一、索引
1. 索引概念
我们可以通过对数据表中的字段创建索引来提高查询速度
2. 常见索引分类
| 索引名称 | 说明 |
|---|---|
| 主键索引 (primary key) | 主键是一种唯一性索引,每个表只能有一个主键, 用于标识数据表中的每一条记录 |
| 唯一索引 (unique) | 唯一索引指的是索引列的所有值都只能出现一次, 必须唯一. |
| 普通索引 (index) | 最常见的索引,作用就是提高对数据的访问速度 |
PS:
MySql将一个表的索引都保存在同一个索引文件中, 如果对中数据进行增删改操作,MySql都会自动的更新索引.

文件夹里面文件代表的内容
| 文件后缀 | 说明 |
|---|---|
| frm | 表结构文件 |
| ibd | 数据和索引文件 |
| opt | 存储当前数据库的默认字符集和字符校验规则 |
3. 创建索引
- 主键索引 (
primary key)
特点:主键是一种唯一性索引,每个表只能有一个主键,用于标识数据表中的某一条记录
注意:一个表可以没有主键,但最多只能有一个主键,并且主键值不能包含NULL。
创建主键索引方法跳转 | https://blog.csdn.net/Guai_Ka/article/details/113525400#primarykey - 唯一索引(
unique)
特点: 索引列的所有值都只能出现一次, 必须唯一.
注意:唯一索引可以保证数据记录的唯一性。事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
创建唯一索引方法跳转 | https://blog.csdn.net/Guai_Ka/article/details/113525400#UNIQUE - 普通索引 (
index)
普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。
因此,应该只为那些最经常出现在查询条件(where column=)或排序条件(orderby column)中的数据列创建索引。-
创建索引
-- 使用create index 语句创建: 在已有的表上创建索引 create index 索引名 on 表名(列名[长度]) -- 修改表结构添加索引 ALTER TABLE 表名 ADD INDEX 索引名 (列名) -
删除索引
由于索引会占用一定的磁盘空间,因此,为了避免影响数据库的性能,应该及时删除不再使用的索引ALTER TABLE 表名 DROP INDEX 索引名;
-
4. 索引性能测试
-
在没有添加索引的情况下, 使用
dname字段进行查询#未添加索引,进行分组查询 SELECT * FROM test_index GROUP BY dname; -
耗时
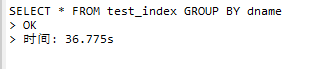
-
为
dname字段 添加索引ALTER TABLE test_index ADD INDEX dname_indx(dname);注意:
- 一般我们都是在创建表的时候 就确定需要添加索引的字段
- 添加索引也是要时间的.

-
执行分组查询
#添加索引后,进行分组查询 SELECT * FROM test_index GROUP BY dname;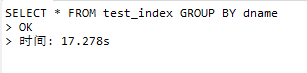
5. 索引的优缺点总结
- 添加索引首先应考虑在 where 及 order by 涉及的列上建立索引。
- 索引的优点
- 可以大大的提高查询速度
- 可以显著的减少查询中分组和排序的时间。
- 通过创建唯一索引保证数据的唯一性
- 索引的缺点
- 创建索引和维护索引需要时间,而且数据量越大时间越长
- 当对表中的数据进行增加,修改,删除的时候,索引也要同时进行维护,降低了数据的维护速度
- 索引文件需要占据磁盘空间
二、视图(操作视图就相当于操作一张只读表)
1. 什么是视图
- 视图是一种虚拟表。
- 视图建立在已有表的基础上, 视图赖以建立的这些表称为基表。
- 向视图提供数据内容的语句为 SELECT 语句, 可以将视图理解为存储起来的 SELECT 语句.
- 视图向用户提供基表数据的另一种表现形式
2. 视图的作用
- 权限控制时可以使用
- 如果某个查询的结果出现的十分频繁,并且查询语法比较复杂.
- 那么这个时候,就可以根据这条查询语句构建一张视图方便查询
- 简化复杂的多表查询
- 视图 本身就是一条查询SQL,我们可以将一次复杂的查询 构建成一张视图, 用户只要查询视图就可以获取想要得到的信息(不需要再编写复杂的SQL)
- 视图主要就是为了简化多表的查询
3. 视图的使用
创建视图
create view 视图名 [字段列表] as select 查询语句;
-- view: 表示视图
-- 视图名:一般命名为:表名_表名_view
-- 字段列表: 可选参数,表示属性清单,指定视图中各个属性的名称,默认情况下,与SELECT语句中查询的属性相同
-- as : 表示视图要执行的操作
-- select语句: 向视图提供数据内容
查询视图 ,当做一张只读的表操作就可以
SELECT * FROM 视图名;
4. 视图与表的区别
- 视图是建立在表的基础上,表存储数据库中的数据,而视图只是做一个数据的展示
- 通过视图不能改变表中数据(一般情况下视图中的数据都是表中的列 经过计算得到的结果,不允许更新)
- 通过视图,不要进行增删改操作,视图主要就是用来简化查询
- 删除视图,表不受影响,而删除表,视图不再起作用
三、存储过程(了解,互联网项目开发中基本上不会使用到)
1. 什么是存储过程
- MySQL 5.0 版本开始支持存储过程。
- 存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
- 简单理解: 存储过程其实就是一堆 SQL 语句的合并。中间加入了一些逻辑控制
2. 存储过程的优缺点
- 优点:
- 存储过程一旦调试完成后,就可以稳定运行,(前提是,业务需求要相对稳定,没有变化)
- 存储过程减少业务系统与数据库的交互,降低耦合,数据库交互更加快捷(应用服务器,与数据库服务器不在同一个地区)
- 缺点:
- 在互联网行业中,大量使用MySQL,MySQL的存储过程与Oracle的相比较弱,所以较少使用,并且互联网行业需求变化较快也是原因之一
- 尽量在简单的逻辑中使用,存储过程移植十分困难,数据库集群环境,保证各个库之间存储过程变更一致也十分困难。
- 阿里的代码规范里也提出了禁止使用存储过程,存储过程维护起来的确麻烦;

3. 存储过程的创建方式
-
方式1:(无参存储过程)
创建存储过程:DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$ CREATE PROCEDURE 过程名称() -- 声明存储过程 BEGIN -- 开始编写存储过程 -- 要执行的操作 END $$ -- 存储过程结束调用存储过程:
call 存储过程名 -
方式2 (参数的存储过程)
IN 输入参数:表示调用者向存储过程传入值
创建存储过程DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$ CREATE PROCEDURE 存储过程名称(IN 参数名 参数类型) -- 带参数的存储过程 BEGIN -- 开始编写存储过程 select(参数名) -- 传入参数的值:参数名 END $$ -- 存储过程结束调用存储过程:
CALL 存储过程名称(参数); -
方式3
变量赋值SET @变量名=值OUT 输出参数:表示存储过程向调用者传出值
OUT 变量名 数据类型创建存储过程
DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$ CREATE PROCEDURE 存储过程名称(IN 传入参数名 参数类型) -- 带参数的存储过程 BEGIN -- 开始编写存储过程 SET @返回变量名 = 传入参数名; SELECT @返回变量名; END $$ -- 存储过程结束调用存储过程
# 调用存储过程插入数据,获取返回值 CALL orders_proc(传入参数,@返回变量名);
四、MySQL触发器(了解)
1. 什么是触发器

- 简单理解: 当我们执行一条sql语句的时候,这条sql语句的执行会自动去触发执行其他的sql语句。
2. 触发器创建的四个要素
- 监视地点(table)
- 监视事件(insert/update/delete)
- 触发时间(before/after)
- 触发事件(insert/update/delete)
3. 创建触发器
delimiter $ -- 将Mysql的结束符号从 ; 改为 $,避免执行出现错误(和存储过程一样)
CREATE TRIGGER 触发器名-- 触发器名,在一个数据库中触发器名是唯一的
before/after(insert/update/delete) -- 触发的时机 和 监视的事件
on 触发器所在的表名-- 触发器所在的表
for each row -- 固定写法 叫做行触发器, 每一行受影响,触发事件都执行
begin
-- begin和end之间写触发事件
end
$ -- 结束标记