Hamming OCR是一个基于Transformer注意力的超轻量级文本识别模型,主要基于LSH局部敏感哈希编码和Max-Margin Loss的学习算法。
Hamming OCR: A Locality Sensitive Hashing Neural Networkfor SceneText Recognition
本文为极市开发者投稿,作者平安产险视觉计算组,转载请获授权。
背景
场景文本识别中很多模型都使用了笨重的模型,这些模型很难在移动端设备上部署。这也是最近大火的Paddle OCR使用CRNN实现其超轻量级识别模型的原因。PaddleOCR采用的策略就是暴力削减特征通道来减小模型,但是这样使得性能大幅度下降。最近在arXiv上公开的Hamming OCR提出了Hamming Embedding和LSH局部敏感哈希分类的算法,大幅度削减模型大小,同时保留模型能力。
简介
我们首先看FC+softmax分类层:

其中分类矩阵W占了将近20MB,这是因为onehot编码方式维度过大,字符字数多的原因。
对应的Hamming OCR中的LSH局部敏感哈希分类实现如下:

Hamming OCR使用LSH编码替代了onehot编码,把分类矩阵W的大小降低到0.5MB。初始阶段,HammingOCR使用LSH和voting生成每个字符的LSH编码。然后基于生成的LSH code采用Max-Margin算法优化。
在推理阶段,Hamming OCR二值化logit,然后跟所有字符的LSH编码计算汉明距离,距离最近字符的即为预测结果。
LSH编码很好地保留了字符之间的相似度,如下图:



很多识别模型使用Output Embedding来表达每个字符,Embedding层占了20MB。因为LSH编码的良好特性,Hamming OCR直接使用LSH编码作为字母的表达,也就是Hamming Embedding,减少20MB并且不损失精度。
Hamming OCR还加入了跨层共享Transformer权重、去除Feed-ForwardNetwork和FP16,最终模型只有3.9MB。模型结构如下图:
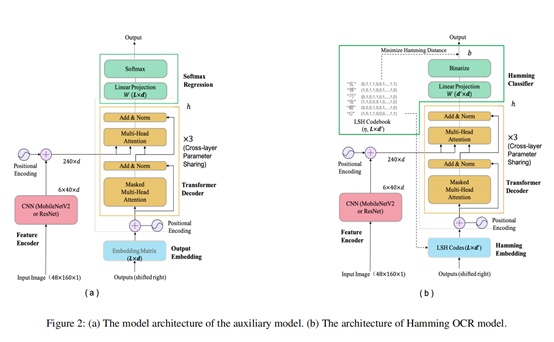
Hamming OCR模型的能力很强,如下图所示,最终模型不但比PaddleOCR小,精度还要更高。

模型各阶段优化之后的参数量如下图,

结论
- Hamming OCR模型小
- 模型能力很强
- 支持的字符数量超大
- 便于移动端部署
论文链接:https://arxiv.org/pdf/2009.10874.pdf
参考文献
- Lu, N.; Yu,W.; Qi, X.; Chen, Y.; Gong, P.; and Xiao, R. 2019. Master: Multi-aspectnon-local network for scene text recognition. arXiv preprint arXiv:1910.02562.
- Li, H.;Wang, P.; Shen, C.; and Zhang, G. 2019. Show, attend and read: A simple andstrong baseline for irregular text recognition. In Proceedings of the AAAIConference on Artificial Intelligence, volume 33, 8610–8617.
- Shi, B.;Bai, X.; and Yao, C. 2016. An end-to-end trainable neural network forimage-based sequence recognition and its application to scene text recognition.IEEE transactions on pattern analysis and machine intelligence 39(11):2298–2304.
- Lan, Z.;Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; and Soricut, R. 2019. Albert: Alite bert for selfsupervised learning of language representations. arXiv preprintarXiv:1909.11942 .
作者团队
产险视觉计算组(VC组)专注解决金融保险领域的计算机视觉应用问题,在ICDAR 2019票据识别及关键信息3个任务中,团队分别斩获第二,第三,第一名。同时,在Kaggle举办的百度/北大无人驾驶比赛中,获得亚军。团队积极创新,已有多项自研OCR 、关键性信息抽取技术。