什么是深度神经网络
神经网络的个数是隐藏层+输出层,输入层不计入。
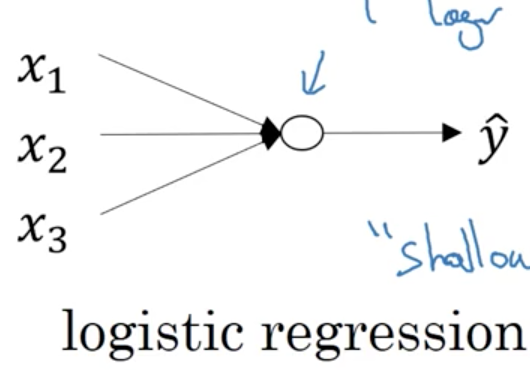
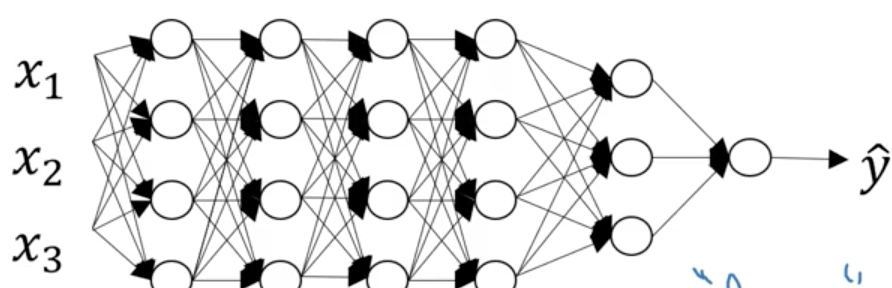
符号表示:

L代表神经网络的个数,上面按个就有6层神经网络,所以L=6。
n^[l]代表在第l层神经网络中,有多少神经元个数。注意,输入层是n[0]=nx
a[l]代表在第l层神经网络中,所使用的激活函数。
w[l]代表在第l层神经网络中,计算中间函数z时所使用的权重。b是偏置。
在深度神经网络中的前向传播(forward propagation)
对于每一层单一的前向传播,有一个通用公式:
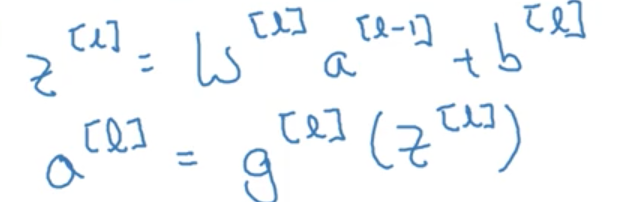
那么,对于每一层那么多个神经元的前线传播,有没有一个向量化的表达方式呢?

这是课时的例子,为了很好地理解矩阵变换,我写的更加透彻一些。
假如第一层n[1] = 4, 那么,就有四个神经元,每个神经元的W不同,b不同,传入a[0]后,第一个神经元的结果是z[1][1],第二个是z[1][2],第三个是z[1][3],第四个是z[1][4],那么,将他们水平排列,得到一个大写的Z,大写Z的维度是(1,n0)(n0是前一层神经元的个数,因为你要给每一个都配参数w,所以w.dot(x)中,w是(1,nx),b是(1,n0);那么,A[1]也就是相同的维度,每个神经元是列向量,将每个神经元横向排列;数据以(1,n1)的维度传入L[2];
在深度学习中得到正确的维度

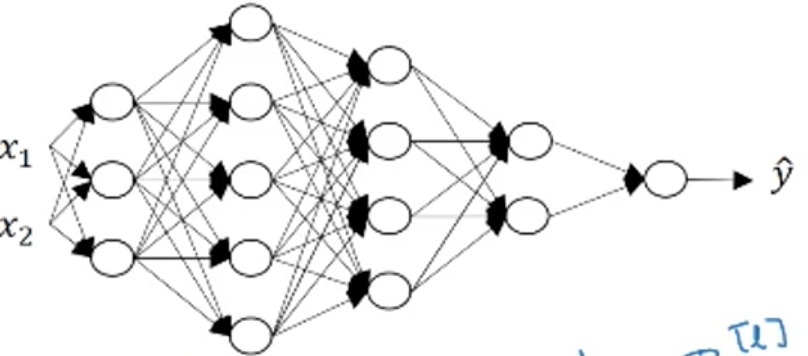
x1,x2是矩阵的特征数,是2;那么,每层的神经元就是特征,比如,第一层有三个神经元,就是三个特征;当有m个样本时,也就是X = [[x11,x21],[x12,x22]],这里的特征是纵向的,因为每个样本是列向量,那么样本之间就是横向堆叠;好了,那么,假设有三个样本,那么,X = (2,3) 2是特征数,x1,x2,3是样本数,每个样本都有x1,x2;
好了,样本传到了第二层,X = (2,3),由WX可知道,W的列一定是=2的,所以w=(n[l], n[l-1]);点乘之后,wx = (n[l], 3);b由于广播效应,(n[l],1) 会应用在z的每一列,变成(n[l],3);那么,Z就是(n[l],3)了。所以,z,a都会由于样本个数的变化而变化。
Why deep representations?
为什么需要deep learning?也就是deep learning存在性的问题。为什么不做一个单层的训练模型就可以了?有几个例子:
- 图像识别
图像识别的思路很有意思。layer 1是检测出图片的边缘,然后layer 2将这些边缘组合起来,组成人脸的局部的特征;layer 3把他们都组合起来,变成一张张人脸。那么,如果里面多加一层,比如加在layer 2之后,是将局部特征组合成一半的脸的特征,这样复杂度会减少,并且准确率也会变高。 - 语音识别
浅层的神经元能够检测一些简单的音调,然后较深的神经元能够检测出基本的音素,更深的神经元就能够检测出单词信息。神经网络从左到右,神经元提取的特征从简单到复杂。特征复杂度与神经网络层数成正相关。特征越来越复杂,功能也越来越强大。 - 减少神经元个数,减少计算量
对于n个样本,如果你仅仅用一层,也就是输出层来训练,那么,神经元个数是指数型增长 n^[L] = 2^(n-1)。
使用电路理论,对于这个逻辑运算,如果使用深度网络,深度网络的结构是每层将前一层的两两单元进行异或,最后到一个输出。这样,整个深度网络的层数是log2(n),不包含输入层。总共使用的神经元个数为n-1个。 - 不好懂,原理其实就是神经网络的个数和处理样本的逻辑有关系,也和减少神经元个数有关系。
Building blocks of deep neural networks
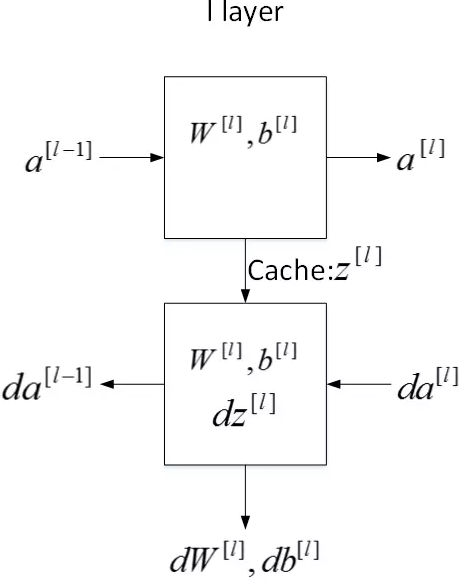
每一层的正向传播和反向传播。
Forward and Backward Propagation
首先回顾下正向传播的流程:
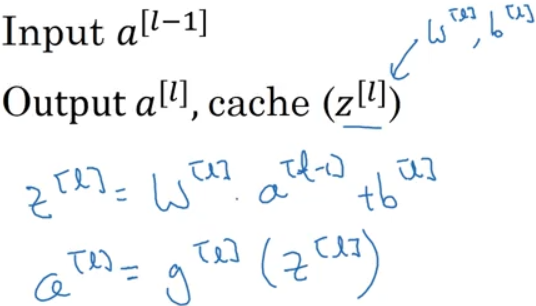
对于L层,输入是L-1层激活函数的输出值a[L-1];输出是L层的激活函数的输出值a[L];并且将该层Z[L],W[L],b[L]的值存入变量中。在该层中,Z[L] = W[L].dot(a[L]) +b[L],每一个a[L-1]层中的神经元都给了不同的权重并输出;然后输出结果再用L层的激活函数计算。
向量化表示
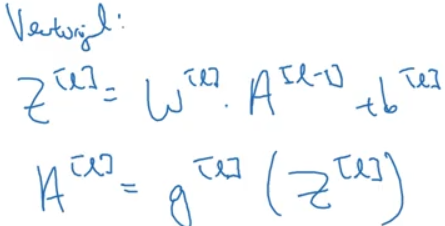
对这里不熟悉,就要不厌其烦的重新梳理,反馈。那么,
- 假设输入的A[0]是nx个特征值,8个样本,A向量的维度是(nx,8);
- 输入第一层,W.dot(A[0])需要成立,W的维度是(n[L],nx(n[L-1])), WA的维度是(n[L],8);Z的维度是(n[L],8),这个Z代表有8个样本,每个样本都是n[L]维度的列向量。
借用一下别人总结的,我觉得非常好。

Parameters vs Hyperparameters
参数和超参数
