泰坦尼克数据分析与预处理

数据预览
import pandas
import numpy as np
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
#from __future__ import division
from scipy import stats
import seaborn as sns
###首先导入各种模块
###让图片在ipython notebook上直接显示
#matplotlib inline
df=pandas.read_csv("train.csv")
print(df.describe()) #数据描述
PassengerId Survived Pclass Age SibSp \
count 892.000000 892.000000 892.000000 715.000000 892.000000
mean 445.547085 0.383408 2.308296 30.249189 0.523543
std 257.564835 0.486489 0.835666 20.038824 1.102240
min 1.000000 0.000000 1.000000 0.420000 0.000000
25% 222.750000 0.000000 2.000000 20.750000 0.000000
50% 445.500000 0.000000 3.000000 28.000000 0.000000
75% 668.250000 1.000000 3.000000 38.000000 1.000000
max 891.000000 1.000000 3.000000 400.000000 8.000000
Parch Fare
count 892.000000 892.000000
mean 0.381166 195.705100
std 0.805706 4887.636304
min 0.000000 0.000000
25% 0.000000 7.917700
50% 0.000000 14.454200
75% 0.000000 31.000000
max 6.000000 146000.520800
#查看数据类型
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 892 entries, 0 to 891
Data columns (total 13 columns):
PassengerId 892 non-null int64
Survived 892 non-null int64
Pclass 892 non-null int64
Name 892 non-null object
Sex 892 non-null object
Age 715 non-null float64
SibSp 892 non-null int64
Parch 892 non-null int64
Ticket 892 non-null object
Fare 892 non-null float64
Ethnicity 892 non-null object
Cabin 204 non-null object
Embarked 890 non-null object
dtypes: float64(2), int64(5), object(6)
memory usage: 90.7+ KB
数据与处理
可以看出Age(年龄有缺失值)尝试填充(填充策略为平均值填充);同时Embarked有非常少的两个缺失值,这里用’S’填充,S为众数
#Embarked有非常少的两个缺失值,这里用'S'填充
df['Embarked']=df['Embarked'].fillna('S')
#处理Age的缺失值,Age是连续数据,这里用平均值填充缺失值
age_mean=df['Age'].mean()
df['Age']=df['Age'].fillna(age_mean)
将性别数据数值化
#这里把性别数据值字符串不便于计算换成数值,
#用1代表男性,用0代表女性,将性别数值化
def sex_value(Sex):
if Sex=='male':
return 1
else:
return 0
df['Sex']=df['Sex'].apply(lambda x:sex_value(x))
数据的描述性分析
#获取生还乘客的数据
survives_passenger_df=df[df['Survived']==1]
#定义几个常用的方法
#按照xx对乘客进行分组,计算每组的人数
def xx_group_all(df,xx):
#按照xx对乘客进行分组后 ,每个组的人数
return df.groupby(xx)['PassengerId'].count()
#计算每个组的生还率
def group_passenger_survived_rate(xx):
#按xx对乘客进行分组后每个组的人数
group_all=xx_group_all(df,xx)
#按xx对乘客进行分组后每个组生还者的人数
group_survived_value=xx_group_all(survives_passenger_df,xx)
#按xx对乘客进行分组后,每组生还者的概率
return group_survived_value/group_all
#输出饼图
def print_pie(group_data,title):
group_data.plt.pie(title=title,figsize=(6,6),autopct='%.2f%%'\
,startangle=90,legend=True)
#输出柱状图
def print_bar(data,title):
bar=data.plot.bar(title=title)
for p in bar.patches:
bar.annotate('%.2f%%'%(p.get_height()*100),(p.get_x()*1.005\
,p.get_height()*1.005))
探索性别对生还率的影响
#不同性别对生还率的影响
df_sex1=df['Sex'][df['Survived']==1]
df_sex0=df['Sex'][df['Survived']==0]
plt.hist([df_sex1,df_sex0],
stacked=True,
label=['Rescued','not saved'])
plt.xticks([-1,0,1,2],[-1,'F','M',2])
plt.legend()
plt.title('Sex_Survived')
Text(0.5, 1.0, 'Sex_Survived')

看出全体乘客中男性占了大部分,但是生还乘客中女性占了大部分;
- 不难得出结论:女性的生还概率比男性的更高
乘客等级与生还率的关系
#不同等级对生还率的影响
df_sex1=df['Pclass'][df['Survived']==1]
df_sex0=df['Pclass'][df['Survived']==0]
plt.hist([df_sex1,df_sex0],
stacked=True,
label=['Rescued','not saved'])
plt.xticks([1,2,3],['Upper','Middle','lower'])
plt.legend()
plt.title('Pclass_Survived')
Text(0.5, 1.0, 'Pclass_Survived')

全体乘客中lower等级的乘客超过了一半,生还乘客中upper等级的人最多,
对比各个等级的死亡人数和生还人数:
- 结论:Upper等级生还概率大于Middle、lower的生存概率,等级越好生还概率越好
#不同年龄段对生还率的影响elderly,child,youth
#年龄数据进行处理,0-18为child(少年),18-40为youth(青年),40-80为elderly(老年)
def age_duan(age):
if age<=18:
return 1
elif age<=40:
return 2
else:
return 3
df['Age']=df['Age'].apply(lambda x:age_duan(x))
df_sex1=df['Age'][df['Survived']==1]
df_sex0=df['Age'][df['Survived']==0]
plt.hist([df_sex1,df_sex0],
stacked=True,
label=['Rescued','not saved'])
plt.xticks([1,2,3],['child','youth','elderly'])
plt.legend()
plt.title('Age_Survived')
Text(0.5, 1.0, 'Age_Survived')

全部乘客中大部分人否在30岁左右,而0-10的生还率比其他年龄段都要高
- 结论:0-10岁的生还率率最高,20-40之间的生还人数最多
多因素分析
#性别和乘客等级共同对生还率的影响
print_bar(group_passenger_survived_rate(['Sex','Pclass']),'Sex_Pclass_Survived')
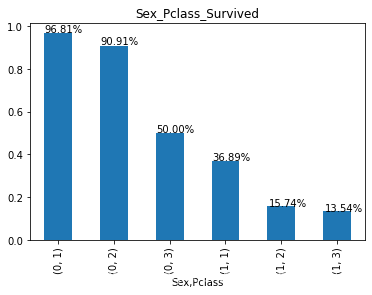
不难看出,生还率的影响主要有性别和乘客等级,其中乘客等级影响因素大小依次为1>2>3
逻辑回归尝试
#暂无