首先 我们要爬取一下有关的数据
将数据分别存储在不同的文件中
方便接下来的数据处理
import time
import json
import requests
from datetime import datetime
import pandas as pd
import numpy as np
def catch_data():
url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
reponse = requests.get(url=url).json()
#返回数据字典
data = json.loads(reponse['data'])
return data
data = catch_data()
data.keys()
lastUpdateTime = data['lastUpdateTime']
# 数据明细,数据结构比较复杂,一步一步打印出来看,先明白数据结构
areaTree = data['areaTree']
# 国内数据
china_data = areaTree[0]['children']
china_list = []
for a in range(len(china_data)):
province = china_data[a]['name']
province_list = china_data[a]['children']
for b in range(len(province_list)):
city = province_list[b]['name']
total = province_list[b]['total']
today = province_list[b]['today']
china_dict = {
}
china_dict['province'] = province
china_dict['city'] = city
china_dict['total'] = total
china_dict['today'] = today
china_list.append(china_dict)
china_data = pd.DataFrame(china_list)
china_data.head()
# 定义数据处理函数
def confirm(x):
confirm = eval(str(x))['confirm']
return confirm
def dead(x):
dead = eval(str(x))['dead']
return dead
def heal(x):
heal = eval(str(x))['heal']
return heal
# 函数映射
china_data['confirm'] = china_data['total'].map(confirm)
china_data['dead'] = china_data['total'].map(dead)
china_data['heal'] = china_data['total'].map(heal)
china_data = china_data[["province","city","confirm","dead","heal"]]
china_data.head()
area_data = china_data.groupby("province")["confirm"].sum().reset_index()
area_data.column=["province","confirm"]
# print(area_data)
area_data.to_csv("confirm.csv", encoding="utf_8_sig")
area_data = china_data.groupby("province")["dead"].sum().reset_index()
area_data.column=["province","dead"]
# print(area_data)
area_data.to_csv("dead.csv", encoding="utf_8_sig")
area_data = china_data.groupby("province")["heal"].sum().reset_index()
area_data.column=["province","heal"]
# print(area_data)
area_data.to_csv("heal.csv", encoding="utf_8_sig")
还有一些传言的数据
import requests
import pandas as pd
class SpiderRumor(object):
def __init__(self):
self.url = "https://vp.fact.qq.com/loadmore?artnum=0&page=%s"
self.header = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
}
def spider_run(self):
df_all = list()
for url in [self.url % i for i in range(61)]:
data_list = requests.get(url, headers=self.header).json()["content"]
temp_data = [[df["title"], df["date"], df["result"], df["explain"], df["tag"]] for df in data_list]
df_all.extend(temp_data)
print(temp_data[0])
pd.DataFrame(df_all, columns=["title", "date", "result", "explain", "tag"]).to_csv("冠状病毒谣言数据.csv", encoding="utf_8_sig")
if __name__ == '__main__':
spider = SpiderRumor()
spider.spider_run()
数据都获取到了
然后我们来完成数据可视化吧!
先看一下matplotlib库做的可视化
折线图:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv('冠状病毒谣言数据.csv')
labels = data['date'].value_counts().index.tolist()
sizes = data['date'].value_counts().values.tolist()
plt.figure(figsize=(30, 8))
plt.plot(labels, sizes)
plt.xticks(labels, labels, rotation=45)
plt.title('每日谣言数量', fontsize=40)
plt.show()
效果图:

柱状图:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("冠状病毒谣言数据.csv")
df = pd.Series([j for i in [eval(i) for i in data["tag"].tolist()] for j in i]).value_counts()[:20]
X = df.index.tolist()
Y = df.values.tolist()
plt.figure(figsize=(15, 8)) # 设置画布
plt.bar(X, Y, color="blue")
plt.tight_layout()
plt.grid(ls='-.')
plt.show()
效果图:

饼图:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("冠状病毒谣言数据.csv")
labels = data["explain"].value_counts().index.tolist() # 可以理解为每个文本
sizes = data["explain"].value_counts().values.tolist() # 可以理解为筛选出每个文本所对应的出现次数
colors = ['lightgreen', 'gold', 'lightskyblue', 'lightcoral']
plt.figure(figsize=(18, 10))
plt.pie(sizes, labels=labels,
colors=None, autopct='%1.1f%%', shadow=True,
explode=(0.1, 0.1, 0, 0, 0, 0, 0, 0, 0, 0),
textprops={
'fontsize': 15, 'color': 'black'}) # shadow=True 表示阴影
plt.axis('equal') # 设置为正的圆形
plt.legend(loc='upper right', ncol=2)
plt.show()
效果图:
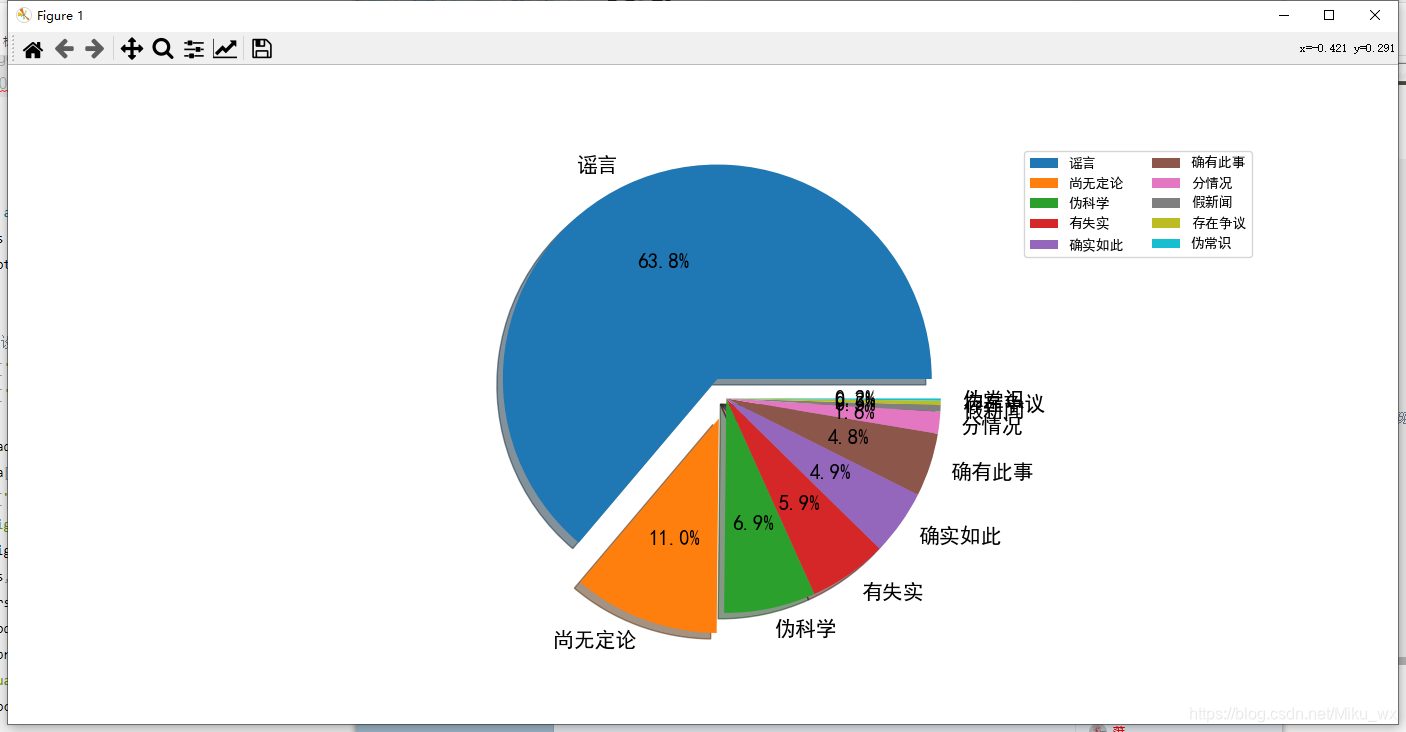
然后是pyecharts库的可视化
折线图:
import pandas as pd
import numpy as np
from pyecharts import Line
data = pd.read_csv("dead.csv")
x = data["province"]
y = data["dead"]
line = Line('国内死亡折线图')
line.add('确诊数', x, y, is_label_show=True)
line.render('国内死亡折线图.html')
line.render_notebook()
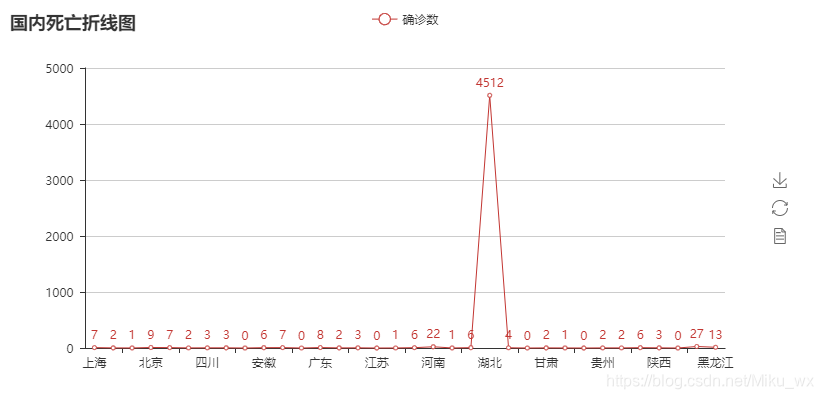
import pandas as pd
import numpy as np
from pyecharts import Line
data = pd.read_csv("heal.csv")
x = data["province"]
y = data["heal"]
line = Line('国内治愈折线图')
line.add('确诊数', x, y, is_label_show=True)
line.render('国内治愈折线图.html')
line.render_notebook()
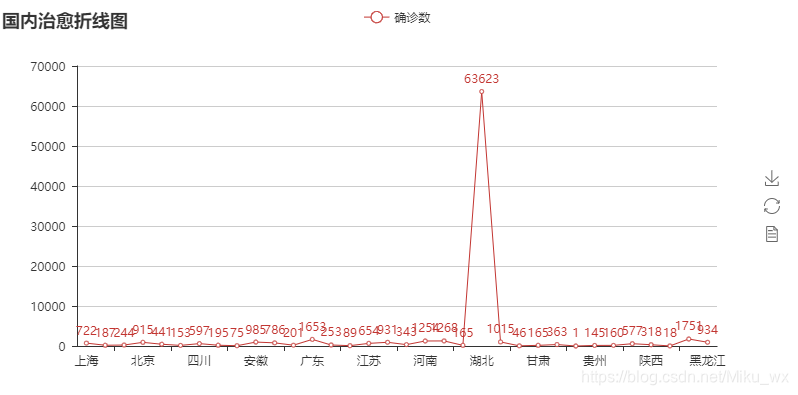
from pyecharts import Line
import numpy as np
import pandas as pd
data = pd.read_csv("dead.csv")
x = data["province"]
y = data["dead"]
data1 = pd.read_csv("heal.csv")
z = data1["heal"]
line = Line("治愈死亡折线图")
line.add("治愈", x, z, mark_point=["max", "min"], mark_line=["average"])
line.add("死亡", x, y, mark_point=["max", "min"], mark_line=["average"])
line.render("治愈死亡折线图.html")
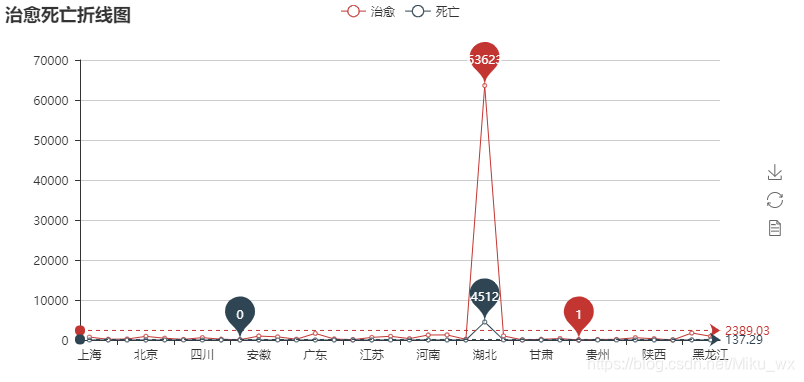
import pandas as pd
import numpy as np
from pyecharts import Line
data = pd.read_csv("confirm.csv")
x = data["province"]
y = data["confirm"]
line = Line('国内确诊折线图')
line.add('确诊数', x, y, is_label_show=True)
line.render('国内确诊折线图.html')
line.render_notebook()

柱状图:
from pyecharts import Bar
import numpy as np
import pandas as pd
data = pd.read_csv("dead.csv")
x = data["province"]
y = data["dead"]
data1 = pd.read_csv("heal.csv")
z = data1["heal"]
bar = Bar("治愈死亡柱状图")
bar.add("治愈", x, z, is_stack=True, is_label_show=True)
bar.add("死亡", x, y, is_stack=True, is_label_show=True)
bar.render("治愈死亡柱状图.html")
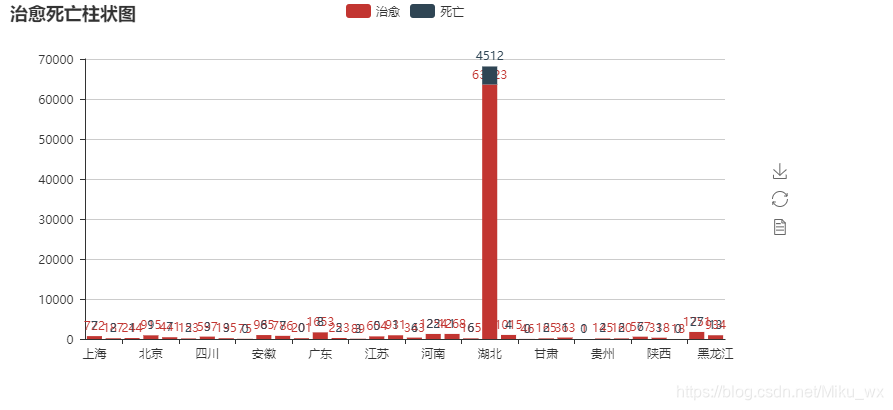
环图:
from pyecharts import Pie
import pandas as pd
import numpy as np
data = pd.read_csv("dead.csv")
x = data["province"]
y = data["dead"]
pie = Pie("死亡环图", title_pos='right')
pie.add(
"",
x,
y,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
is_more_utils=True,
legend_orient="vertical",
legend_pos="left",
)
pie.render(path="死亡环图.html")
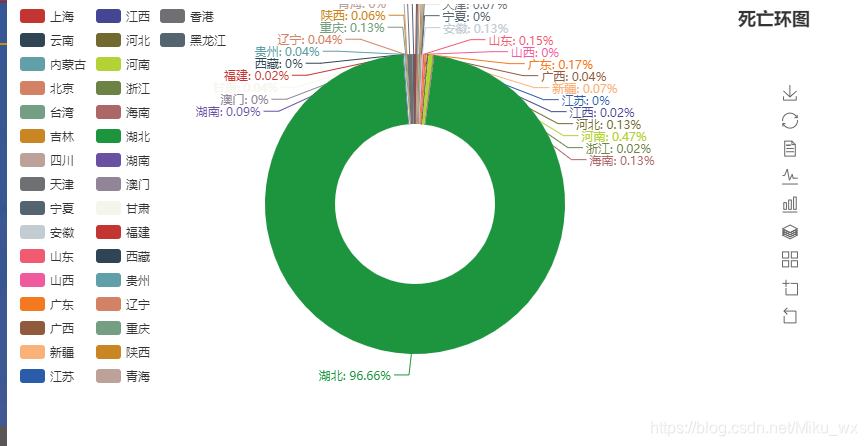
from pyecharts import Pie
import pandas as pd
import numpy as np
data = pd.read_csv("heal.csv")
x = data["province"]
y = data["heal"]
pie = Pie("治愈环图", title_pos='right')
pie.add(
"",
x,
y,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
is_more_utils=True,
legend_orient="vertical",
legend_pos="left",
)
pie.render(path="治愈环图.html")
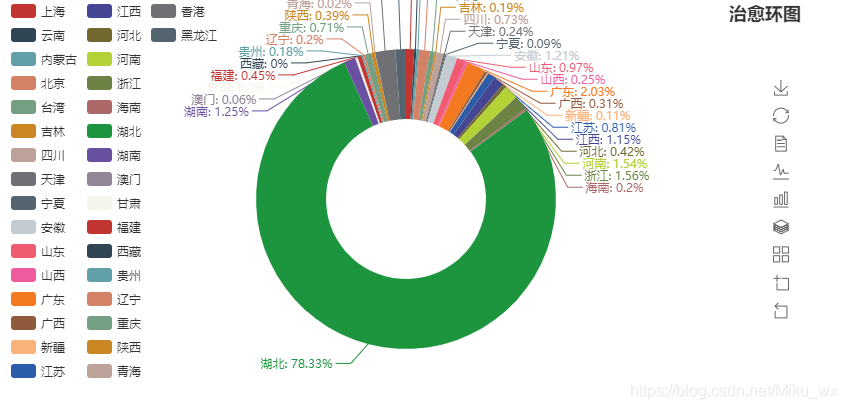
from pyecharts import Pie
import pandas as pd
import numpy as np
data = pd.read_csv("confirm.csv")
x = data["province"]
y = data["confirm"]
pie = Pie("确诊环图", title_pos='right')
pie.add(
"",
x,
y,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
is_more_utils=True,
legend_orient="vertical",
legend_pos="left",
)
pie.render(path="确诊环图.html")
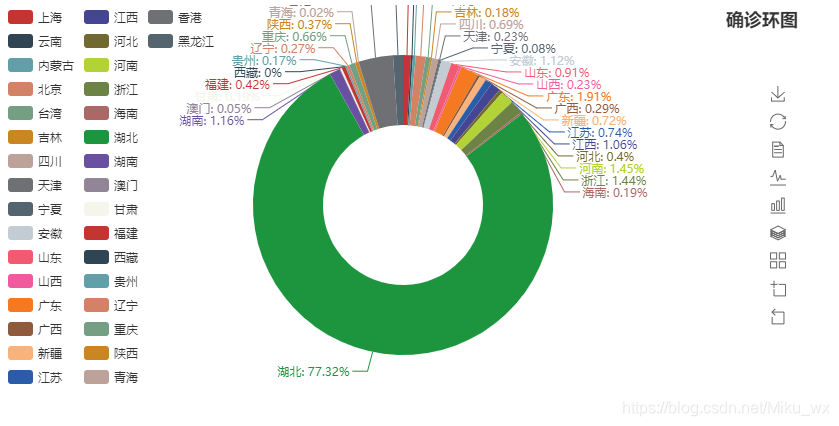
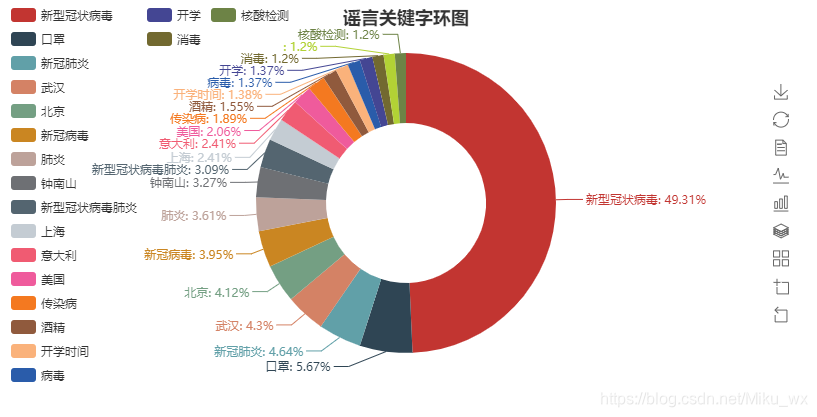
from pyecharts import Pie
import numpy as np
import pandas as pd
data = pd.read_csv("冠状病毒谣言数据.csv")
df = pd.Series([j for i in [eval(i) for i in data["tag"].tolist()] for j in i]).value_counts()[:20]
X = df.index.tolist()
Y = df.values.tolist()
pie = Pie("谣言关键字环图", title_pos='center')
pie.add(
"",
X,
Y,
radius=[40, 75],
label_text_color=None,
is_label_show=True,
is_more_utils=True,
legend_orient="vertical",
legend_pos="left",
)
pie.render(path="谣言环图.html")
词云:
import pandas as pd
from pyecharts import WordCloud
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("confirm.csv")
x = data["province"]
y = data["confirm"]
wordcloud = WordCloud(width=900, height=420)
wordcloud.add("", x, y, word_size_range=[20, 100])
wordcloud.render("疫情词云图.html")
wordcloud.render_notebook()

import numpy as np
import pandas as pd
from pyecharts import WordCloud
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("冠状病毒谣言数据.csv")
df = pd.Series([j for i in [eval(i) for i in data["tag"].tolist()] for j in i]).value_counts()[:20]
X = df.index.tolist()
Y = df.values.tolist()
wordcloud = WordCloud(width=1300, height=620)
wordcloud.add("", X, Y, word_size_range=[20, 100])
wordcloud.render("谣言词云图.html")
wordcloud.render_notebook()

最后 附带一个批量运行程序的小脚本
import os
from glob import glob
# os.system('谣言饼图.py')
ls = glob('*.py')
# print(len(ls))
for i in ls:
if i == '运行.py':
continue
print(i)
os.system(i)
一起学习python,小白指导,教学分享记得私信我