文章目录
1、模块
(1)简介:
模块Moduel,一个.py文件就是一个模块,模块的组成如下
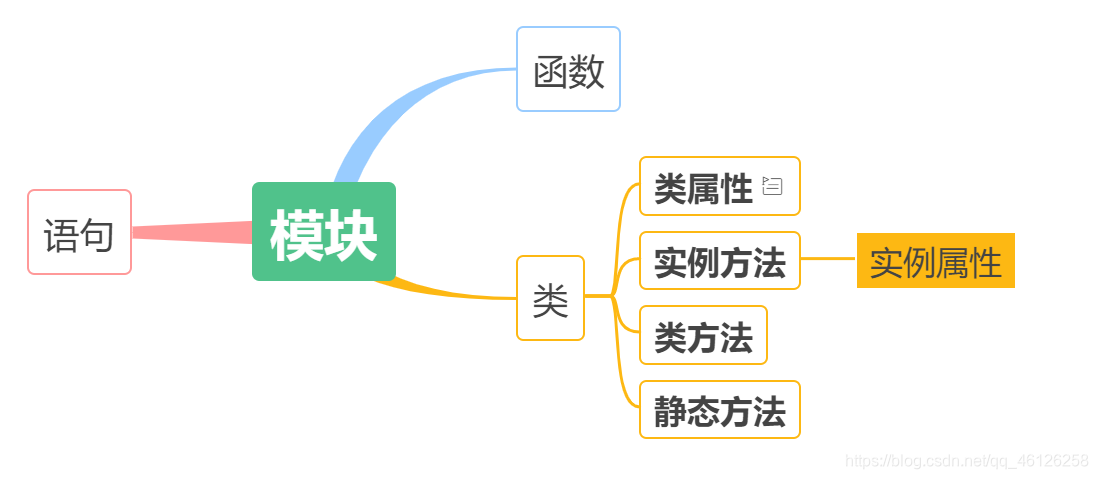
(2)使用模块的好处:
- 方便其他程序、脚本的导入并使用
- 避免函数名和变量名冲突(一个模块内变量名不能重复)
- 提高代码可维护性、可重用性
- 分为多模块开发,有利于团队协作
(3)使用自带的模块:
- import 模块 as 别名
- from 模块 import 函数/变量/类
以math模块为例(这个没有起别名):
import math
print(id(math)) # 1657999653280
print(type(math)) # <class 'module'> 表明math的类型是一个模块
print(math) # <module 'math' (built-in)> 表明math是内置的模块
print(math.pi) # 3.141592653589793 π的值
print('----------------')
print(dir(math)) # 查看math模块的属性和方法
'''
['__doc__', '__loader__', '__name__', '__package__', '__spec__',
'acos', 'acosh', 'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil',
'comb', 'copysign', 'cos', 'cosh', 'degrees', 'dist', 'e', 'erf',
'erfc', 'exp', 'expm1', 'fabs', 'factorial', 'floor', 'fmod', 'frexp',
'fsum', 'gamma', 'gcd', 'hypot', 'inf', 'isclose', 'isfinite', 'isinf',
'isnan', 'isqrt', 'ldexp', 'lgamma', 'log', 'log10', 'log1p', 'log2',
'modf', 'nan', 'perm', 'pi', 'pow', 'prod', 'radians', 'remainder',
'sin', 'sinh', 'sqrt', 'tan', 'tanh', 'tau', 'trunc']
'''
下面这两种方法都能达到相同的目的:
from math import pi
print(pi) # 3.141592653589793
import math
print(math.pi) # π的值3.141592653589793
(4)自定义模块(新建一个文件):
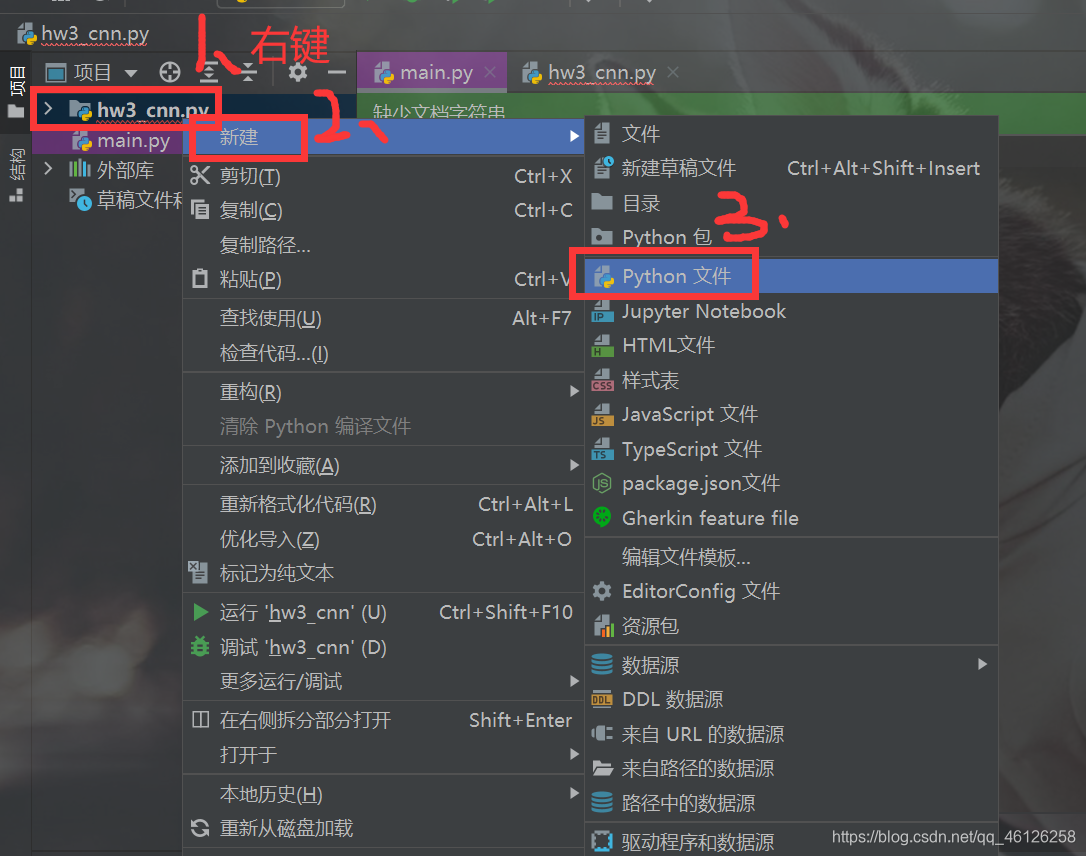
新建一个Python文件命名为calculate,这个模块有实现相加,相乘的函数,如下:
def Add(a, b):
return a + b
def Dev(a, b):
return a / b
然后在当前文件hw3_cnn中对刚写好的模块进行调用,如下:
import calculate as cal
a = 10
b = 20
print(cal.Add(a, b))
print(cal.Dev(a, b))
'''
30
0.5
'''
如果不能运行,按照进行操作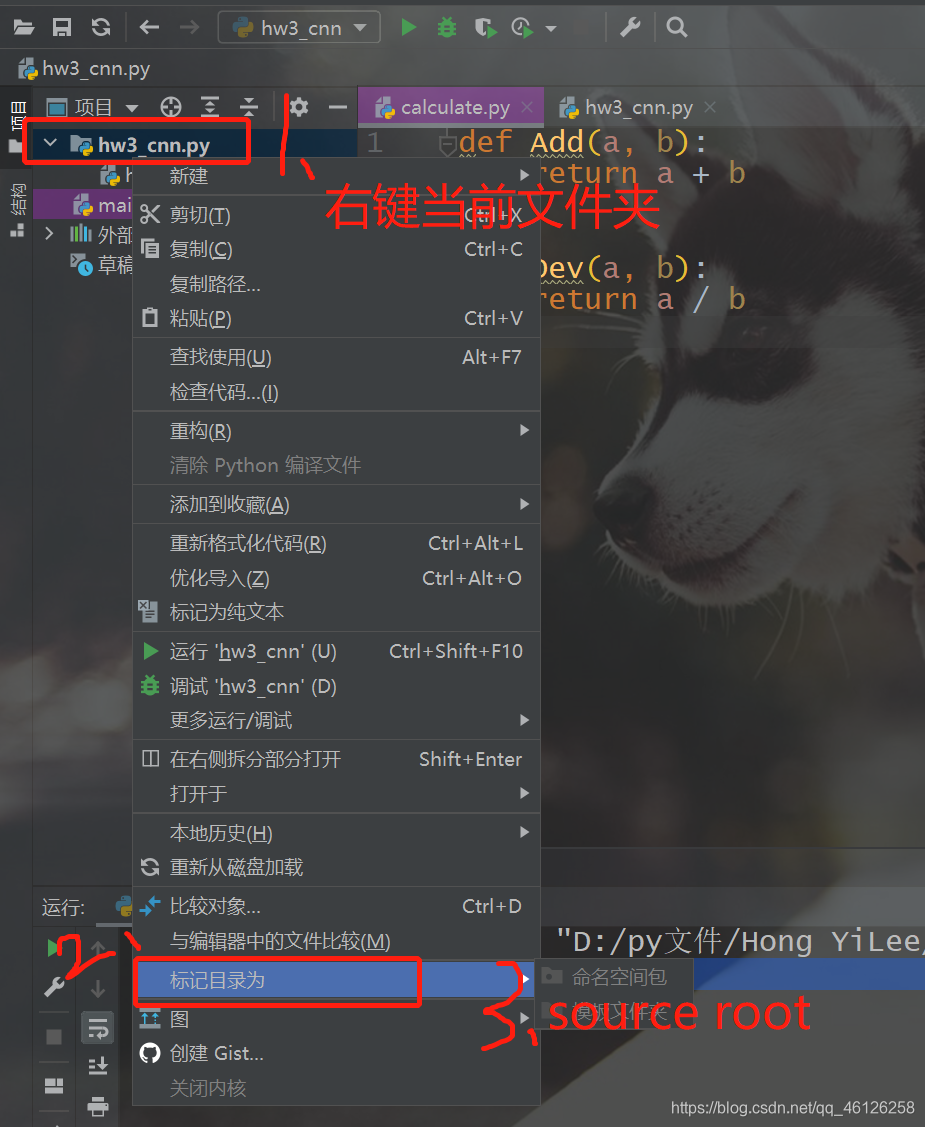
(5)以主程序的形式运行程序
- 在每个模块的定义中都包括一个记录模块名称的变量
_name_,程序可以检查该变量,以确定他们在哪个模块中执行。如果一个模块不是被导入到其它程序中执行,那么它可能在解释器的顶级模块中执行。顶级模块的__name_变量的值为_main
(以下面的为例)
当calculate模块中多加一句话:print(Add(10, 20))时
def Add(a, b):
return a + b
def Dev(a, b):
return a / b
print(Add(10, 20))
在新建的文件demo1运行下面的语句会输出calculate模块中的print值,那么该怎么解决这个问题?
import calculate
print(calculate.Add(100, 200))
'''
30
300
'''
在calculate模块,改写一句if __name__ == '__main__':,就可以了,这样再运行demo1时calculate模块中的print就不会输出了,
def Add(a, b):
return a + b
def Dev(a, b):
return a / b
if __name__ == '__main__': # 只有运行calculate文件时才会被输出
print(Add(10, 20))
记录模块名称的变量_name_,用于确定是否在当前文件下运行,或者在每个调用该模块的文件下都运行。
2、包
Python程序是有多个包构成的,每个由包含不同的模块,每个模块中有不同的函数、类等(包>模块>函数)
(1)简介
- 包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
- 好处:代码规范,避免模块名冲突
(2)新建一个包、目录:
在当前文件夹内右键方法如下,新建一个目录同理选择目录即可。
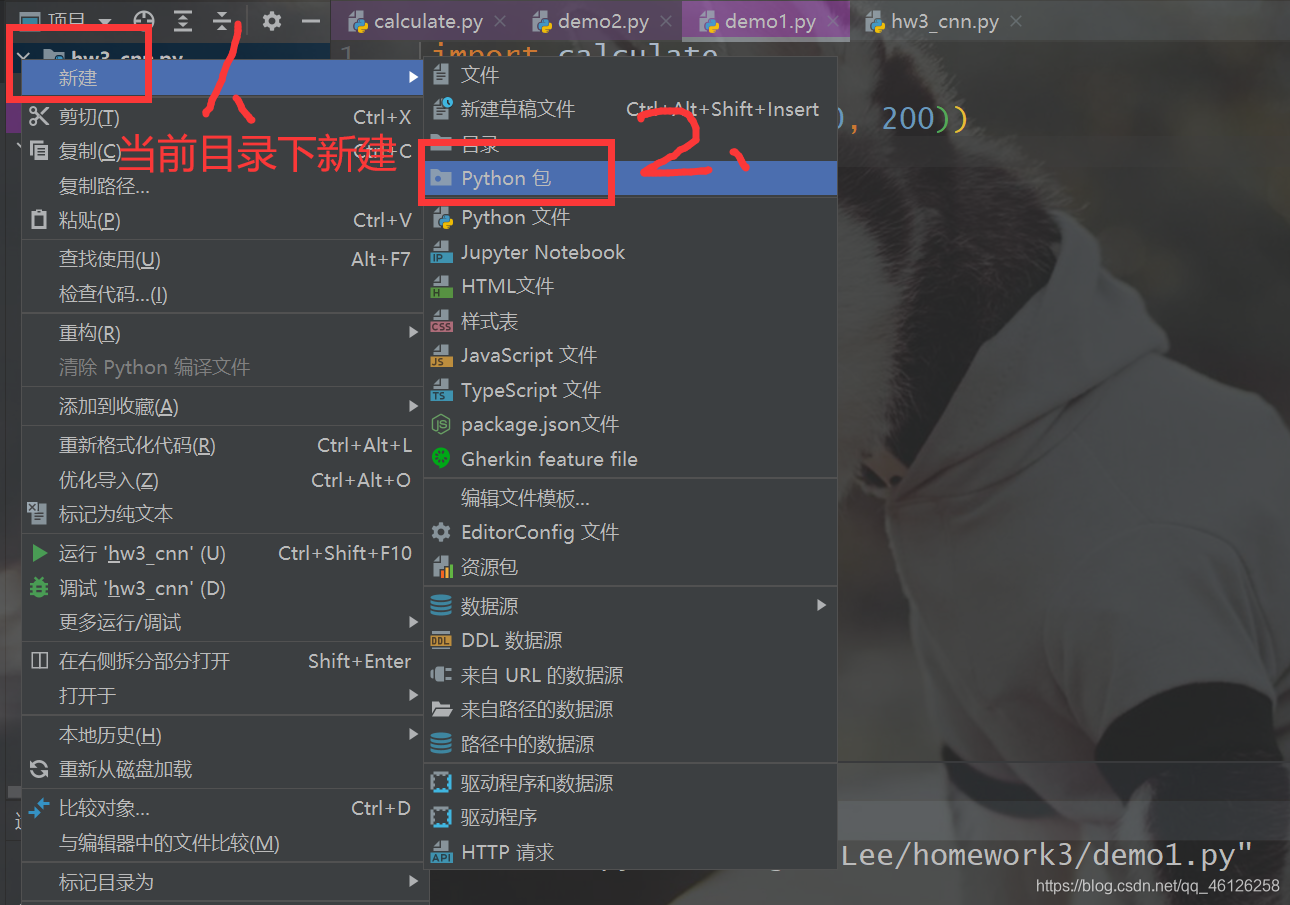
包与目录的区别:
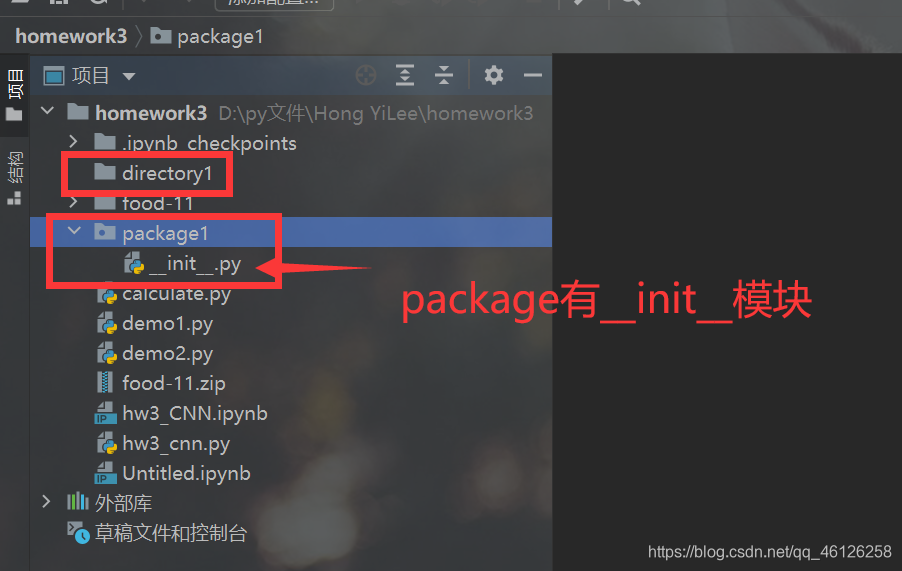
使用方法:
在package1中新建两个模块Moduel_A、Moduel_B。在Moduel_A中写入a = 11,在Moduel_B中写入b = 22,那么在demo1中可以调用package1模块中的变量并进行输出。
# import 包名.模块名
import package1.Moduel_A as A
import package1.Moduel_B as B
print(A.a + B.b)
'''
33
'''
3、常用的内置模块

(1)sys:与Python解释器及其环境操作相关的标准库
使用Ctrl+B可以找到该模块的文件,里面的注释写的很详细。
import sys
print(sys.getsizeof(22)) # 28 获取22的字节数
print(sys.getsizeof(48)) # 28
print(sys.getsizeof(True)) # 28
print(sys.getsizeof(False)) # 24
(2)time:提供与时间相关的各种函数的标准库
import time
# 返回当前时间的秒数
print(time.time())
# 输出参数对应的时间
print(time.localtime(time.time()))
# print(time.localtime()) 不加参数会输出当前时间
'''
1612612359.5800502
time.struct_time(tm_year=2021, tm_mon=2, tm_mday=6, tm_hour=19, tm_min=52, tm_sec=39, tm_wday=5, tm_yday=37, tm_isdst=0)
'''
和schedule模块结合可以实现定点print
import schedule
import time
def job():
print('Hi....')
schedule.every(3).seconds.do(job) # 每隔3s执行job函数
while True:
schedule.run_pending() # 启动
time.sleep(1) # 休眠 1s
(3)urllib:用于读取来自网上(服务器)的数据标准库
通常用于爬虫。urllib是一个包选中后使用Ctrl+B会跳转到__init__.py文件,包中会含有一些模块
import urllib.request
# 对网址中返回的信息读取
print(urllib.request.urlopen('https://www.baidu.com').read())
'''
b'<html>\r\n<head>\r\n\t<script>\r\n\t\tlocation.replace(location.href.replace("https://","http://"));\r\n\t</script>\r\n</head>\r\n<body>\r\n\t<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>\r\n</body>\r\n</html>'
'''
其他的还没有接触过,就先了解这些内置模块的功能吧