Java 线程:使用篇
如何在 Java 中使用多线程
继承 Thread 类
// 自定义线程对象
class MyThread extends Thread {
public void run() {
// 线程需要执行的代码
}
}
// 创建线程对象并启动线程
MyThread myThread = new MyThread();
myThread.start();
Java 的 Thread 类中,所有关键方法都是 native 的,说明这些方法无法使用平台无关的手段实现。
实现 Runnable 接口
// 实现 Runnable 接口
class Runner implements Runnable {
@Override
public void run() {
// 线程需要执行的代码
}
}
// 创建线程对象并启动线程
Thread thread = new Thread(new Runner());
thread.start();
实现 Callable 接口
Callable 接口的使用需要搭配线程池,由于这里还没有介绍线程池的概念,提前介绍可能会造成理解障碍,所以放在后续介绍线程池的部分,详见。。。
线程数配置原则
一般我们使用多线程是为了提高性能,这里的性能一般指的是 延迟 和 吞吐量,我们的目标是降低延迟,提高吞吐量。
- 延迟: 发出请求到收到响应这个过程的时间。
- 吞吐量: 单位时间内能处理请求的数量。
为了降低延迟,提高吞吐量,一般有以下两种常用手段:
- 优化算法。
- 将硬件的性能发挥到极致。
在并发编程领域,提升性能本质上就是提升硬件的利用率,尽可能的将硬件的能力压榨到极致。也就是说,我们的目标是让 CPU 时刻保持着 100% 的利用率,一刻也不停歇的工作着!
然而,线程也不是越多越好的,当一个 CPU 上同时又多个线程运行时,我们所看到的多个线程并行运行其实是一种伪并行,在同一时刻,真正运行的线程其实只有一个,只不过 CPU 在多个线程的运行之间不停的切换,让我们看起来好像是这些个线程在同时运行罢了。然而,线程运行的切换不是没有代价的,每次切换时,我们首先需要保存当前线程的上下文,然后再将下一个线程的上下文设置好。这个过程也是要消耗 CPU 时间的,如果 CPU 将大量的时间都花在了切换线程上,而非执行线程的任务上,那就得不偿失了。
在线程切换中,上下文一般指 CPU 寄存器和程序计数器中的内容。
那么我们应当创建多少线程合适呢?这要视线程执行的任务类型而定了。
一般我们的任务有以下两种类型:CPU 密集型的任务 和 I/O 密集型的任务,并且它们之间有着本质的区别:
- CPU 密集型的任务:
最佳线程数 = CPU 核数 + 1- 大多数时间里,只要在运行就有产出;
- 因此希望一个任务一直运行到底再运行下一个,而不是将时间耗费到线程的切换上(即上下文切换)。
- 后面的 “+1” 是为了一旦线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,以保证 CPU 的利用率。
- I/O 密集型的任务:
最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]- 一个任务从开始到完成的时间可能很长,但其间真正在干活(使用 CPU)的时间可能很短,大部分时间都在等待,如等待网络发来的数据包,或等待写入或读取磁盘上的数据等;
- 因此希望在没有产出的等待时间里,CPU 不是闲呆着,而是去做其他的事情。
- 示例:如 CPU 计算和 I/O 操作的耗时是 1:2,那多少个线程合适呢?答:3 个线程。
- 理想情况下,CPU 在线程 A、B、C 之间按如下方式进行切换,理论上可以实现 100% 的 CPU 利用率(当然这个得是超级理想了,现实中是基本不可能的)。
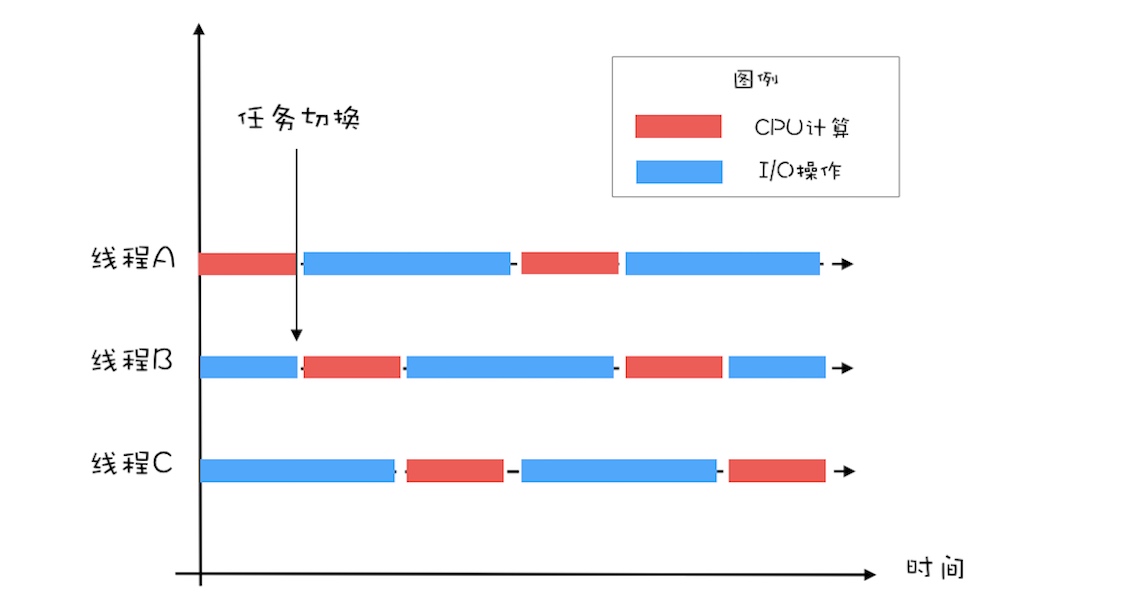
- 理想情况下,CPU 在线程 A、B、C 之间按如下方式进行切换,理论上可以实现 100% 的 CPU 利用率(当然这个得是超级理想了,现实中是基本不可能的)。
当然,以上对于线程数量配置的公式只是一个参考,Java 的老版本对于 Docker 容器的支持还不是那么的好,比如有时程序员在 Docker 容器中直接使用 Runtime.getRuntime().availableProcessors() * 2 配置线程池大小,对于早期版本的 JVM,这个 Runtime.getRuntime().availableProcessors() 会忽略 cgroup 的限制,返回实际物理机的 CPU 数,而当同一物理机上的有好多容器都进行了这样的线程池大小设置操作时,有一下子开启好多线程的风险,可能会导致物理机的崩溃,这种场景我们需要额外注意!
线程间的通信方式
选择通信
-
synchronized 和 volatile 关键字
- 这两个关键字可以保障线程对变量访问的可见性
-
等待/通知机制
- 详见
Ch3-Java并发高级主题/00-Java中的锁.md
- 详见
-
Thread#join()- 如果一个线程 A 执行了
threadA.join(),那么只有当线程 A 执行完之后,threadA.join()之后的语句才会继续执行,类似于创建 A 的线程要等待 A 执行完后才继续执行; - 使用 join 方法中线程被中断的效果 == 使用 wait 方法中线程被中断的效果,即会抛出 InterruptedException。因为 join 方法内部就是用 wait 方法实现的;
- join 还有一个带参数的方法:
join(long),这个方法是等待传入的参数的毫秒数,如果计时过程中等待的方法执行完了,就接着往下执行,如果计时结束等待的方法还没有执行完,就不再继续等待,而是往下执行。join(long)和sleep(long)的区别- 如果等待的方法提前结束,
join(long)不会再计时了,而是往下执行,而sleep(long)一定要等待够足够的毫秒数; join(long)会释放锁,sleep(long)不会释放锁,原因是join(long)方法内部是用wait(long)方法实现的。
- 如果等待的方法提前结束,
- 如果一个线程 A 执行了
-
管道流:
PipedInputStream&PipedOutputStreampublic class PipedStreamDemo { public static PipedInputStream in = new PipedInputStream(); public static PipedOutputStream out = new PipedOutputStream(); public static void send() { new Thread() { @Override public void run() { byte[] bytes = new byte[2000]; while (true) { try { out.write(bytes, 0, 2000); System.out.println("Send Success"); } catch (IOException e) { System.out.println("Send Failed"); e.printStackTrace(); } } } }.start(); } public static void receive() { new Thread() { @Override public void run() { byte[] bytes = new byte[100]; int len = 0; while (true) { try { len = in.read(bytes, 0, 100); System.out.println("len = " + len); } catch (IOException e) { System.out.println("Receive Failed"); e.printStackTrace(); } } } }.start(); } public static void main(String[] args) { try { in.connect(out); } catch (IOException e) { e.printStackTrace(); } receive(); send(); } }
选择不通信
有时,你也可以选择不通信,将变量封闭在线程内部,使用 ThreadLocal 可以实现这一效果,详见 。
上一篇:Java线程:使用篇
下一篇:Java线程:原理篇