,因为我们可以在一个文件内向前和向后移动,在任何情况下,它都是自我独立的,直接从Object派生而来。
从本质上来说, RandomAccessFile的工作方式类似于把 DataInputStreamA和 DataOutStream组合起来使用,还添加了一些方法。其中方法 :getFilePointer用于查找当前所处的文件位置
seO用于在文件内移至新的位置, length用于判断文件的最大尺寸。另外,其构造器还需要
第二个参数(和C中的 fopen相同)用来指示我们只是“随机读”®还是“既读又写”(rw)。
它并不支持只写文件,这表明 Random AccessFile若是从 DataInputStream继承而来也可能会运行
得很好。
中
只有 Randon accessfile持搜寻方法,并且只适用于文件。 BufferedInputStream却能允许标注(maO)位置(其值存储于内部某个简单变量内)和重新设定位置( reset(0),但这些功能很有限,不是非常有用。
在JDK14中, RandomAccess File大多数功能(但不是全部)由nio存储映射文件所取代,本章稍后会讲述。
B6O流的典型使用方式
尽管可以通过不同的方式组合O流类,但我们可能也就只用到其中的几种组合。下面的例
子可以作为典型的O用法的基本参考。在这些示例中,异常处理都被简化为将异常传递给控制
URL类
URL url = new URL("http://www.baidu.com");
InputStreamReader isr = new InputStreamReader(url.openStream());
BufferedReader br = new BufferedReader(isr);
String s;
while((s.br.readLine())!=null){
sout(s);
}
br.close();