本蓝最近想处理一些出租车轨迹数据(本蓝纯小白一枚,希望大家多多指点,就当扶贫了),但是苦于数据量太大,2000w条,试了spss,origin都卡死了,我就寻思着试试python。今天花了很久,才实现了我想要的基础功能,下面和各位老铁们分享一下:
按照料辽北著名计算机学家刘小光先生提出的理论,任何数据处理之前都要经过读取环节,我个人比较喜欢用大熊猫读取:
import pandas as pd
import numpy as np
from pandas import DataFrame
fpath = "C:/Users/****/Desktop/文件/数据/****/1.txt"#打开神秘的文件
ratings = pd.read_csv(fpath,names=["id","date","jingdu","weidu"])#给每个列取个名字,经度纬度用拼音代替
ratings.head()#展示一下
得到结果如下:
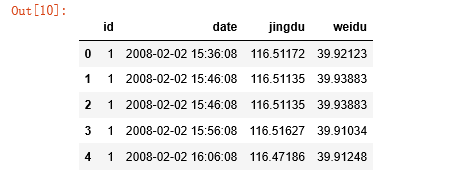
这里我把列名设置为id,date,jingdu,weidu,date列是年份+时间,这样会给接下来的数据处理造成麻烦,于是我以空格为分割符进行分割:
df=ratings["date"].str.split(' ',expand=True)#将date这行,以空格分割
df.head()
运行如下:
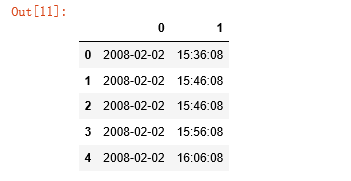
这里python没有经过朕的同意,就擅自将列命名为0,1。在下要重新为其命名,这样就显得我专业了,哈哈哈哈哈。
data=ratings.drop('date',axis=1).join(df)#将分割好的date加回母体
data.head()
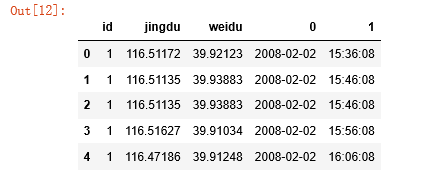
是不是发现和我说得不一样了,哈哈哈哈,晃你们一下~这一步是将被我重新分割的游子送回妈妈的怀抱。下面开始改名呢(data:天要下雨娘要嫁人,随她去吧):
data.rename(columns={
0:'date',1:'time'},inplace=True)#为0,1取名
data.head()
print(data.shape[0])#看看有几行
因为本蓝的gps数据有很多特别淘气的点,这些点我在地图上看都**干到俄罗斯去了,所以我要设置个阈值限制他们,其实这里应该是用算法来排除异常值,我为什么不写呢?因为我不会,等我学会再补上!
data1=pd.DataFrame(data)#转换为数据流为设定阈值做准备
data2=[]#创建空数组
n=0
for i in data['jingdu']:
if i > 116.5: #阈值
#print(data.loc[n])
data2.append(data.loc[n]) #将合格的宝贝加入新数组
n=n+1
好啦,这样就得到我们暂时想要的数据了,这为我今后的工作和学习奠定了良好的基础,并且激发了我浓厚的学习兴趣(实习报告每一天我都是这么写的,哈哈哈哈哈),最后一步,保存!
data3=pd.DataFrame(data2)
print(data3['jingdu'])#验证一哈
data3.to_csv(savePath, header=False, index=False, sep=',')#保存为csv文件
大功告成!乡村爱情12中,宋晓峰说,姐夫,你能不能脚踏实地的干活,别一天太飘!是啊,企者不立,跨者不行,我以前一直就是那种跨者——不行!所以,这次,我想做一个踏踏实实的人,一个文静的人,一个脱离了低级趣味的人!不畏艰难,只顾风雨兼程,就像乡村爱情11里宋晓峰说得:干马忠!干就完了!