之前写的关于ITIL 4的实践(Practice)服务目录,可用性,连续性, 在日常的运维或者服务管理中,也许很多公司都没有用到。春节前的工作告一段落,今天终于有时间写写我们最常用的实践:事件管理(Incident Mangement)
事件管理是每个实行ITIL的公司必用的流程,是最常见的流程。可是,我发现有些公司还是不清楚事件的定义,事件流程得管理范围,重大事件的管理,还有事件、问题和变更的界面与关系。在这篇博文里,希望你能找到答案。
首先解读事件的定义。
事件的定义
事件(Incident):服务的意外中断或服务质量的降低。与ITIL V3相比,ITIL 4给出的定义更清晰。ITIL 3中把事件定义为“任何可被发现或辨别的事情,此类事情对于基础设施的管理或IT服务的交付有重要意义,以及有助于评估可能导致服务出现的偏差。”
事件管理的目的是“确保将计划外服务不可用或降级的时间减至最少,从而减少对用户的负面影响。”也就是说,让服务快速恢复。实现这一点的主要因素有两个:早期事件检测和快速恢复服务正常运行。ITIL 4强调了早期事件检测,也就是更主动的进行异常管理,并在故障还未造成业务影响时尽快处理。
事件模型(Incident Model):一种可重复的方法来管理特定类型的事件。
ITIL 4在快速恢复服务的正常运行方面,提出了“事件模型”的概念,意思是对于某些特定类型的事件,如经常发生的,可以定义事件模型,包括解决方案,团队,人员。那么事件模型的解决方案可以使用知识管理实践。
重大事件(Major Incident):具有重大业务影响的事件,需要立即协调解决。
重大事件的管理流程往往在大型企业中,独立于一般事件管理流程,因为事件影响巨大,需要上报领导,也有可能上报监管部门。这类事件发生时,组织需要协调资源马上解决,同时事后需要写报告,开回顾会等等,比一般的事件做的工作多。建议针对重大事件,制定独立的流程去管理。但是这里的难点在于如何区分重大事件和普通事件?
变通方案(Workaround):减少或消除尚未完全解决的事件或问题的影响的解决方案。
技术债:通过选择变通方案而不是需要长时间的系统解决方案而累积的总返工积压。
往往变通方案的聚焦带来了技术债务,可以通过“问题流程”来制定彻底的解决方案,消除技术债务。
事件管理的范围
事件管理的范围包括:
- 检测和记录事件
- 诊断和调查事故
- 将受影响的服务和CI恢复到商定的质量
- 管理事件记录
- 在整个事件生命周期内与相关利益相关者沟通
- 审查事件,并在解决后开始改进服务和事件管理实践
当我们提及范围的时候需要将将事件管理和其他管理实践的界面。
1. 事件和变更
变更的管理范围是”对服务产生直接或间接影响的任何东西的添加、修改或删除“,也就是说当对服务或产品进行增、删、改时,我们应该使用变更管理。变更管理解决的是两个问题:第一, 是否应该做,这是变更之前的评估和分析,第二,是否做的正确,这是变更实施时的管控。如果变更完成后,发生问题,应该开事件工单,快速修复,同时关联事件和变更的工单。
有人会说,这样管理很麻烦,工单开来开去。但是这样的好处是界面清晰,不需要区分各种场景。我们通过事件和变更流程界面的清晰分割,也可以对于变更的成功率进行一定的统计。有人会问,如果应用的变更失败了,发生故障,不需要开事件工单,直接回滚变更就可以,这样应用的变更成功率一样可以统计。确实,但是我们不好统一事件里面有多少是变更造成的,甚至在事件发生时,我们不确定是否是变更造成的。
从流程制定的角度来考虑,流程尽可能不去区分应用的场景,进行场景细分的流程其设计太复杂,在实际执行过程中容易混淆,造成混乱,最后的统计报表就是不准确的。所以,
2. 事件和服务请求:
服务请求是”由用户或用户授权代表提出的发起服务行动的请求,该服务行动已被视为服务交付的正常部分“。在企业中,服务请求大部分被应用于桌面支持,如安装软件,申请办公设备。对于生成系统的服务请求多用于查询。如果发生更改,需要变更流程的支持。
3. 事件与问题:
事件管理的范围是快速恢复服务,问题管理的范围是找根因。往往故障发生后,服务恢复完毕,想知道确切的原因或者彻底的解决方案,用问题管理流程会更合适。
有的企业把事件管理和问题管理混为一谈,服务恢复后,业务部门不希望IT部分关闭事件工单,找到根本原因才可以。这样做的结果是,有很多故障,服务已经恢复正常运行,但是事件工单开了很久,事件的统计报表不能真实反映生成环境服务的状况。
客户想知道故障发生的根本原因,这是合理的要求。IT可以用问题流程来找根因,建议有专门的问题经理来追踪。这一点我写问题管理实践的时候再详细描述。
4. 事件和服务台:
服务台是IT运维部门的窗口,服务台的管理更偏向与沟通,话术等。
5. 事件和“监控与事态”:
事件管理是Incident Management, ITIL 4里把监控和事态(event)写到了另一个practice里。监控和事态实践的范围是监控的范围,监控规则和阈值的设定,Event(事态)的分类分级,确定事件的联动规则。
事件实践管理的成功因素
事件管理需要关注以下两点:
1. 及早发现:
及早发现的落地实现实现需要强大的监控工具支持,流程管理上更多依赖与”监控和事态“管理。
2. 快速恢复
快速恢复的实现手段包括
1)集中会诊(Swarming):尤其是出现重大故障时,技术专家要聚集起来,集中解决故障,恢复服务。
2)事件模型(Incident Model):对于经常发生的问题,可以定义事件模型进行记录。
3)定义好事件的优先级:事件的优先级时事件流程在实施过程中的一个难点。一般从”紧急情况“和”影响范围“两个维度来定义事件的优先级,可是这两个维度大部分情况下也是感性认知,很难用明确的Criteria来定义。所以实施的过程中,客户也IT部门经常会为优先级争执。这一点需要根据企业的实际情况来讨论,制定解决办法。
事件管理的流程
ITIL 4把事件管理的流程分为”事件处理流程“和”事件定期回顾流程“,强调了事件的事后回顾。
1. 事件处理流程图见下:
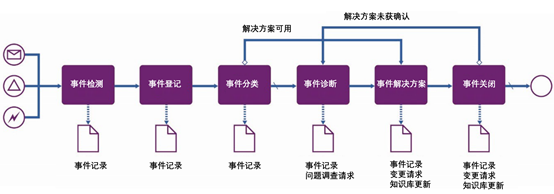
主要活动为:
事件检测:分为用户汇报或者工具自动检测
事件登记:服务台代理执行事件注册,或者技术工具自动注册事件
事件分类:进行类别分类并分派工单,也分为手动和自动
事件诊断:如果分类不能提供对解决方案的理解,技术专家团队将执行事件诊断。这可能涉及团队之间事件的升级,或联合技术,例如集中诊断。如果分类错误是因为CI分配不正确,要将此信息传达给负责配置控制的人员。这里注意:事件可以关联CI项。
事件解决:如果解决方案不正确,需要再次回到事件诊断。
事件关闭:事件成功解决后,可能需要一些正式的关闭程序:
●用户确认服务恢复
●处置成本计算和报告
●解决价格计算和开票
●问题调查启动
●事件回顾。
2. 事件定期回顾:
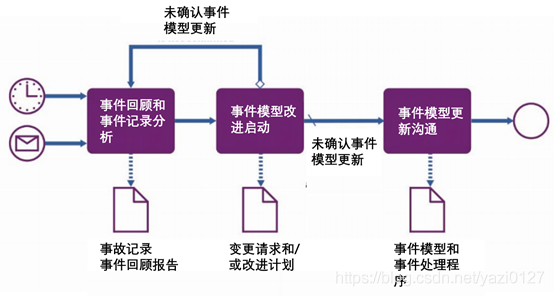
事件的指标
ITIL 4列了一些指标示例,比较常用的是黑体标出的部分:
关键成功因素 |
重要指标 |
及早发现事故 |
事件发生与检测之间的时间 通过监控和事件管理检测到的事件百分比 |
快速有效地解决事件 |
事件检测和诊断验收之间的时间 诊断时间 重新分配次数 等待时间占总事件处理时间的百分比 首次解决率 满足商定的解决时间 用户对事件处理和解决的满意度 自动解决的事件百分比(如果实行了“故障自愈”的自动化处理手段) 在用户报告之前已解决的事件的百分比 |
持续改进事件管理方法 |
使用先前确定和记录的解决方案解决事故的百分比 使用事件模型解决的事件百分比随着时间的推移关键实践指标的改进 事件解决的速度和有效性指标之间的平衡 |
角色和文化
ITIL 4 在事件管理流程中强调了角色和文化。
事件经理(Incident Manager):
Incident Manager最好由专人负责,主要工作包括:
- 根据组织设计,协调组织内或特定区域内的事件处理,如区域、产品和技术
- 协调人工作业与事故,尤其是涉及多个团队的事故
- 监督和审查处理和解决事故的团队的工作
- 确保在整个组织内充分了解事件及其状态
- 定期进行事件审查,并开始改进事件管理实践、事件模型和事件处理程序
- 发展组织在事故管理实践过程和方法方面的专业知识
事件经理在某些组织下会担任重大事件协调员的角色,这也是合理的,也可以和兼任问题经理的角色。
文化:
ITIL 4强调了集体责任和无指责文化,这点借鉴了devops。为了解决”解决方案缓慢或根本没有,士气下降,缺乏动力,以及进入工作场所的竞争力不健康。此外,团队成员之间的信任也会瓦解。“的问题,ITIL 4主张用DevOps和集中诊断(Swarming)等方法,显示鼓励积极文化所需的一些特征。
最后不要忘记”持续学习“,无论是mindset还是technical skills.
总结,事件管理实践主要就讲解这些。建议大家从网上下载我翻译的”ITIL 4 事件管理最佳实践“,去了解更详细的内容。下载链接见下:
https://download.csdn.net/download/yazi0127/15049262
最后,喜欢就点个赞吧。如果想持续了解ITIL 4和IT咨询的方法论和知识体系,关注我的博客!的可能性。少或消除尚未完全解决的事件或问题的影响的解决方案。一些变通方案降低了发生事故的可能
时性。
一种可重复的方法来管理特定类型的事故。
IT服务的意外中一种可重复的方法来管理特定类型的事故。
事件模型 (Incident Model)
服务的意外中断或服务质量的降低
断质量的降低务的断或服务质量的降低务的意外服务服务的意外中断或服务质量的降低的意外中
事件模型 (Incident Model)
服务的意外中断或服务质量的降低
断或服务质量的降低中断或服务的意外中断或服务质量的降低服务质量的降低