“我之所以要翻译这本书,也是源于我对大数据生态圈的理解和判断。与传统的MR 计算框架相比,Spark 有着足够的性能和易编程方面的优势,并且Spark 本身也正在形成自己的生态体系。而Spark 的原生语言Scala 将面向对象和函数式编程语言的优势融为一体,因此有着足够的理由让我看好。数据分析和机器学习,就更不必多言了。这都是当前IT 领域最热门的技术方向。”
——《Scala和Spark大数据分析 函数式编程、数据流和机器学习》译者:史跃东
------------------------------------------------------------------图书简介-------------------------------------------------------------------

书名:《Scala和Spark大数据分析 函数式编程、数据流和机器学习》
ISBN:9787302551966
定价:158元
出版时间:2020年6月
京东移动端链接:https://item.m.jd.com/product/12900256.html
--------------------------------------------------------------试读样章----------------------------------------------------------
第 1 章
Scala 简介
第1 章 Scala 简介
“我是Scala,我是一个可扩展的、函数式的、面向对象的编程语言。我可以和你一起成长,也可
以和我一起玩耍,比如以输入一行表达式然后就能立即得到结果的方式。”
——Scala 自述
在最近几年间,Scala 语言正处于稳步上升期,它逐渐被大的开发者和相关从业者所采纳。尤
其是在数据科学和分析领域。另外,由Scala 语言所编写的Apache Spark 则成为快速而通用的大
数据处理引擎。Spark 的成功可归功于多个方面:易用的API 接口、清晰的编程模型,性能优势
等。因此,很自然,Spark 也就为Scala 提供了更多支持;与Python 或Java 相比,Scala 可用的
API 更多一些。并且,在一些新的API 出现之后,首先是支持Scala,而后才是Java、Python 和R
语言。
现在,在使用Spark 和Scala 开始数据处理编程工作前,我们先来熟悉一下Scala 的函数式程
序设计概念、面向对象特性,以及详细了解Scala 的集合API(第一部分)。作为一个开始,我们将
在本章简要介绍Scala 语言。本章内容将覆盖Scala 的历史及其设计目标等一些基本方面。然后将
介绍如何在不同平台(包括Windows、Linux 和macOS)上安装Scala。这样,就可以在自己喜欢的
编辑器或IDE 上进行数据分析编程活动了。本章稍后也将对Java 和Scala 进行对比分析。本章最
后将通过一些例子来带你深入了解Scala 程序设计。
作为概括,本章将涵盖如下主题:
● Scala 的历史与设计目标
● 平台与编辑器
● 安装与创建Scala
● Scala:可扩展的编程语言
● 面向Java 编程人员的Scala
● 面向初学者的Scala
● 本章小结
1.1 Scala 的历史与设计目标
Scala 是一门通用的编程语言,它支持函数式编程,同时也是一个强静态类型的语言系统。Scala
的源代码可被编译成Java 的字节码,因此生成的可执行代码能在JVM 上运行。
Martin Odersky 于2001 年在瑞士洛桑联邦理工学院(EPFL)开始了Scala 语言的设计。该语言
基于他当时使用的Funnel 语言,并进行了扩展。Funnel 也是一种程序设计语言,使用了函数式程
序设计以及Petri 网。Scala 语言的第一个版本于2004 年发布,但只支持Java 平台。稍后,在2004
年6 月,.NET 框架面世了。
Scala 语言很快就变得流行起来,并被广泛采用,因为它不仅支持面向对象的程序设计范例,
还拥抱了函数式程序设计的概念。此外,尽管与Java 相比,Scala 中的符号算子(symbolic operator)
很难读懂,但大多数Scala 的开发人员还是认为Scala 更简洁更易读——Java 则显得过于繁杂。
与其他程序设计语言一样,Scala 语言也是为了某个特定的目标而建立并发展起来的。现在的
问题是,Scala 为什么会被设计出来?它当时是为了解决什么问题?为了回答这些问题,Odersky
在他的博客中写道:
“Scala 的设计工作,源于我们想开发出一种用于更好地支持组件软件(component software)的语言。
我们想在Scala 语言中验证两个假设。第一个假设是用于组件软件的编程语言具备可扩展性,也就是说,
无论该语言用来表述小对象或大对象,其概念都应该是相同的。因此,我们将注意力放在了抽象、组
成以及分解等实现机制上。我们并未给Scala 语言添加一大堆原语(primitive),因为这些东西可能在某
些扩展级别上很有用,但在其他扩展级别上就未必了。第二个假设是为组件软件提供的这种可扩展性
支持能由编程语言提供,该编程语言应该是面向对象和函数式编程的统一和归纳。对于静态类型的语
言来说,Scala 语言则是一个实例,现在这两种范例之间的差别已经很大了。”
无论如何,现在Scala 语言中也开始提供模式匹配和高阶函数等内容。这不是用来填平函数
式编程与面向对象编程之间的鸿沟,而是因为这些本来就是函数式编程中的典型特性。因此,Scala
语言就有了一些令人惊奇的强大的模式匹配特性,它们是一种基于角色(actor-based)的并发处理框
架,还支持一阶或高阶函数。总的来说,其名称Scala 是可扩展语言(Scalable language)的一个合
成词,预示了该语言被设计为会随着用户需求的变化而不断增长。
1.2 平台与编辑器
Scala 可在JVM 上运行,这就使其成为Java 开发人员的一个好选择,开发人员可在代码中添
加一些函数式编程的风格。在编写Scala 程序时,有足够多的编辑器供选择。可以花费一些时间,
对可用的编辑器进行比较排序。如果你已经习惯了某个IDE,那么再使用其他编辑器的话,可能
会比较痛苦。所以,你要花时间好好地挑选一下编辑器。如下是一些可供挑选的编辑器:
● Scala IDE
● Scala plugin for Eclipse
● IntelliJ IDEA
● Emacs
● VIM
使用Eclipse 编写Scala 程序有一些很明显的优势,可以使用相当数量的测试版插件。Eclipse
提供了一些非常优秀的特性,例如本地、远程以及高级别的调试功能,包括语义上的高亮显示,
以及Scala 中的代码辅助完成等。可使用Eclipse 像编写Java 代码一样编写Scala 程序。但我也推
荐你使用Scala IDE(http://scala-ide.org/)——它是一个基于Eclipse 的完全成熟的Scala 编辑器,并
且定制了一些很有趣的特性(如Scala 工作单、ScalaTest 支持、Scala 重构等)。
在我看来,第二个最好用的编辑器是IntelliJ IDEA。其第一个版本于2001 年发布,是第一个集
成了高级代码导航和重构功能的Java IDE。由于InfoWorld的支持(可查看网站http://www.infoworld.
com/article/2683534/development-environments/infoworld-review--top-java-programming-tools.html),
使得在4 个最受欢迎的Java 编程IDE 工具(Eclipse、IntelliJ IDEA、NetBeans 和JDeveloper)
中,IntelliJ 获得了最高分8.5 分(满分10 分)。具体评分情况如图1.1 所示。
 图1.1 最适合Scala/Java 开发人员的IDE
图1.1 最适合Scala/Java 开发人员的IDE
从图1.1 来看,你可能也会对使用其他IDE(如NetBeans 或Jdeveloper)感兴趣。从根本上
讲,究竟哪个编辑器更好用,是开发人员之间永恒的争论话题。这意味着,最终使用哪个IDE,
完全由你自己来定。
1.3 安装与创建Scala
由于Scala 要使用JVM,因此需要确保你的机器上已经安装了Java。如果没有,可以参考后
面的章节,其中展示了如何在Ubuntu 上安装Java。在这一节中,首先,将展示如何在Ubuntu 上
安装Java 8。然后,我们来看看如何在Windows、macOS 和Linux 上安装Scala。
1.3.1 安装Java
为简单起见,在此仅展示如何在Ubuntu 14.04 LTS 64 位机器上安装Java 8。至于如何在
Windows 或macOS 上安装Java,你最好还是花时间使用Google 搜索一番吧。对于Windows 用户
来说,可以访问https://java.com/en/download/help/windows_manual_download.xml 来了解更多内容。
现在,让我们在Ubuntu 上使用分步命令和说明来安装Java 8。首先检查Java 是否已经被
安装:
$ java -version
如果返回消息the program java cannot be found in the following packages,则表明尚未安装Java。
可执行如下命令进行安装:
$ sudo apt-get install default-jre
该命令将安装JRE。但如果不想使用JRE,也可以使用JDK,它通常在Apache Ant、Apache
Maven、Eclipse 以及IntelliJ IDEA 上编译Java 应用时会用到。
Oracle JDK 是官方的JDK,但Oracle 已不再将其提供为Ubuntu 的默认安装选项。你仍然可
以使用apt-get 命令来安装它。要安装任意版本的JDK,需要先执行如下命令:
$ sudo apt-get install python-software-properties
$ sudo apt-get update
$ sudo add-apt-repository ppa:webupd8team/java
$ sudo apt-get update
然后,基于想安装的版本,执行如下命令:
$ sudo apt-get install oracle-java8-installer
安装完成后,不要忘记设置JAVA_HOME 环境变量。只需要使用如下命令即可(为简单起见,
我们假设Java 安装在/usr/lib/jvm/java-8-oracle 目录下):
$ echo "export JAVA_HOME=/usr/lib/jvm/java-8-oracle" >> ~/.bashrc
$ echo "export PATH=$PATH:$JAVA_HOME/bin" >> ~/.bashrc
$ source ~/.bashrc
现在,让我们使用以下方式查看一下JAVA_HOME:
$ echo $JAVA_HOME
你在终端上应能看到如下结果:
/usr/lib/jvm/java-8-oracle
现在,让我们使用如下命令来确认Java 已经被成功安装(这里,你可能会看到最新版本):
$ java -version
你将得到如下输出:
java version "1.8.0_121"
Java(TM) SE Runtime Environment (build 1.8.0_121-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
现在你已经成功地在机器上安装了Java,一旦安装好,就可以准备写Scala 代码了。我们将
在接下来的章节中完成该内容。
1.3.2 Windows
这一部分将关注如何在Windows 7 的电脑上安装Scala。但是在最后,无论你使用的Windows
是什么版本,其实都没什么关系。
(1) 第一步,需要去官网下载Scala 的安装压缩包。可在https://www.Scala-lang.org/
download/all.html 上找到它。在该页面的其他资源部分下面,可看到你能够安装的Scala 归档文件。
这里选择下载Scala 2.11.8 安装包,如图1.2 所示。

图1.2 在Windows 上安装Scala
(2) 下载完成后,对文件进行解压操作,并将其放置到你想要的目录下。可将该文件命名为
Scala,这样以后你查找起来也会比较方便。最后,需要在电脑上为Scala 设置一个名为PATH 的
全局可见的变量。因此,需要导航到“计算机”|“属性”,如图1.3 所示。
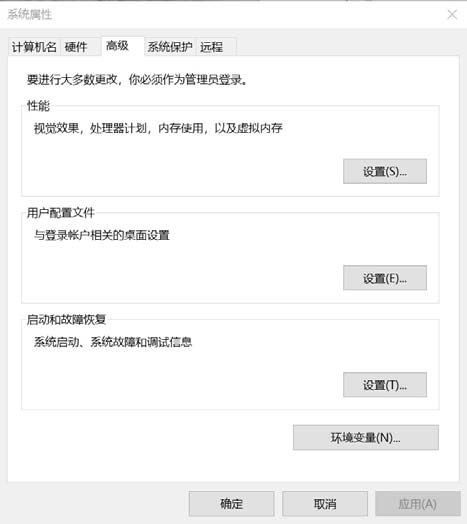
图1.3 Windows 上的“环境变量”标签
(3) 从这里设置环境变量,获取Scala 的bin 目录的位置,将其扩展到PATH 环境变量的后面。
然后应用修改并单击“确定”,如图1.4 所示。

图1.4 为Scala 添加环境变量
(4) 现在,你已在Windows 上做好了安装准备。打开cmd 命令行,然后输入scala。如果你在
前面的安装和配置都是成功的,就能在屏幕上看到类似于图1.5 的输出。
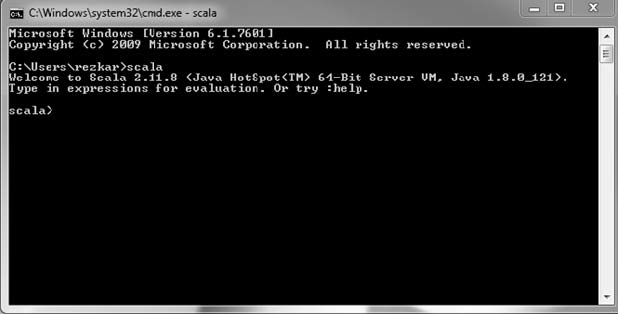
图1.5 从Scala shell 访问Scala
1.3.3 macOS
现在可以在你的macOS 上安装Scala 了。在macOS 上安装Scala 有很多种方式。在这里,我
们打算为你介绍其中的两种。
1. 使用Homebrew 安装工具
(1) 首先,检查系统是否安装了Xcode,因为这一步需要这一组件。可以从苹果公司的Apple
Store 上免费下载并安装。
(2) 接下来,需要在终端上执行如下命令来从内部安装Homebrew。
$ /usr/bin/ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"
注意:
上述安装命令可能会被Homebrew 的工作人员随时修改。如果该命令无法正常工作,可以通
过Homebrew 的网站(http://brew.sh/)获取最新的安装“咒语”。
(3) 现在,可在终端上执行brew install scala 命令来安装Scala。
(4) 最后,可在终端上简单地输入一些Scala 代码了(第二行),之后就可以看到如图1.6 所示
的内容。
 图1.6 macOS 上的Scala shell 窗口
图1.6 macOS 上的Scala shell 窗口
2. 手工安装
在手工安装Scala 之前,可在http://www.Scala-lang.org/download/网站上选择你喜欢的Scala
版本,并下载对应的.tgz 文件。在下载完你喜欢的Scala 版本后,可按如下方式解压:
$ tar xvf scala-2.11.8.tgz
然后,以如下方式将其移到/usr/local/share 目录下:
$ sudo mv scala-2.11.8 /usr/local/share
现在,为保证安装结果能够持久,请执行如下命令:
$ echo "export SCALA_HOME=/usr/local/share/scala-2.11.8" >> ~/.bash_profile
$ echo "export PATH=$PATH: $SCALA_HOME/bin" >> ~/.bash_profile
这样就行了。现在,介绍一下在Linux 发行版(例如Ubuntu)上如何安装Scala。
3. Linux
在这一章节中,我们将为你展示在Linux 发行版Ubuntu 上安装Scala 的流程。在开始之前,
让我们先确保Scala 能够被正确安装。可以使用如下命令执行检查:
$ scala -version
如果你的系统上已经安装了Scala,你将在终端上看到如下消息:
Scala code runner version 2.11.8 --Copyright 2002-2016, LAMP/EPFL
要注意这一点,在写作此安装过程时,我们使用的是当时最新的Scala 版本。也就是2.11.8。
如果你还没有在系统上安装Scala,则在进行下一步之前要确保先安装完毕。可从Scala 的官网下
载最新版本(为清楚起见,可参考图1.2)。为简便起见,我们下载Scala 2.11.8,如下:
$ cd Downloads/
$ wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
等到下载完毕,就可在下载的文件夹中找到Scala 的tar 文件了。
注意:
用户应该使用如下命令进入Downloads 目录:$ cd /Downloads/。当然,基于你的系统,选择
的语言可能不同,Downloads 文件夹的名称也可能有所不同。
为将Scala tar 文件从它所在的位置中抽取出来,可执行如下命令:
$ tar -xvzf scala-2.11.8.tgz
现在,通过执行如下命令将Scala 移动到用户选定的位置(如/usr/local/share),或者是手动
移动:
$ sudo mv scala-2.11.8 /usr/local/share/
使用如下命令移动到用户的主目录:
$ cd ~
然后,使用如下命令设置Scala 的主目录:
$ echo "export SCALA_HOME=/usr/local/share/scala-2.11.8" >> ~/.bashrc
$ echo "export PATH=$PATH:$SCALA_HOME/bin" >> ~/.bashrc
接下来,为让上述修改在会话中变得持久,可执行如下命令:
$ source ~/.bashrc
当安装完成后,你最好执行如下命令来检查安装结果:
$ scala -version
如果Scala 在你的系统上已经配置成功,就可在终端上看到如下信息:
Scala code runner version 2.11.8 --Copyright 2002-2016, LAMP/EPFL
现在,让我们在终端上输入scala 命令来进入Scala shell。如图1.7 所示。
图1.7 Linux 上的Scala shell(Ubuntu 发行版)
最后,也可以使用apt-get 命令来安装Scala,如下所示:
$ sudo apt-get install scala
该命令会下载最新版的Scala(这里是2.12.x)。但Spark 尚未支持Scala 2.12 版本(至少是在我
们写作本章时)。因此,我们推荐使用前面的手动安装方式。
1.4 Scala:可扩展的编程语言
Scala 的代码从规模上可以很好地扩展到大型程序。对于其他编程语言可能需要编写数十行代
码才能实现的功能,在Scala 中能简便地实现;你能以简洁有效的方式获得表达编程的一般模式
和概念的能力。本节将介绍Odersky(Martin Odersky,Scala 语言之父)为我们创造的这些令人激动
的特性。
1.4.1 Scala 是面向对象的
Scala 是面向对象编程语言的一个非常好的例子。为给你的对象定义类型或行为,需要使用类
和特质的概念,这些内容将在第2 章中展开讲述。Scala 并不支持直接多态集成,但是要实现这种
架构,也可以使用Scala 的子类扩展,或者是混合基成分(mixing-based composition)。这些内容也
将在后续章节中讲述。
1.4.2 Scala 是函数式的
函数式编程通常将函数视为一等公民。在Scala 中,则是通过语法糖(syntactic sugar)和扩展其
特质的对象(例如Function2)来实现的。但这是在Scala 中实现函数式编程的方法。此外,Scala 也
设计了一种简便的方式来定义匿名函数。并且Scala 支持高阶函数,也允许函数嵌套。后面将深
入介绍这些概念的语法。
另外,Scala 也能帮助你以不可变的方式进行编码,并且基于此,可以轻松地使用同步与并发
机制来实现并行处理。
1.4.3 Scala 是静态类型的
不同于其他静态类型语言,例如Pascal、Rust 等,Scala 并不期望你提供冗余的类型信息。在
绝大部分情况下,你不必指定类型。更重要的是,你甚至不用再重复它们。
注意:
如果该语言的类型在编译时就是知道的,则该编程语言被称为是静态类型的。这也意味着,
作为一名编程人员,需要确定每个变量的类型。Scala、Java、C、OCaml、Haskell 和C++等都是
静态类型语言。另一方面,Perl、Ruby、Python 等则是动态类型语言;这些语言中的类型,并不
与变量或字段相关,而与运行时的值相关。
Scala 的静态类型天性,确保了所有种类的检查都是被编译器完成的。这是Scala 的一个极
其强大的特性,因为它可以帮助你及早发现/捕获大多数bug 或错误。
1.4.4 在JVM 上运行Scala
与Java 一样,Scala 代码也可被编译成字节码并在JVM 上简单执行。这意味着Scala 和Java
的运行时平台是一样的。由于它们都是以字节码作为编译的输出结果,因此可以轻松地从Java
转向Scala,也可以轻松地将二者集成起来,甚至在你的Android 应用中使用Scala 来添加一个
函数。
小技巧:
在Scala 程序中使用Java 代码相当容易,但反过来就很难了。这主要是因为Scala 的语法糖
特性。
另外,和使用javac 命令将Java 代码编译成字节码一样,Scala 也有一条scalas 命令,它可将
Scala 代码编译成字节码。
1.4.5 Scala 可以执行Java 代码
正如在前面提到的,Scala 也可以用来执行Java 代码。它不仅可安装Java 代码,甚至也
允许你使用来自Java SDK 的所有类,即便是你在Scala 环境中已经有了自己的预定义类、项
目或包。
1.4.6 Scala 可以完成并发与同步处理
对于Scala 来说,你能以简洁有效的方式获得表达编程的一般模式和概念的能力。另外,Scala
也能帮助你以不可变的方式进行编码,并且基于此,可轻松地使用同步与并发机制来实现并行
处理。
1.5 面向Java 编程人员的Scala
Scala 有着与Java 完全不同的一些特性。本节将讨论其中一部分特性。对于那些具备Java 编
程背景,或者是对基本的Java 语法有了解的编程人员而言,这一部分的内容将非常有用。
1.5.1 一切类型都是对象
Scala 中的每一个值看起来都像一个对象。这句话意味着一切看起来都像对象。但其中一部分
并非真正的对象,你将在接下来的章节中看到对这些内容的解释。例如,在Scala 中,引用类型
和原生类型的区别依然存在,但大部分区别都已经被隐藏起来了;在Scala 中,字符串已经被隐
式地转换为字符集合,而在Java 中却非如此!
1.5.2 类型推导
如果你不熟悉这个术语,这没什么,但是在编译时会出现类型推导(deduction of types)。等一
下,难道这不是指动态类型吗?不是。注意这里我所说的类型推导,这与动态类型语言的处理完
全不同,另一件事情是,这一推导是在编译时而非运行时完成。很多编程语言都内置了这一功能,
但具体实现则完全不同。一开始,这可能造成疑惑,但当看到代码示例时就会清晰起来。让我们
跳到Scala REPL 来分析一些示例吧。
1.5.3 Scala REPL
Scala REPL 是一个非常强大的特性,它让我们在Scala shell 中编写Scala 代码变得直接又简
单。REPL 指的是Read-Eval-Print-Loop(读取-求值-输出-循环),也被称为交互式解释器。这意味着
对于一段程序来说,REPL 可以:
(1) 读取你输入的表达式。
(2) 使用Scala 编译器求出在第(1)步输入的表达式的值。
(3) 打印出在第(2)步求出的结果。
(4) 以循环方式等待你输入更多表达式。
从图1.8 中可以看到,这里并没有什么魔法,在编译时,变量会被自动推导出最合适的类型。
如果尝试声明:
i:Int = "hello" 图1.8 Scala REPL 样例1
图1.8 Scala REPL 样例1
Scala 会抛出如下错误:
<console>:11: error: type mismatch;
found : String("hello")
required: Int
val i:Int = "hello"
^
按照Odersky 的说法,“应该通过富字符串(RichString)将字符映射到字符映射从而再次生成一
个富字符串,一如与Scala REP 的交互”。这句话可使用下面的代码来证明:
scala> "abc" map (x => (x + 1).toChar)
res0: String = bcd
但如果有人使用了一个方法,将字符转换为整型或者字符串,将发生什么?在这个例子中,
Scala 会将其作为一个整数向量进行转换,这也称为不可变性。这是Scala 集合的一个特性。我们
将在第9 章讲解它。我们也将在第4 章讲述Scala 集合的更多细节。
"abc" map (x => (x + 1))
res1: scala.collection.immutable.IndexedSeq[Int] = Vector(98, 99, 100)
在这里,无论是对象的静态方法还是动态方法都是可用的。例如,如果你将字符串hello 声明
为x,然后尝试访问x 的静态方法和动态方法,则它们也都是可用的。在Scala shell 中输入x,接
着输入.再输入<tab>,就可以找到这些可用的方法:
scala> val x = "hello"
x: java.lang.String = hello
scala> x.re<tab>
reduce reduceRight replaceAll reverse
reduceLeft reduceRightOption replaceAllLiterally
reverseIterator
reduceLeftOption regionMatches replaceFirst reverseMap
reduceOption replace repr
scala>
这一切都是通过反射即时完成的。因此,甚至是你刚刚定义的匿名类同样可以访问:
scala> val x = new AnyRef{def helloWord = "Hello, world!"}
x: AnyRef{def helloWord: String} = $anon$1@58065f0c
scala> x.helloWord
def helloWord: String
scala> x.helloWord
warning: there was one feature warning; re-run with -feature for details
res0: String = Hello, world!
上述两个例子也可以在Scala shell 中展示出来,如图1.9 所示。
“所以这就证明了,Scala 能根据传入函数参数的结果类型来匹配不同的类型!”
——Odersky
 图1.9 Scala REPL 样例2
图1.9 Scala REPL 样例2
1.5.4 嵌套函数
编程语言为何需要支持嵌套函数?大多数情况下,是因为我们想让维护的方法一直都具有较
少的代码行数,并避免重写大函数。Java 中,对此的一个典型解决方法是在类级别定义所有小函
数,但其他方法可很容易地引用或访问这些函数。尽管这些只是一些辅助方法。但在Scala 中,
情况却有所不同。可在函数内部再定义函数。通过这种方式,阻止了对这些函数的外部访问:
def sum(vector: List[Int]): Int = {
//Nested helper method (won't be accessed from outside this function
def helper(acc: Int, remaining: List[Int]): Int = remaining match {
case Nil => acc
case _=> helper(acc + remaining.head, remaining.tail)
}
//Call the nested method
helper(0, vector)
}
在此,我们并不期望你立刻就能理解这些代码片段,它只是为了展示Scala 与Java 之间的不
同之处。
1.5.5 导入语句
在Java 中,你只能在代码文件头部导入包,其位置是在包语句的右边。但是在Scala 中情况
就有所不同。可在源文件内部的几乎任意位置编写导入包的语句(例如,甚至可在一个类或方法的
内部编写导入语句)。你只需要注意导入语句的作用域即可。因为它继承了方法中的本地变量或类
成员的作用域。Scala 中的_(下画线)可用作导入时的通配符,它与你在Java 中使用的*(星号)类似:
//Import everything from the package math
import math._
如果想使用{ }来表明导入的对象集合来自于同一个父包,只需要使用一行代码即可。在Java
中,你可能需要使用多行代码来完成这样的工作。
//Import math.sin and math.cos
import math.{sin, cos}
与Java 不同,Scala 中并没有静态导入的概念。换句话说,Scala 中并不存在静态的概念。但
作为一名开发人员,很明显,可以使用一条正常的导入语句来导入一个或者多个对象。前面的例
子已经展示了这样的内容。我们从一个名为Math 的包对象中导入sin 和cos 方法。为展示这个例
子,如果是从Java 编程人员的角度出发,则应该按照如下方式定义前面的代码片段:
import static java.lang.Math.sin;
import static java.lang.Math.cos;
Scala 的另一个优美之处在于,在Scala 中,也可以重命名你导入的包,以免与包含相似对象
的包出现类型冲突。如下语句在Scala 中是有效的:
//Import Scala.collection.mutable.Map as MutableMap
import Scala.collection.mutable.{Map => MutableMap}
最后,在导入时,你可能想排除包中的一些对象。可以使用通配符来完成这一操作:
//Import everything from math, but hide cos
import math.{cos => _, _}
1.5.6 作为方法的操作符
值得提醒的是,Scala 并不支持操作符重载。有人可能因此认为,Scala 中没有操作符。
作为调用只有一个参数的方法的一种替代,可以使用中缀语法。该语法为你提供了一个新的
玩法,就像是你使用了操作符重载,跟你在C++中的动作类似。例如:
val x = 45
val y = 75
在下面的例子中,+指的是类Int 中的一个方法。如下代码是一个无转换方法的调用语法:
val add1 = x.+(y)
更正式一点,也可以使用中缀语法来完成这个操作,如下:
val add2 = x + y
不仅如此,还可以使用中缀语法。但该方法只有一个参数,如下:
val my_result = List(3, 6, 15, 34, 76) contains 5
这是使用中缀语法的一个特例。也就是说,如果方法的名称以:(冒号)结束,则调用就是向右
关联(right associative)。这意味着该方法是在右边的参数上调用(左边的表达式作为参数),而不是
以另一种方式被调用。例如,下面的句子在Scala 中是有效的:
val my_list = List(3, 6, 15, 34, 76)
是my_list.+:(5),而不是5.+:(my_list)。更正式的写法是:
val my_result = 5 +: my_list
现在,让我们在Scala REPL 中看一下前面这个例子:
scala> val my_list = 5 +: List(3, 6, 15, 34, 76)
my_list: List[Int] = List(5, 3, 6, 15, 34, 76)
scala> val my_result2 = 5+:my_list
my_result2: List[Int] = List(5, 5, 3, 6, 15, 34, 76)
scala> println(my_result2)
List(5, 5, 3, 6, 15, 34, 76)
scala>
这里的操作符仅是方法,因此它们也像方法那样,可以被简单地进行重载。
1.5.7 方法与参数列表
在Scala 中,一个方法可以有多个参数列表,或者是一个参数列表都没有。另外,在Java 中,
一个方法通常都有一个参数列表,可以是0 个或者多个参数。例如,在Scala 中,如下的方法定
义语句是有效的(使用currie 符号),该方法有两个参数列表:
def sum(x: Int)(y: Int) = x + y
该语句不能写成如下形式:
def sum(x: Int, y: Int) = x + y
一个方法(这里将其称为sum2)也可以没有一个参数列表,如下:
def sum2 = sum(2) _
现在,可调用方法add2,它会返回带有一个参数的函数。然后,它使用参数5 调用该函数,
如下:
val result = add2(5)
1.5.8 方法内部的方法
有时,你想让应用代码更模块化一些,从而避免出现一些太长或太复杂的方法。Scala 为你提
供了这样的功能,以免方法变得过于庞大。这样可将它们拆分成几个较小的方法。
另外,Java 则只允许你在类级别定义方法。例如,假设你有如下的方法定义:
def main_method(xs: List[Int]): Int = {
//This is the nested helper/auxiliary method
def auxiliary_method(accu: Int, rest: List[Int]): Int = rest match {
case Nil => accu
case _=> auxiliary_method(accu + rest.head, rest.tail)
}
}
现在,可以按照如下方式来调用该辅助方法:
auxiliary_method(0, xs)
考虑一下上面的内容,如下是一个有效的完整代码段:
def main_method(xs: List[Int]): Int = {
//This is the nested helper/auxiliary method
def auxiliary_method(accu: Int, rest: List[Int]): Int = rest match {
case Nil => accu
case _=> auxiliary_method(accu + rest.head, rest.tail)
}
auxiliary_method(0, xs)
}
1.5.9 Scala 中的构造器
Scala 中令人惊奇的一件事情,就是Scala 类体本身就是一个构造器。但事实上,Scala 是以更
明确的方式来实现这一点的。此后,该类的一个实体就被创建出来并运行。不仅如此,在类的声
明行里,还可以指定参数。
结论是,该类中定义的所有方法都可访问构造器的参数。例如,如下的类和构造器定义在Scala
中都是有效的:
class Hello(name: String) {
//Statement executed as part of the constructor
println("New instance with name: " + name)
//Method which accesses the constructor argument
def sayHello = println("Hello, " + name + "!")
}
等价的Java 类就像下面这样:
public class Hello {
private final String name;
public Hello(String name) {
System.out.println("New instance with name: " + name);
this.name = name;
}
public void sayHello() {
System.out.println("Hello, " + name + "!");
}
}
1.5.10 代替静态方法的对象
正如在前面提到的,Scala 中不存在静态。你无法进行静态导入,或给类添加静态方法。在
Scala 中,当你在同一个源文件中定义对象,并且该对象的名称与类名相同时,该对象就被称为类
的伴生(companion)对象。你在类的伴生对象中定义的函数和Java 中类的静态方法类似:
class HelloCity(CityName: String) {
def sayHelloToCity = println("Hello, " + CityName + "!")
}
这里展示了你如何为类Hello 定义一个伴生对象:
object HelloCity {
//Factory method
def apply(CityName: String) = new Hello(CityName)
}
在Java 中等价的类则像下面这样:
public class HelloCity {
private final String CityName;
public HelloCity(String CityName) {
this.CityName = CityName;
}
public void sayHello() {
System.out.println("Hello, " + CityName + "!");
}
public static HelloCity apply(String CityName) {
return new Hello(CityName);
}
}
所以,这个简单的类中就有了这么冗长的内容,不是吗?Scala 中的应用方法是以不同方式被
处理的。这样就可以找到一种特殊的快捷方式来调用它。如下是你熟悉的调用方法:
val hello1 = Hello.apply("Dublin")
下面则使用快捷方式来调用,与上面的方式等价:
val hello2 = Hello("Dublin")
要注意,这只有在代码中使用应用方法时才有效,因为Scala 以这种特殊方法来对待指定的
应用。
1.5.11 特质
Scala 提供了一个卓越功能来扩展并丰富类的行为。这些特质(trait)与你定义函数原型(function
prototype)或签名的接口类似。因此,有了这项功能,就拥有了来自不同特质的混合功能,并基于
此种方式,就丰富了类的行为。所以,Scala 中的特质有什么好处?因为它们使得来自不同特质的
类进行组合成为可能,而这些特质可用来构建基块。与往常一样,我们来看一个例子。这是Java
中常规的建立日志记录的方法。
要注意,尽管可按自己的想法混合任意数量的特质。但与Java 一样,Scala 确实不支持多重
继承。但无论是Java 还是Scala,一个子类都只能扩展一个超类。例如,在Java 中:
class SomeClass {
//First, to have to log for a class, you must initialize it
final static Logger log = LoggerFactory.getLogger(this.getClass());
...
//For logging to be efficient, you must always check, if logging level
//for current message is enabled
//BAD, you will waste execution time if the log level is an error, fatal,
//etc.
log.debug("Some debug message");
...
//GOOD, it saves execution time for something more useful
if (log.isDebugEnabled()) { log.debug("Some debug message"); }
//BUT looks clunky, and it's tiresome to write this construct every time
//you want to log something.
}
要了解关于此内容的更详细的讨论,请浏览https://stackoverflow.com/questions/963492/
in-log4j-does-checking-isdebugenabled-before-logging-improve-performance/963681#963681。
但特质则有所不同。经常检查被启用的日志级别其实是一件很无聊的事情。但如果你写了一
次这种例行检查的代码,然后就在任意类中予以复用,这个就比较好了。Scala 中的特质使得这样
的想法成为可能,例如:
trait Logging {
lazy val log = LoggerFactory.getLogger(this.getClass.getName)
//Let's start with info level...
...
//Debug level here...
def debug() {
if (log.isDebugEnabled) log.info(s"${msg}")
}
def debug(msg: => Any, throwable: => Throwable) {
if (log.isDebugEnabled) log.info(s"${msg}", throwable)
}
...
//Repeat it for all log levels you want to use
}
如果你查看了上述代码,就会看到一个以s 开头的字符串的例子。Scala 提供了一种从你提供
的数据中创建字符串的机制,称为字符串插值(string interpolation)。
注意:
字符串插值允许你将被引用的变量直接插入字符串文本中。例如:
scala> val name = "John Breslin"
scala> println(s"Hello, $name") //Hello, John Breslin.
现在,我们就能获得一种高效的日志程序,并采用一种更传统的可复用代码块的形式。为对
任意类都启用日志记录,只需要将其混入Logging 特质即可!太神奇了!现在,下面就是将Logging
特质添加进类的全部内容:
class SomeClass extends Logging {
...
//With logging trait, no need for declaring a logger manually for every
//class
//And now, your logging routine is either efficient and doesn't litter
//the code!
log.debug("Some debug message")
...
}
并且,将多个特质进行混合也是可能的。例如,对于前述的特质(也就是Logging),可按如下
顺序进行扩展:
trait Logging {
override def toString = "Logging "
}
class A extends Logging {
override def toString = "A->" + super.toString
}
trait B extends Logging {
override def toString = "B->" + super.toString
}
trait C extends Logging {
override def toString = "C->" + super.toString
}
class D extends A with B with C {
override def toString = "D->" + super.toString
}
但需要注意,Scala 的类可一次性扩展多个特质,而JVM 类一次则只能扩展一个父类。
现在,为调用上述特质和类,我们在Scala REPL 中使用new D() ,如图1.10 所示。 图1.10 混合多个特质
图1.10 混合多个特质
到目前为止,本章的一切内容看起来都很顺利。现在,让我们开始一个新的部分,这里将讨
论一些与初学者相关的主题。
1.6 面向初学者的Scala
在这部分,你将发现,我们会假设你已经对其他编程语言有了初步的理解。如果Scala 是你
进入代码世界所接触到的第一门编程语言,你将在互联网上找到大量专门为初学者解释Scala 的
材料、辅导内容、视频和课程。
小技巧:
在Coursera 上,有专门的关于Scala 的内容:https://www.coursera.org/specializations/scala。该
课程由Scala 的创建者Martin Odersky 亲自讲授。该在线课程采用了一种带有学院派风格的授课方
式来讲解函数式编程的基础知识。通过完成一些编程的作业,你将学到很多关于Scala 的知识。
不仅如此, 该网站上的这一部分还包含了Apache Spark 相关的课程。此外,
Kojo(http://www.kogics.net/sf:kojo)是一个交互式学习环境,在这里可使用Scala 进行编程,从而探
索数学、艺术、音乐、动画,当然还有游戏。
1.6.1 你的第一行代码
作为第一个例子,我们将使用相当流行的“Hello, world!”程序来展示如何使用Scala 以及相
关的工具,当然你不必对这些了解太多就可上手。打开你喜爱的编辑器(这里的例子是运行在
Windows 7 上的,当然也可运行在Ubuntu 或macOS 上),也就是Notepad++,然后输入如下代
码行:
object HelloWorld {
def main(args: Array[String]){
println("Hello, world!")
}
}
现在,将这些代码保存,并指定一个名字:HelloWorld.scala,如图1.11 所示。 图1.11 使用Notepad++保存你的第一个Scala 源代码
图1.11 使用Notepad++保存你的第一个Scala 源代码
然后以如下方式编译该源文件:
C:\>scalac HelloWorld.scala
C:\>scala HelloWorld
Hello, world!
C:\>
对于具备一些编程经验的人员而言,Scala 的程序看起来应该也是比较熟悉的。它有一个main
方法用于在控制台上打印字符串“Hello, world!”。接下来,为了看清是如何定义main 函数的,
我们使用了def main()这样奇怪的语法来定义它。def 是Scala 的关键字,用于声明/定义一个方法。
然后,我们使用Array[String]作为该方法的一个参数。该参数是一个字符串的数组,可用来对程
序进行初始化配置。如果省略它也是允许的。接下来使用通用的println()方法,它带有一个字符
串(可能是一个已经格式化的字符串)并将其打印到控制台上。一个简单的HelloWorld 就开启了许
多需要学习的主题。主要有三个:
● 方法(在稍后的章节中进行讲解)
● 对象与类(在稍后的章节中进行讲解)
● 类型推导(前面已解释过)
1.6.2 交互式运行Scala!
scala 命令可以为你开始交互式shell,这样就可以交互式地解释Scala 的表达式:
> scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_121).
Type in expressions for evaluation.Or try :help.
scala>
scala> object HelloWorld {
| def main(args: Array[String]){
| println("Hello, world!")
| }
| }
defined object HelloWorld
scala> HelloWorld.main(Array())
Hello, world!
scala>
注意:
快捷方式:q 代表内部shell 命令quit,用于退出解释器。
1.6.3 编译
与javac 命令相似,scalac 命令可用来编译一个或多个Scala 源文件,并生成字节码作为输出,
然后就可以在任意JVM 上执行。为了编译HelloWorld 对象,可使用如下命令:
> scalac HelloWorld.scala
默认情况下,scalac 会在当前工作目录下生成类文件。也可以使用-d 选项来指定不同的输出
目录:
> scalac -d classes HelloWorld.scala
但要注意,这里的classes 目录必须要在执行该命令之前就已创建完毕。
使用scala 命令执行它
scala 命令执行由解释器生成的字节码:
$ scala HelloWorld
scala 命令允许我们指定不同的命令选项,例如-classpath(别名-cp)选项:
$ scala -cp classes HelloWorld
在使用scala 命令执行源文件之前,你应该有一个main 方法,它会作为应用程序的入口点。
换言之,你应该有一个对象来扩展Trait Scala.App,然后该对象中包含的所有代码都将被该命令执
行。如下是同样的“Hello, world!”例子,但使用了App 特质:
#!/usr/bin/env Scala
object HelloWorld extends App {
println("Hello, world!")
}
HelloWorld.main(args)
上述脚本可以直接在命令shell 中运行:
./script.sh
注意,这里假设文件script.sh 具有执行权限:
$ sudo chmod +x script.sh
然后,scala 命令的搜索路径也已在$PATH 环境变量中予以设置。
1.7 本章小结
本章介绍了Scala 编程语言的基础知识、特性和可用的编辑器,也简要探讨了Scala 及其语法。
对于初学者,尤其是初次接触Scala 编程语言的人员来说,我们也展示了如何安装并建立开发环
境。本章还讲述了如何编写、编译以及执行一段简单的Scala 代码。不仅如此,为便于具有Java
背景的人员学习,还进行了Scala 和Java 之间的比较。
Scala 是静态类型,但Python 是动态类型。Scala 绝大部分情况下遵循函数式编程范例,而
Python 却非如此。Python 具有独特的语法,并且大部分情况下不使用括号,但是Scala 大部分情
况下则需要它们。在Scala 中,几乎所有东西都是表达式,但在Python 中显然并非如此。但有些
特点看起来则错综复杂。另外,根据https://stackoverflow.com/questions/1065720/what-is-the-purposeof-
scala-programming-language/5828684#5828684 所提供的文档,Scala 编译器就像一个自由测试工
具,其文档太过复杂。如果能恰当地部署Scala,它几乎能完成所有事情,原因在于Scala 拥有其
一致且连贯的API。
第2 章将指导你进一步掌握基础知识,以便你了解Scala 如何实现面向对象的范例,该范例
允许我们创建模块化的软件系统。