我们生产常有将实时数据流与 Hive 维表 join 来丰富数据的需求,其中 Hive 表是分区表,业务上需要关联上 Hive 最新分区的数据。上周 Flink 1.12 发布了,刚好支撑了这种业务场景,我也将 1.12 版本部署后做了一个线上需求并上线。对比之前生产环境中实现方案,最新分区直接作为时态表提升了很多开发效率,在这里做一些小的分享。
- Flink 1.12 前关联 Hive 最新分区方案
- Flink 1.12 关联 Hive 最新分区表
- 关联Hive最新分区 Demo
- Flink SQL 开发小技巧
Flink 1.12 前关联 Hive 最新分区方案
在分区时态表出来之前,为了定期关联出最新的分区数据,通常要写 DataStream 程序,在 map 算子中实现关联 Hive 最新分区表的逻辑,得到关联打宽后的 DataStream 对象,通过将该 DataStream 对象转换成 Table 对象后,再进行后续的 SQL 业务逻辑加工。
StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env, streamSettings);
DataStream<Tuple2<MasterBean, HiveDayIndexBean>> indexBeanStream = masterDataStream.map(new IndexOrderJoin()); map 算子中的主要逻辑: 将 T+2 的维度数据与实时数据关联,返回 Tuple2<MasterBean, HiveDimBean> 数据,因为离线数仓出数一般在凌晨 3 点,有时候由于集群资源不稳定导致数据产出慢,业务对实时性要求也不高,所以这里用的是 T+2 的数据。
public class IndexOrderJoin extends RichMapFunction<MasterBean, Tuple2<MasterBean, HiveDimBean>> {
private Map<Integer, Map<String, HiveDimBean>> map = null;
Logger logger;
@Override
public void open(Configuration parameters) throws Exception {
logger = LoggerFactory.getLogger(Class.forName("com.hll.util.IndexOrderJoin"));
map = new HashMap<>();
}
public Tuple2<MasterBean, HiveDayIndexBean> map(MasterBean masterBean) {
if (map.get(masterBean.getReportDate() - 2) == null) {
//如果map里没有T+2的维表数据则查询一次Hive,并将结果存入线程级别map,所以保证Task维表数据是全的
logger.info("initial hive data : {}", masterBean.getReportDate());
map.put(masterBean.getReportDate() - 2, getHiveDayIndex(masterBean.getReportDate() - 2));
}
//将的kafka数据与hive join后返回打宽数据
return new Tuple2<>(masterBean, map.get(masterBean.getReportDate() - 2).get(masterBean.getGroupID()));
}基于关联打宽后的 DataStream 创建视图,然后再做后续的 SQL 业务逻辑查询。
tblEnv.createTemporaryView("index_order_master", indexBeanStream); tblEnv.sqlUpdate("select group_id, group_name, sum(amt) from index_order_master group by group_id, group_name");
tblEnv.execute("rt_aggr_master_flink");可以看出,在没有支持 Hive 最新分区做时态表的时候,简单的一个 join 便涉及到DataStream、map 算子,程序的代码量和维护成本会是比较大的。
Flink 1.12 关联 Hive 最新分区表
Flink 1.12 支持了 Hive 最新的分区作为时态表的功能,可以通过 SQL 的方式直接关联 Hive 分区表的最新分区,并且会自动监听最新的 Hive 分区,当监控到新的分区后,会自动地做维表数据的全量替换。通过这种方式,用户无需编写 DataStream 程序即可完成 Kafka 流实时关联最新的 Hive 分区实现数据打宽。
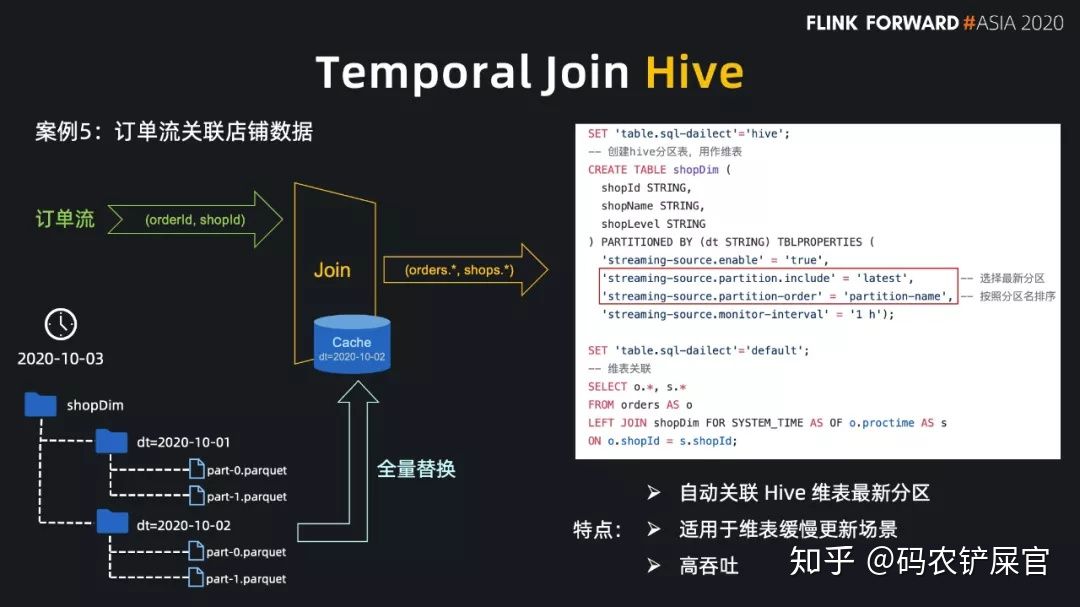
- 参数解释
■ streaming-source.enable 开启流式读取 Hive 数据。
■ streaming-source.partition.include
1.latest 属性: 只读取最新分区数据。2.all: 读取全量分区数据 ,默认值为 all,表示读所有分区,latest 只能用在 temporal join 中,用于读取最新分区作为维表,不能直接读取最新分区数据。
■ streaming-source.monitor-interval 监听新分区生成的时间、不宜过短 、最短是1 个小时,因为目前的实现是每个 task 都会查询 metastore,高频的查可能会对metastore 产生过大的压力。需要注意的是,1.12.1 放开了这个限制,但仍建议按照实际业务不要配个太短的 interval。
■ streaming-source.partition-order分区策略
主要有以下 3 种,其中最为推荐的是 partition-name:
1.partition-name 使用默认分区名称顺序加载最新分区2.create-time 使用分区文件创建时间顺序3.partition-time 使用分区时间顺序
- 具体配置
使用 Hive 最新分区作为 Tempmoral table 之前,需要设置必要的两个参数:
■ streaming-source.partition-order分区策略
主要有以下 3 种,其中最为推荐的是 partition-name:
1.partition-name 使用默认分区名称顺序加载最新分区2.create-time 使用分区文件创建时间顺序3.partition-time 使用分区时间顺序
- 具体配置
使用 Hive 最新分区作为 Tempmoral table 之前,需要设置必要的两个参数:
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest'我们可以再创建一张基于 Hive 表的新表,在 DDL 的 properties 里指定这两个参数,也可以使用 SQL Hint 功能,在使用时通过 SQL Hint 指定 query 中表的参数。以使用 SQL Hint 为例,我们需要用 /* option */ 指定表的属性参数,例如:
SELECT * FROM hive_table /*+ OPTIONS('streaming-source.enable'='true',
'streaming-source.partition.include' = 'latest') */; 我们需要显示地开启 SQL Hint 功能, 在 SQL Client 中可以用 set 命令设置:
set table.dynamic-table-options.enabled= true;在程序代码中,可以通过 TableConfig 配置:
tblEnv.getConfig().getConfiguration().setString("table.dynamic-table-options.enabled",
"true"); Flink 官网也给出了一个详细的例子,这里也简单说明下。
--将方言设置为hive以使用hive语法
SET table.sql-dialect=hive;
CREATE TABLE dimension_table (
product_id STRING,
product_name STRING,
unit_price DECIMAL(10, 4),
pv_count BIGINT,
like_count BIGINT,
comment_count BIGINT,
update_time TIMESTAMP(3),
update_user STRING,
...
) PARTITIONED BY (pt_year STRING, pt_month STRING, pt_day STRING) TBLPROPERTIES (
-- 在创建hive时态表时指定属性
'streaming-source.enable' = 'true',
'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '12 h',
'streaming-source.partition-order' = 'partition-name', -- 监听partition-name最新分区数据
);
--将方言设置为default以使用flink语法
SET table.sql-dialect=default;
CREATE TABLE orders_table (
order_id STRING,
order_amount DOUBLE,
product_id STRING,
log_ts TIMESTAMP(3),
proctime as PROCTIME()
) WITH (...);
--将流表与hive最新分区数据关联
SELECT * FROM orders_table AS order
JOIN dimension_table FOR SYSTEM_TIME AS OF o.proctime AS dim
ON order.product_id = dim.product_id;
关联 Hive 最新分区 Demo
- 工程依赖
将 Demo 工程中使用到的 connector 和 format 依赖贴到这里,方便大家本地测试时参考。
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-sql-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.0</version>
</dependency>
</dependencies> 在 Sql Client 中注册 HiveCatalog:
vim conf/sql-client-defaults.yaml
catalogs:
- name: hive_catalog
type: hive
hive-conf-dir: /disk0/soft/hive-conf/ #该目录需要包hive-site.xml文件 创建 Kafka 表
CREATE TABLE hive_catalog.flink_db.kfk_fact_bill_master_12 (
master Row<reportDate String, groupID int, shopID int, shopName String, action int, orderStatus int, orderKey String, actionTime bigint, areaName String, paidAmount double, foodAmount double, startTime String, person double, orderSubType int, checkoutTime String>,
proctime as PROCTIME() -- PROCTIME用来和Hive时态表关联
) WITH (
'connector' = 'kafka',
'topic' = 'topic_name',
'format' = 'json',
'properties.bootstrap.servers' = 'host:9092',
'properties.group.id' = 'flinkTestGroup',
'scan.startup.mode' = 'timestamp',
'scan.startup.timestamp-millis' = '1607844694000'
); - Flink 事实表与 Hive 最新分区数据关联
dim_extend_shop_info 是 Hive 中已存在的表,所以我们下面用 table hint 动态地开启维表参数。
CREATE VIEW IF NOT EXISTS hive_catalog.flink_db.view_fact_bill_master as
SELECT * FROM
(select t1.*, t2.group_id, t2.shop_id, t2.group_name, t2.shop_name, t2.brand_id,
ROW_NUMBER() OVER (PARTITION BY groupID, shopID, orderKey ORDER BY actionTime desc) rn
from hive_catalog.flink_db.kfk_fact_bill_master_12 t1
JOIN hive_catalog.flink_db.dim_extend_shop_info
/*+ OPTIONS('streaming-source.enable'='true', 'streaming-source.partition.include' = 'latest',
'streaming-source.monitor-interval' = '1 h',
'streaming-source.partition-order' = 'partition-name') */ FOR SYSTEM_TIME AS OF t1.proctime AS t2 --时态表
ON t1.groupID = t2.group_id and t1.shopID = t2.shop_id
where groupID in (202042)) t where t.rn = 1
结果数据 Sink 到 MySQL
CREATE TABLE hive_catalog.flink_db_sink.rt_aggr_bill_food_unit_rollup_flk (
report_date String,
group_id int,
group_name String,
shop_id int,
shop_name String,
brand_id BIGINT,
brand_name String,
province_name String,
city_name String,
foodcategory_name String,
food_name String,
food_code String,
unit String,
rt_food_unit_cnt double,
rt_food_unit_amt double,
rt_food_unit_real_amt double,
PRIMARY KEY (report_date, group_id, shop_id, brand_id, foodcategory_name, food_name, food_code, unit) NOT ENFORCED) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://host:4400/db_name?autoReconnect=true&useSSL=false',
'table-name' = 'table-name',
'username' = 'username',
'password' = 'password'
)
insert into hive_catalog.flink_db_sink.rt_aggr_bill_food_unit_rollup_flk
select reportDate, group_id, group_name, shop_id, shop_name, brand_id, brand_name, province_name, city_name
, SUM(foodNumber) rt_food_cnt
, sum(paidAmount) rt_food_amt
, sum(foodAmount) rt_food_real_amt
from hive_catalog.flink_db.view_fact_bill_master
group by reportDate, group_id, group_name, shop_id, shop_name, brand_id, brand_name, province_name, city_name;- ORC format 的 BUG
在读取 ORC format 的表时,无法读取数据,我也向社区提了一个 Jira: https://issues.apache.org/jira/browse/FLINK-20576,读取其他 format 的表不存在问题,本地测试了读取 parquet 和 csv 都是正常的。
总结下上面的代码,只需通过 Flink SQL 便能实现 Kafka 实时数据流关联最新的 Hive 分区。同时我们结合了 HiveCatalog,可以复用 hive 的表和已经创建过的 kafka source 表,MySql sink 表,使得程序只需要关心具体的业务逻辑,无需关注 source/sink 表的创建,提高了代码的复用性以及可读性。对比之前的方案,纯 SQL 的开发显然降低了开发维护成本和用户门槛。
Flink SQL 开发小技巧
- 结合 Hive catalog,持久化 source 与 sink 表,减少重复建表,使得代码只需关注逻辑 SQL。
- 结合 Flink 视图,组织好业务加工逻辑,提高 SQL 的可读性。
- 利用 SQL Client 调试 SQL,程序没问题后再打包上线,而不是直接提交到集群做测试。
往期精选▼
Spark Shuffle调优之调节map端内存缓冲与reduce端内存占比
Flink中Checkpoint和Savepoint 的 3 个不同点