lead 和 lag
前面我们学习的first_value和last_value 取的是排序后的数据截止当前行的第一行数据和最后一行数据
Lag和Lead分析函数可以在一次查询中取出当前行后N行的数据,虽然可以不用排序,但是往往只有在排序的场景下取前面或者后面N 行数据才有意义
这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
Lag/Lead(col,n,DEFAULT) 用于统计窗口内当前行往前或者往后第n行值
- 第一个参数为列名,
- 第二个参数为往上第n行(可选,默认为1),
- 第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
需要注意的是lag 取得是当前行之前的数据,lead 取的实当前行之后的数据
测试数据
我们有这样一个文本user_access_log.txt,里面记录了用户对页面的访问情况id,ctime,url 分别代表了用户ID,访问时间和访问的页面的URL
Peter 2015-10-12 01:10:00 url1
Peter 2015-10-12 01:15:10 url2
Peter 2015-10-12 01:16:40 url3
Peter 2015-10-12 02:13:00 url4
Peter 2015-10-12 03:14:30 url5
Marry 2015-11-12 01:10:00 url1
Marry 2015-11-12 01:15:10 url2
Marry 2015-11-12 01:16:40 url3
Marry 2015-11-12 02:13:00 url4
Marry 2015-11-12 03:14:30 url5
数据说明:Peter 2015-10-12 01:10:00 url1 ,表示Peter在2015-10-12 01:10:00进入了网页url1,即记录的是进入网页的时间。
create table ods_user_log(
userid string,
ctime string,
url string
) row format delimited fields terminated by '\t';
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/workspace/hive/user_access_log.txt' OVERWRITE INTO TABLE ods_user_log;
从例子中学习lead 和 lag
计算当前用户的第一次访问时间以及当前访问时间的上一次访问时间和下一次访问时间
从描述我们知道了分区的条件或者子窗口的定义条件是用户本身,从我们前面的学习中我们知道了第一次访问时间我们可以使用first_value 计算,下面我们看一下这个需求如何实现
select
userid,url,ctime,
first_value(ctime) over(partition by userid order by ctime) as first_ctime,
lag(ctime,1) over(partition by userid order by ctime) as lag_ctime,
lead(ctime,1) over(partition by userid order by ctime) as lead_ctime
from
ods_user_log
;

这里我们也对这个结果简单分析一下,对于第一行数据它是没有lag_ctime的,也就是没有上一次访问时间,因为它是第一次访问,对于lead_ctime也就是下一次访问时间2015-11-12 01:15:10
计算用户在每个页面上的停留时长
用户Peter在浏览网页,在某个时刻,Peter点进了某个页面,过一段时间后,Peter又进入了另外一个页面,如此反复,那怎么去统计Peter在某个特定网页的停留时间呢,又或是怎么统计某个网页用户停留的总时间呢?
要计算Peter在页面url1停留的时间,需要用进入页面url2的时间,减去进入url1的时间,即2015-10-12 01:15:10这个时间既是离开页面url1的时间,也是开始进入页面url2的时间。所以我们需要先获取用户在某个页面停留的起始与结束时间
select
userid,url,ctime as startTime,
lead(ctime,1) over(partition by userid order by ctime) as leaveTime
from
ods_user_log
;
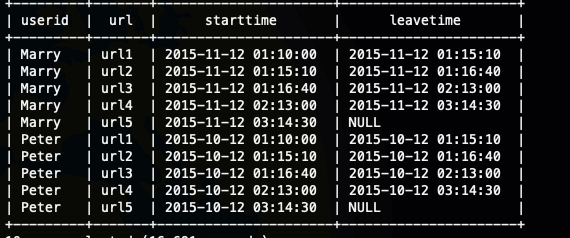
有了进入时间和离开时间我们就很容易计算出用户在特定页面上的停留时间,只需要用离开时间减去进入时间即可
select
userid,url,ctime as startTime,
lead(ctime,1) over(partition by userid order by ctime) as leaveTime,
unix_timestamp(lead(ctime,1) over(partition by userid order by ctime) ) -unix_timestamp(ctime) as stayTime
from
ods_user_log
;
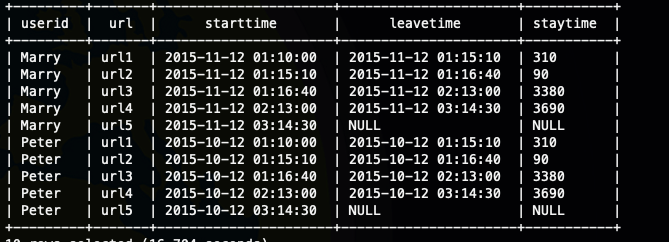
大家考虑一个问题如果没有lag和lead这样的函数,我们该如何实现这个需求呢,我们可以借助自关联来实现,但是这个自关联就有很多种是想方式了,这里我借助row_number 来实现一种
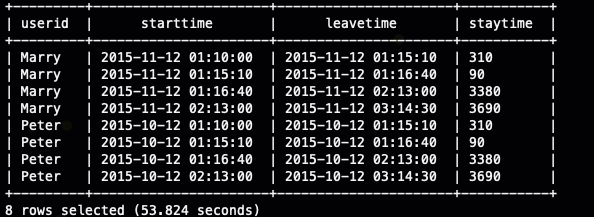
with a as (
select
userid,url,ctime as startTime,
row_number() over (partition by userid order by ctime ) as rn
from
ods_user_log
)
select
a1.userid userid,a1.startTime startTime,a2.startTime leaveTime,unix_timestamp(a2.startTime )-unix_timestamp(a1.startTime ) as stayTime
from
a a1
inner join
a a2
on
a1.userid=a2.userid
and (a2.rn-a1.rn=1)
;
这里我们主要是使用 (a2.rn-a1.rn=1) 的条件找出了用户进入页面和离开页面的时间
使用场景
lead 和 lag 的使用场景其实是比较多的,尤其我们在计算需要自关联的这种场景下,如果合理使用头是可以很好的提高我们程序的性能和简化我们的写法,下面我们再看一个例子
有个日志表中记录了商户费率变化状态的所有信息用户ID,费率,时间,现在有个需求,要取出按照时间轴顺序,发生了费率变化的数据行,输出数据格式商户ID,当前时间,变化时间,原始费率,变化后的费率
100,0.1,2016-03-02
100,0.1,2016-02-02
100,0.2,2016-03-05
100,0.2,2016-03-06
100,0.3,2016-03-07
100,0.1,2016-03-09
100,0.1,2016-03-10
100,0.1,2016-03-10
200,0.1,2016-03-10
200,0.1,2016-02-02
200,0.2,2016-03-05
200,0.2,2016-03-06
200,0.3,2016-03-07
200,0.1,2016-03-09
200,0.1,2016-03-10
200,0.1,2016-03-10
现在我们开始建表
create table ods_user_rate_log(
userid string,
rate double,
ctime string
) row format delimited fields terminated by ',';
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/workspace/hive/ods_user_rate_log.txt' OVERWRITE INTO TABLE ods_user_rate_log;
现在们分析一下,首先我们是单独计每个商户的,所以我们的子窗口定义条件就是用户ID,然后我们跟踪的是费率的随时间的变化所以我们是要按照时间排序,最后我们需要的费率发生了变化的数据,所以我们需要比较一下原始费率和下一次费率
第一步:获取当前费率和下一次的费率
select
userid ,ctime,rate , lead(rate,1) over (partition by userid order by ctime) new_rate
from
ods_user_rate_log
;
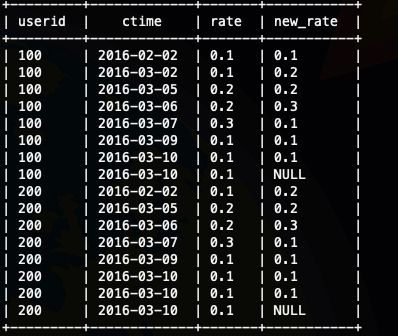
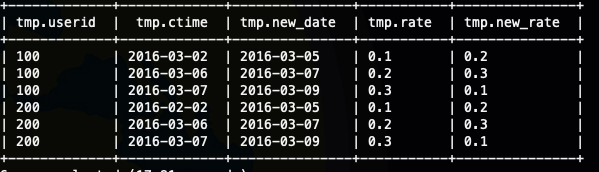
第二步:找出费率不同的记录然后返回,需要注意的是,我们还需要需要获取到发生变化的时间
select
*
from (
select
userid,
ctime,
lead(ctime, 1) over (partition by userid order by ctime) new_date,
rate,
lead(rate, 1) over (partition by userid order by ctime) new_rate
from ods_user_rate_log
) tmp
where
rate!=new_rate
;
总结
- lag和lead 主要用来计算当前行的前后N 行的这种场景,一般情况下我们会对数据进行排序,因为只有在有序的情况下,前面多少行和后面多少行才有意义
- lag和lead 可以用在某些场景下代替自关联的写法