终于看完了 … 

JMH是专门用于代码微基准测试的工具集
warmup可直译为预热的意思, 在JMH中, Warmup所做的就是在基准测试代码正式度量之前,先对其进行预热,使得代码的执行时经历了类的早期优化, JVM运行期编译,JIT优化之后的最终状态. 从而能够获得代码真实的性能数据.
measurement则是真正的度量工作,在每一轮的度量中,所有的度量数据会被纳入统计中(预热数据不会纳入统计之中)
所有基准测试方法都会被JMH根据方法名的字典顺序执行
-
设计全局的warmup和measurement
new OptionsBuilder() // 在真正的度量之前,首先对代码进行3个批次的热身,使代码的运行达到JVM已经优化的效果 .warmupIterations(3) // 度量的次数是5(这5次会纳入统计) .measurementIterations(5); -
在类或方法上使用@Measurement和@Warmup注解
@Measurement(iterations = 5) // 度量5个批次 @Warmup(iterations = 3) // 预热3个批次代码编程方式配置优先于注解方式
输出解释
// JVM的版本是1.93
# JMH 1.9.3 (released 1942 days ago, please consider updating!)
// 调用的虚拟机
# VM invoker: D:\app\jdk\jdk8\jre\bin\java.exe
// 虚拟机参数
# VM options: -javaagent:D:\app\IntelliJ IDEA 2019.2.4\lib\idea_rt.jar=61077:D:\app\IntelliJ IDEA 2019.2.4\bin -Dfile.encoding=UTF-8
// 热身5个批次 每一个批次都不断调用基准测试方法, 一个批次的执行时间是1秒
# Warmup: 5 iterations, 1 s each
// 度量10个批次 一次度量时长是1秒
# Measurement: 10 iterations, 1 s each
// 每一个批次超时时间
# Timeout: 10 min per iteration
// 执行基准测试的线程数量
# Threads: 1 thread, will synchronize iterations
// 基准测试的模式: 平均值时间 , 统计的是调用一次耗费的单位时间
# Benchmark mode: Average time, time/op
// 基准测试方法的绝对路径
# Benchmark: com.sixsixsix516.JMHExample01.arrayListAdd
// 执行进度
# Run progress: 0.00% complete, ETA 00:00:30
# Fork: 1 of 1
// 执行预热的5个批次 每批次平均执行了多少微秒
# Warmup Iteration 1: 0.015 us/op
# Warmup Iteration 2: 0.016 us/op
# Warmup Iteration 3: 0.015 us/op
# Warmup Iteration 4: 0.012 us/op
# Warmup Iteration 5: 0.022 us/op
// 10次度量的情况
Iteration 1: 0.020 us/op
Iteration 2: 0.014 us/op
Iteration 3: 0.012 us/op
Iteration 4: 0.011 us/op
Iteration 5: 0.012 us/op
Iteration 6: 0.019 us/op
Iteration 7: 0.012 us/op
Iteration 8: 0.010 us/op
Iteration 9: 0.011 us/op
Iteration 10: 0.010 us/op
// 最终统计结果
Result "arrayListAdd":
0.013 ��(99.9%) 0.005 us/op [Average]
// 最小,平均,最大 以及标准误差
(min, avg, max) = (0.010, 0.013, 0.020), stdev = 0.004
CI (99.9%): [0.008, 0.019] (assumes normal distribution)
四大BenchmarkMode
JMH使用@BeanchmarkMode这个注解来声明使用哪些模式(Model.All全部模式)运行
Mode.AverageTime 平均响应时间 用于输出基准测试方法每调一次所耗费的时间 也就是elapsed time/operation
Mode.Throughput 方法吞吐量 用于输出在单位时间内可以对该方法调用多少次
Mode.SampleTime 时间采样 以抽样的方式来统计基准测试方法的性能结果, 它会手机所有的性能数据,并且将其分布在不同区间内
Mode.SingleShotTime 用于冷测试 不论是Warmup还是Measurement 在每一个批次中基准测试方法只会被执行一次, 一般情况下,我们会将warmup的批次设置为0
BenchmarkMode既可以在class上进行注解设置,也可以在基准方法上进行注解设置,方法中设置的模式将会覆盖class注解上的设置,同样,在Options中也可以进行设置,它将会覆盖所有基准方法上的设置。
OutputTimeUnit
提供统计结果输出时的单位
可在方法,类上,Options中进行设置
三大State
- Thread独享State 每一个运行基准测试方法的线程都会持有一个独立的对象实例,该实例既可能是作为基准测试方法参数传入的,也可能是运行基准方法所在的宿主class,将state设置为Scope.Thread一般主要是针对非线程安全的类
// 每一个运行基准方法的线程都会有独立的对象实例
@State(Scope.Thread)
// 设置5个线程运行
@Threads(5)
- 多线程共享
@State(Scope.Benchmark)
- 线程组共享
@State(Scope.Group)
JMH的测试套件
-
@SetUp 在每一个基准测试方法执行前被调用, 常用于资源的初始化 , @TearDown 在基准测试方法执行之后调用,通常用于资源回收
@Setup(Level.Trial)默认配置 在所有批次前调用一次@Setup(Level.Iteration)每一个批次前执行@Setup(Level.Invocation)每一次度量调用一次
禁止JVM优化
@CompilerControl(CompilerControl.Mode.EXCLUDE)
编写正确的微基准测试
避免JVM优化 , 因为JVM优化后可能不是按照我们预想的真正代码执行,从而造成不准测量
-
避免DCE(Dead Code Elimination )
JVM擦去了一些上下文无关, 甚至经过计算确定压根不用到的代码, 最好每个基准方法都有返回值
-
使用black hole
将结果放入black hole中, 避免dead code的发生
@Benchmark public void testBlackHole() { Blackhole.consumeCPU(1 + 1); } -
避免变量的折叠 Constant Floding
以下代码会在JVM编译期间优化成一个值, 在运行期间不会计算
@Benchmark public double testConstantFloding(){ return x1 * x2; } -
避免循环展开
避免或减少在基准测试方法中出现循环
-
fork用于避免profile-guided optimizations
将fork设置为1,代表每一次运行基准测试时都会开辟一个全新的JVM进程对齐进行测试, 多个基准测试之间则不再受干扰
public static void main(String[] args) throws RunnerException {
Options build = new OptionsBuilder()
.include(ConcurrentHashMapBenchmark.class.getSimpleName())
// 设置每个批次的超时时间
.timeout(TimeValue.seconds(10))
.build();
new Runner(build).run();
}
Profiler
-
StackProfiler
可以输出线程堆栈信息, 统计程序在执行过程中的线程状态
public static void main(String[] args) throws RunnerException {
Options build = new OptionsBuilder()
.include(ConcurrentHashMapBenchmark.class.getSimpleName())
.addProfiler(StackProfiler.class)
.build();
new Runner(build).run();
}
-
GcProfiler
可用于分析出基准方法中垃圾回收器在JVM每个内存空间所花费的时间
public static void main(String[] args) throws RunnerException {
Options build = new OptionsBuilder()
.include(ConcurrentHashMapBenchmark.class.getSimpleName())
.addProfiler(GCProfiler.class)
.jvmArgsAppend("-Xmx128M")
.build();
new Runner(build).run();
}
-
ClassLoaderProfiler
可以看到基准方法的执行过程中有多少类被加载和卸载, 但是考虑到在一个类加载器中同一个类只会被加载一次的情况,因此我们需要将warmup设置为0,以避免在热身阶段就已经加载了基准测试方法所需的所有类
public static void main(String[] args) throws RunnerException {
Options build = new OptionsBuilder()
.include(ConcurrentHashMapBenchmark.class.getSimpleName())
.addProfiler(ClassloaderProfiler.class)
.warmupIterations(0)
.build();
new Runner(build).run();
}
-
CompilerProfiler
显示在代码执行过程中JIT编译器所花费的优化时间
public static void main(String[] args) throws RunnerException {
Options build = new OptionsBuilder()
.include(ConcurrentHashMapBenchmark.class.getSimpleName())
.addProfiler(CompilerProfiler.class)
// 观察更详细的输出
.verbosity(VerboseMode.EXTRA)
.build();
new Runner(build).run();
}
并发原子类型
AtomicInteger
原子类型是无锁的,线程安全的
基准性能测试
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.profile.StackProfiler;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.openjdk.jmh.runner.options.TimeValue;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @author sun 2020/9/13 20:38
*/
@Fork(1)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 10)
@Measurement(iterations = 10)
@BenchmarkMode(Mode.AverageTime)
public class SynchronizedVSLockVsAtomicInteger {
/**
* 线程组共享对象
*/
@State(Scope.Group)
public static class IntMonitor {
private int x;
private final Lock lock = new ReentrantLock();
/**
* 使用显示Lock进行共享资源同步
*/
void lockInc() {
lock.lock();
try {
x++;
} finally {
lock.unlock();
}
}
/**
* 使用synchronized关键字进行同步
*/
void synInc() {
synchronized (this) {
x++;
}
}
}
@State(Scope.Group)
public static class AtomicIntegerMonitor {
private AtomicInteger x = new AtomicInteger();
void inc() {
x.incrementAndGet();
}
}
@GroupThreads(10)
@Group("sync")
@Benchmark
public void syncInc(IntMonitor intMonitor) {
intMonitor.synInc();
}
@GroupThreads(10)
@Group("lock")
@Benchmark
public void locInc(IntMonitor intMonitor) {
intMonitor.lockInc();
}
@GroupThreads(10)
@Group("atomic")
@Benchmark
public void atomicIntegerInc(AtomicIntegerMonitor atomicIntegerMonitor) {
atomicIntegerMonitor.inc();
}
public static void main(String[] args) throws RunnerException {
Options option = new OptionsBuilder()
.include(SynchronizedVSLockVsAtomicInteger.class.getSimpleName())
.timeout(TimeValue.seconds(10))
.addProfiler(StackProfiler.class)
.build();
new Runner(option).run();
}
}
基本用法
- 创建
public static void main(String[] args) {
/// ============================ 创建 ================================
// 初始值为0
AtomicInteger atomicInteger = new AtomicInteger();
// 指定初始值
AtomicInteger atomicInteger1 = new AtomicInteger(10);
/// ============================ 增加操作 ================================
// 返回当前值, 然后自增
int value = atomicInteger.getAndIncrement();
// 先自增然后返回值
int value2 = atomicInteger.incrementAndGet();
// 返回当前值, 然后增加指定值
int andAdd = atomicInteger.getAndAdd(5);
// atomicInteger.addAndGet()
// 设置一个值
atomicInteger.set(10);
/// ============================ 减少操作 ================================
// 返回当前值, 然后进行自减
int value3 = atomicInteger.getAndDecrement();
// 自减后 返回当前值
int value4 = atomicInteger.decrementAndGet();
/// ============================ 更新操作 ================================
// expect为当前的值, update为更新后的值
boolean b = atomicInteger.compareAndSet(0, 10);
/// ============================ 函数式 ================================
// 使用函数式
int i1 = atomicInteger.updateAndGet((i) -> i + 100);
// atomicInteger1.getAndUpdate()
int i = atomicInteger.accumulateAndGet(20, Integer::sum);
//atomicInteger.getAndAccumulate()
}
AtomicInteger原理
// 源码
// Unsafe是由C++实现的, 内部存在大量汇编CPU指令等代码, JDK实现的lock free几乎完全依赖该类
private static final Unsafe unsafe = Unsafe.getUnsafe();
// 存放value内存地址偏移量
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) {
throw new Error(ex); }
}
// 具体值
private volatile int value;
compareAndSwapInt源码分析 - CAS算法
CAS包含3个操作数: 内存值V, 旧的预期值A, 要修改的新值B. 当且仅当预期值A与内存值V相等时,将内存值V修改为B,否则什么都不需要做
compareAndSwapInt方法是一个native方法, 提供了CAS算法的实现, AtomicInteger类中的原子性方法几乎都借助该方法实现
疑问 既然可以直接获取当前值, 那为什么还存在当前值与期待值不一致情况
AtomicInteger atomicInteger2 = new AtomicInteger(2);
atomicInteger2.compareAndSet(atomicInteger2.get(), 10);
原因 是相对于synchronized关键字, 显示锁lock, AtomicInteger所提供的方法不具备排他性, 当线程A通过get() 方法获取了AtomicInteger 的 value后, B线程对value的修改意见顺序完成, A线程试图再次修饰的时候就会出现exceptValue与value当前值不相等情况, 这种方法也被称为乐观锁. 对数据进行修改的时候, 首先需要进行比较
自旋方法 addAndGet
由于compareAndSwapInt乐观锁的特性 , 会存在数据修改失败的情况, 但是有些时候必须保证数据的更新是成功的,比如调用 incrementAndGet, addAndGet
// value 需要加的值
public final int getAndAddInt(Object atomicInteger, long valueOffset, int value) {
int nowValue;
do {
// 首先获取到当前的值
nowValue = this.getIntVolatile(atomicInteger, valueOffset);
}
// 不断尝试修改, 只有当前的值等于内存中的值时 才修改成功
while(!this.compareAndSwapInt(atomicInteger, valueOffset, nowValue, nowValue + value));
// 返回修改后的值
return nowValue;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nDPUWKk0-1600586240604)(…\img\getAndSet方法流程图.png)]
AtomicBoolean
提供原子性的读写布尔类型变量的解决方案
内部使用int存储, true是1 false是0
public static void main(String[] args) {
// 创建(默认false)
AtomicBoolean atomicBoolean = new AtomicBoolean();
// 指定值
AtomicBoolean atomicBoolean1 = new AtomicBoolean(true);
// 其他方式与AtomicInteger类似
}
一个可立即返回并且推出阻塞的显示锁lock
package com.sixsixsix516;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicBoolean;
/**
* 一个可立即返回并且推出阻塞的显示锁lock
*
* @author sun 2020/9/14 13:11
*/
public class TryLock {
private AtomicBoolean atomicBoolean = new AtomicBoolean(false);
private final ThreadLocal<Boolean> threadLocal = ThreadLocal.withInitial(() -> false);
private boolean tryLock() {
boolean result = atomicBoolean.compareAndSet(false, true);
if (result) {
threadLocal.set(true);
}
return result;
}
/**
* 锁的释放
*/
private boolean release() {
if (threadLocal.get()) {
threadLocal.set(false);
return atomicBoolean.compareAndSet(true, false);
}
return false;
}
private final static Object VAL_OBJ = new Object();
public static void main(String[] args) {
TryLock lock = new TryLock();
List<Object> validation = new ArrayList<>();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
while (true) {
try {
if (lock.tryLock()) {
System.out.println(Thread.currentThread().getName() + ": get lock");
if (validation.size() > 1) {
throw new IllegalStateException("validation failed");
}
validation.add(VAL_OBJ);
TimeUnit.MILLISECONDS.sleep(ThreadLocalRandom.current().nextInt(10));
} else {
TimeUnit.MILLISECONDS.sleep(ThreadLocalRandom.current().nextInt(10));
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (lock.release()) {
System.out.println(Thread.currentThread().getName() + ": release the lock");
validation.remove(VAL_OBJ);
}
}
}
}).start();
}
}
}
AtomicReference
对象的引用是一个4字节的数字, 代表着在JVM堆内存中的引用地址, 对一个4字节数字的读取操作和写入操作本身就是原子性的
- volatile 关键字保证了线程间的可见性,当某线程操作了被volatile关键字修饰的变量,其他线程可以立即看到该共享变量的变化
- CAS算法, 对比交换算法, 由UnSafe提供, 实质上是通过CPU指令来得到保证的, CAS算法提供了一种快速失败的方法,当某线程修改已经被改变数据时会快速失败
- 当CAS算法对共享数据操作失败时,因为有自旋算法的加持,我们对共享数据的更新终究会得到计算
原子类型用自旋+CAS的无锁操作保证了共享变量的线程安全性和原子性
AtomicStampedReference
在AtomicReference的基础上通过增加版本号解决了ABA问题
Atomic数组
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
AtomicFieldUpdater
原子性更新对象属性
- 未被volatile关键字修饰的属性无法被原子性的更新
- 类变量无法被原子性的更新
- 无法直接访问到的变量不能被原子性的更新
- final修饰的无法被原子性更新
- 父类成员无法被原子性更新
只有是自己的被volatile修饰且public 不被final修饰的变量
- AtomicIntegerFieldUpdater:原子性地更新对象的int类型属性,该属性无须被声明成AtomicInteger。
- AtomicLongFieldUpdater:原子性地更新对象的long类型属性,该属性无须被声明成AtomicLong。
- AtomicReferenceFieldUpdater:原子性地更新对象的引用类型属性,该属性无须被声明成AtomicReference。
public class AtomicIntegerFieldUpdaterTest {
public static class User {
volatile int age;
public int getAge() {
return age;
}
}
public static void main(String[] args) {
AtomicIntegerFieldUpdater<User> objectAtomicIntegerFieldUpdater = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
User user = new User();
objectAtomicIntegerFieldUpdater.addAndGet(user, 20);
System.out.println(user.getAge());
}
}
sun.misc.Unsafe
Unsafe可以直接操作内存, 甚至可以通过汇编指令直接进行CPU操作
// 获取unsafe
Field f = Unsafe.class.getDeclaredField("theUnsafe");
f.setAccessible(true);
Unsafe unsafe = (Unsafe) f.get(null);
System.out.println(unsafe);
-
绕过构造函数实例化对象
Object o = unsafe.allocateInstance(User.class); -
直接修改内存数据
User user = (User) unsafe.allocateInstance(User.class); unsafe.putInt(user, unsafe.objectFieldOffset(user.getClass().getDeclaredField("age")), 30); System.out.println(user);
并发工具类
CountDownLatch
当某项工作需要由若干项子任务并行的完成,并且只有在所有的子任务结束之后,当前主任务才能进行下一阶段
CountDownLatch直译为倒计数门阀, 它的作用是指有一个门阀在等待着倒计数,直到计数器为0的时候才能打开, 可以设置等待打开的时候指定超时时间
如果想要提高接口调用的响应速度可以将串行化的任务并行化处理
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
/**
* @author sun 2020/9/15 10:07
*/
public class CountDownLatchTest2 {
public static void main(String[] args) throws InterruptedException {
// 1.获得商品列表
List<Product> productList = IntStream.rangeClosed(1, 10).mapToObj(Product::new).collect(Collectors.toList());
// 2.分别进行计算
CountDownLatch countDownLatch = new CountDownLatch(productList.size());
productList.forEach(product ->
new Thread(() -> {
try {
// 模拟真正的业务操作
TimeUnit.MILLISECONDS.sleep(100);
product.setPrice(System.currentTimeMillis());
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 任务完成,计数器减1
countDownLatch.countDown();
}
}).start()
);
// 3.返回结果
// 主线程等待 直至任务全部完成
countDownLatch.await();
System.out.println(productList);
}
static class Product {
private int id;
private double price;
Product(int id) {
this.id = id;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public double getPrice() {
return price;
}
void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "Product{" +
"id=" + id +
", price=" + price +
'}';
}
}
}
其他方法
// 指定超时时间的等待
countDownLatch.await(10,TimeUnit.SECONDS);
// 返回当前计数器的值
long count = countDownLatch.getCount();
Cyclic Barrier(循环屏障)
允许多个线程在执行完相应的操作之后彼此等待共同到达一个障点(barrier point). CyclicBarrier也非常适合用于某个串行化任务被拆分为若干个并行执行的子任务, 它的功能比CountDownLatch多, 它可以被重复使用, 而CountDownLatch当计数器为0时将无法再使用
适合多次使用,多个任务同时到达一个点
示例
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
/**
* @author sun 2020/9/15 12:58
*/
public class CyclicBarrierTest2 {
public static void main(String[] args) throws BrokenBarrierException, InterruptedException {
CyclicBarrier barrier = new CyclicBarrier(11);
for (int i = 0; i < 10; i++) {
new Thread(new Tourist(i, barrier)).start();
}
barrier.await();
System.out.println("乘客全部上车了");
barrier.await();
System.out.println("乘客全部下车了");
}
private static class Tourist implements Runnable {
private final int touristId;
private final CyclicBarrier cyclicBarrier;
public Tourist(int touristId, CyclicBarrier cyclicBarrier) {
this.touristId = touristId;
this.cyclicBarrier = cyclicBarrier;
}
@Override
public void run() {
System.out.println("乘客" + touristId + "上车");
// 模拟乘客上车时间开销
spendSeveralSeconds();
// 上车后等待其他同伴上车
waitAndPrint("乘客" + touristId + " 等待其他人上车");
// 模拟乘客下车的时间开销
spendSeveralSeconds();
// 下车后等待其他同伴下车
waitAndPrint("乘客" + touristId + " 等待其他人下车");
}
private void waitAndPrint(String message) {
System.out.println(message);
try {
cyclicBarrier.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
private void spendSeveralSeconds() {
try {
TimeUnit.SECONDS.sleep(ThreadLocalRandom.current().nextInt(10));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
其他方法
// 指定切片数量创建对象
CyclicBarrier cyclicBarrier1 = new CyclicBarrier(1);
// 带runnable的参数
CyclicBarrier cyclicBarrier2 = new CyclicBarrier(1, () -> {
System.out.println("任务全部执行结束了 , 我被调用了....");
});
// 返回数量 , 一经创建无法修改
int parties = cyclicBarrier2.getParties();
// 调用后进入阻塞状态,等待其他线程执行完await方法后进入barrier point, 进而全部退出阻塞状态,当内部的count为0时,调用await()方法将直接返回,不再阻塞
cyclicBarrier2.await();
Exchanger(交换器)
exchanger简化了两个线程的数据交互,并且提供了两个线程之间的数据交换,Exchanger等待两个线程调用其exchanger方法,调用此方法时,交换机会交换两个线程提供给对方的数据
使用示例
public class ExchangerTest {
public static void main(String[] args) {
// 要交换的数据是String
Exchanger<String> exchanger = new Exchanger<>();
new Thread(() -> {
System.out.println("A线程启动");
// 模拟业务的执行
randomSleep();
try {
String receiveData = exchanger.exchange("我是A线程");
System.out.println("A线程收到数据: " + receiveData);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "A").start();
new Thread(() -> {
System.out.println("B线程启动");
// 模拟业务的执行
randomSleep();
try {
String receiveData = exchanger.exchange("我是B线程");
System.out.println("B线程启动收到数据: " + receiveData);
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "B").start();
}
private static void randomSleep() {
try {
TimeUnit.SECONDS.sleep(ThreadLocalRandom.current().nextInt(10));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
exchange方法是一个阻塞方法,当两个线程都调用了才会停止阻塞,执行下去
其他方法
// 数据交换方法,该方法的作用是将数据x交换至搭档线程,执行该方法后,当前线程会进入阻塞状态,只有当搭档线程也执行了exchange方法之后,该当前线程才会退出阻塞状态进行下一步的工作,与此同时,该方法的返回值代表着搭档线程所传递过来的交换数据。,
exchanger.exchange("A");
// 数据交换方法 增加超时功能,超时了则返回null
exchanger.exchange("A",10,TimeUnit.SECONDS);
Exchanger在类似于生产者-消费者的情况下可能会非常有用。在生产者-消费者问题中,拥有一个公共的数据缓冲区(队列)、一个或多个数据生产者和一个或多个数据消费者。由于交换器类只涉及两个线程,因此如果你想要在两个线程之间同步数据或者交换数据,那么这种情况就可以使用Exchanger这个工具,当然在使用它的时候请务必做好线程的管理工作,否则将会出现线程阻塞,程序无法继续执行的假死情况。
Semaphore 信号量
用于同一时刻允许多个线程对共享资源进行并行操作的场景
示例
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
import java.util.stream.IntStream;
/**
* @author sun 2020/9/15 15:04
*/
public class SemaphoreTest {
public static void main(String[] args) {
// 最大允许同时在线人数
final int MAX_PERSON_LOGIN_COUNT = 10;
LoginService loginService = new LoginService(MAX_PERSON_LOGIN_COUNT);
IntStream.rangeClosed(0, 200).forEach(i ->
new Thread(() -> {
boolean login = loginService.login();
if (!login) {
System.out.println("登录失败,超过最大同时登录人数");
return;
}
try {
// 模拟业务操作
try {
TimeUnit.MILLISECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
loginService.logout();
}
}, "User-" + i).start()
);
}
private static class LoginService {
private final Semaphore semaphore;
LoginService(int maxPersonLoginCount) {
this.semaphore = new Semaphore(maxPersonLoginCount);
}
boolean login() {
// 获取许可证
boolean login = semaphore.tryAcquire();
if (login) {
System.out.println(Thread.currentThread().getName() + "登录成功");
}
return login;
}
public void logout() {
// 释放许可证
semaphore.release();
System.out.println(Thread.currentThread().getName() + "退出登录");
}
}
}
其他方法
- boolean isFair():对Semaphore许可证的争抢采用公平还是非公平的方式,对应到内部的实现类为FairSync(公平)和NonfairSync(非公平)。
- int availablePermits():当前的Semaphore还有多少个可用的许可证。
- int drainPermits():排干Semaphore的所有许可证,以后的线程将无法获取到许可证,已经获取到许可证的线程将不受影响。▪
- boolean hasQueuedThreads():当前是否有线程由于要获取Semaphore许可证而进入阻塞?(该值为预估值。)▪
- int getQueueLength():如果有线程由于获取Semaphore许可证而进入阻塞,那么它们的个数是多少呢?(该值为预估值)
Phaser 阶段器
用于解决控制多个线程分阶段共同完成任务的情景问题
使用实例
import java.util.Date;
import java.util.concurrent.Phaser;
import java.util.concurrent.TimeUnit;
import static java.lang.Thread.currentThread;
import static java.util.concurrent.ThreadLocalRandom.current;
/**
* @author sun 2020/9/15 20:04
*/
public class PhaserTest {
public static void main(String[] args) throws InterruptedException {
// 1.定义一个Phaser,并未指定分片数量parties,此时在Phaser内部分片的数量parties默认为0,后面可以通过register方法动态增加
final Phaser phaser = new Phaser();
// 定义10个线程
for (int i = 0; i < 10; i++) {
new Thread(() -> {
// 2.首先调用phaser的register方法使得phaser内部的parties加一
phaser.register();
try {
// 采取随机休眠的方式模拟线程的运行时间开销
TimeUnit.SECONDS.sleep(current().nextInt(20));
// 3.线程任务结束,执行arrive方法
phaser.arrive();
System.out.println(new Date() + ":" + currentThread() + " completed the work.");
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "T-" + i).start();
}
TimeUnit.SECONDS.sleep(10);
// 4.主线程也调用注册方法,此时parties的数量为11=10+1
phaser.register();
// 5.主线程也arrive,但是它要等待下一个阶段,等待下一个阶段的前提是所有的线程都arrive,也就是phaser内部当前phase的unarrived数量为0
phaser.arriveAndAwaitAdvance();
// 通过下面的assertion就可以断言我们上面的判断
assert phaser.getRegisteredParties() == 11 : "total 11 parties is registered.";
System.out.println(new Date() + ": all of sub task completed work.");
}
}
其他方法
-
register方法
为Phaser新增一个未到达的分片,并且返回Phase(阶段)的编号,该编号与Phaser当前的Phase编号数字一样, 但是调用该方法时,有些时候回陷入阻塞之中,比如前一个Phase阶段在执行onAdvance方法时耗时较长,那么此时若有一个新的分片想要通过register方法加入到phaser中就会陷入阻塞
-
bulkRegister方法
允许注册0个与多个分片(Parties)到Phaser.
-
arrive和arriveAndAwaitAdvance
都是到达Phaser的下一个Phase阶段,前者不会等待其他分片(part),后者则会等待所有未到达的分片到达
区别
- arrive方法返回的阶段编号为当前的阶段编号
- arriveAndAwaitAdvance 返回下一个阶段编号
-
arriveAndDeregister方法
到达下一个阶段后将当前Phaser的分区partie数量减少一个. 该方法返回当前阶段的编号,如为负则当前phaser已被销毁
-
awaitAdvance(int phase)
等待与Phaser关联的分片都到达某个指定的Phase编号,如果某个分片任务未到达,那么该方法会进入阻塞状态,这有点类似于CountDownLatch的await方法,该方法无法被中断
-
awaitAdvanceInterruptibly(int phase)
与awaitAdvance一致,但增加了可中断功能
-
awaitAdvanceInterruptibly(int phase, long timeout, TimeUnit unit)
在 awaitAdvanceInterruptibly(int phase) 基础上增加了超时功能
Lock
Lock接口是对锁操作方法的一个基本定义,它提供了synchronized关键字所具备的全部功能方法,另外我们可以借助于Lock创建不同的Condition对象进行多线程间的通信操作,与关键字synchronized进行方法同步代码块同步的方式不同,
主要方法
-
lock() 尝试获取锁,如果此刻该锁未被其他线程持有,则会立即返回,并且设置锁的hold计数为1;如果当前线程已经持有该锁则会再次尝试申请,hold计数将会增加一个,并且立即返回;如果该锁当前被另外一个线程持有,那么当前线程会进入阻塞,直到获取该锁,由于调用lock方法而进入阻塞状态的线程同样不会被中断,这一点与进入synchronized同步方法或者代码块被阻塞类似。
-
lockInterruptibly()
该方法与前者类似, 但可中断
-
tryLock()
不会阻塞获取锁,如果失败则直接返回false
-
unlock()
释放锁
-
newCondition
创建一个与该lock相关联的Condition对象
ReentrantLock
重入(多次获取)锁
-
getHoldCount
查询当前线程在某个Lock上的数量,如果当前线程成功获得了lock,则该值大于等于1,否则0
-
isHeldByCurrentThread
判断当前线程是否持有某个Lock,由于Lock的排他性,因此在某个时刻只有一个线程调用该方法返回true
-
isLocked
判断Lock是否已经被线程持有
-
isFair
创建的ReentrantLock是否为公平锁
-
hasQueuedThreads()方法:在多个线程试图获取Lock的时候,只有一个线程能够正常获得,其他线程可能(如果使用tryLock()方法失败则不会进入阻塞)会进入阻塞,该方法的作用就是查询是否有线程正在等待获取锁。
-
hasQueuedThread(Thread thread)方法:在等待获取锁的线程中是否包含某个指定的线程。
-
getQueueLength()方法:返回当前有多少个线程正在等待获取锁。
正确使用Lock
-
确保锁的释放
public static void main(String[] args) { Lock lock = new ReentrantLock(); // 获取锁 lock.lock(); try { // 执行业务逻辑 } finally { lock.unlock(); } } -
避免锁的交叉引起死锁
-
多个原子性方法的组合不能确保原子性
ReentrantReadWriteLock
第共享资源的操作一般分为两种类型 读和写, 多个线程的读并不会存在线程安全问题,所以多线程读之间不应该互斥
读写锁: 允许某个特定时刻多线程并发读取共享资源,提高系统性能和访问吞吐量
读锁之间不互斥,不同锁与写锁之间互斥
import java.util.LinkedList;
import java.util.List;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* @author sun 2020/9/16 16:50
*/
public class ReentrantReadWriteLockTest {
/**
* 定义读写锁
*/
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
/**
* 创建读锁
*/
private final Lock readLock = readWriteLock.readLock();
/**
* 创建写锁
*/
private final Lock writeLock = readWriteLock.writeLock();
private final List<String> list = new LinkedList<>();
/**
* 使用写锁进行数据同步
*/
public void add(String element) {
writeLock.lock();
try {
list.add(element);
} finally {
writeLock.unlock();
}
}
/**
* 使用读写进行数据同步
*/
public String take(int index) {
readLock.lock();
try {
return list.get(index);
} finally {
readLock.unlock();
}
}
}
Condition
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import static java.util.concurrent.ThreadLocalRandom.current;
/**
* @author sun 2020/9/16 17:48
*/
public class ConditionTest {
/**
* 共享数据
*/
private static int shareData = 0;
/**
* 标识共享数据是否被使用
*/
private static boolean dataUsed = false;
/**
* 创建显示锁
*/
private static Lock lock = new ReentrantLock();
/**
* 使用显示锁创建Condition
*/
private static Condition condition = lock.newCondition();
/**
* 对数据的写操作
*/
private static void change() {
// 获取锁,如果当前锁被其他线程持有,则当前线程会进入阻塞
lock.lock();
try {
// ②如果当前数据未被使用,则当前线程将进入wait队列,并且释放lock
while (!dataUsed) {
condition.await();
}
// 修改数据,并且将dataUsed状态标识为false
TimeUnit.SECONDS.sleep(current().nextInt(5));
shareData++;
dataUsed = false;
System.out.println("produce the new value: " + shareData);
// ③ 通知并唤醒在wait队列中的其他线程——数据使用线程
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放锁
lock.unlock();
}
}
// 对数据进行使用
private static void use() {
// 获取锁,如果当前锁被其他线程持有,则当前线程会进入阻塞
lock.lock();
try {
// ④ 如果当前数据已经使用,则当前线程将进入wait队列,并且释放lock
while (dataUsed) {
condition.await();
}
// 使用数据,并且将dataUsed状态标识置为true
TimeUnit.SECONDS.sleep(current().nextInt(5));
dataUsed = true;
System.out.println("the shared data changed: " + shareData);
// ⑤通知并唤醒wait队列中的其他线程——数据修改线程
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放锁
lock.unlock();
}
}
public static void main(String[] args) {
// 创建并启动两个匿名线程
new Thread(() -> {
while (true){
change();
}
}, "Producer").start();
new Thread(() -> {
while (true){
use();
}
}, "Consumer").start();
}
}
StampedLock
饥饿写问题: 读线程数量远远大于写线程的数量,导致长时间锁被读线程占有, 写线程无法获得对数据的操作权限从而进入饥饿状态(可以在构造器构造读写锁时指定为公平锁,读写线程获得执行权限得到的机会相对公平,但是当读线程大于写线程时,性能效率会比较低下),所以在使用读写锁的时候要评估好线程的数量
StampedLock 由一个Long型的数据戳(stamp)和三种模型构成, 当获取锁(比如调用readLock(),writeLock())时会返回一个long型的时间戳(stamp), 该数据戳将被用于进行稍后的锁释放参数,如果返回0(比如调用tryWriteLock), 则表示锁获取失败, StampLock是不可重入的,
StampedLock的引入并不是要横扫锁的世界成为“武林至尊”,它更多地是提供了一种乐观读的方式供我们选择,同时又解决了读写锁中“饥饿写”的问题。作为开发人员要能够根据应用程序的特点来判断应该采用怎样的锁进行贡献资源数据的同步,以确保数据的一致性,如果你无法明确地了解读写线程的分布情况,那么请使用ReentrantLock,因为通过本节所做的基准测试不难发现,它的表现始终非常稳定,无论是读线程还是写线程。如果你的应用程序中,读操作远远多于写操作,那么为了提高数据读取的并发量,StampedLock的乐观读将是一个不错的选择,同时它又不会引起饥饿写的问题。
并发容器
链表
链表是线性表的链式存储方式,链表不是连续的内存存储结构
在链表的每一个节点中,至少包含着两个基本属性: 数据本身与指向下一个节点的引用或指针
BlockingQueue 阻塞队列
当队列已满时(队列元素数量达到了最大容量的临界值),对队列的写入操作将会被阻塞挂起
当队列为空时(队列元素到达了0的临界值) 对队列的读操作线程将被阻塞挂起
BlockingQueue的内部实现主要依赖于显示锁lock及与其关联的Condition对象,所以这些实现类都是线程安全的,可以直接使用
ArrayBlockingQueue
基于数组结构实现的FIFO(先进先出)阻塞队列,在构造该阻塞队列时需要指定队列中最大元素的数量
public static void main(String[] args) throws InterruptedException {
ArrayBlockingQueue<Integer> arrayBlockingQueue = new ArrayBlockingQueue<>(2);
///=== 阻塞 写 ======
// 向队列尾部加入元素,如果满了则阻塞,知道有其他线程进行消费或对其进行中断
arrayBlockingQueue.put(1);
// 向尾部添加元素,如果容器已满,则在指定时间内阻塞,时间到后返回false代表元素加入失败
boolean offer = arrayBlockingQueue.offer(2, 10, TimeUnit.SECONDS);
///=== 非阻塞 写 ===
// 向尾部添加一个数据, 当容器满时抛出异常
arrayBlockingQueue.add(1);
// 向尾部添加一个数据, 当容器满时立即返回false
arrayBlockingQueue.offer(1);
///=== 阻塞 读 =====
// 从头部获取数据并移除,当容器空时阻塞,知道其他线程添加数据,或被中断
Integer take = arrayBlockingQueue.take();
// 从头部获取数据并移除,当容器为空时 指定时间内 如果还是获取不到则返回null
arrayBlockingQueue.poll(1, TimeUnit.MILLISECONDS);
=== 非阻塞 读 ====
// 从头部获取数据并移除,当容器为空时 返回null
Integer poll = arrayBlockingQueue.poll();
// 从头部获取数据,如果容器为空则返回null
Integer peek = arrayBlockingQueue.peek();
}
PriorityBlockingQueue 优先级阻塞队列
是一个无边界的阻塞队列,该队列会根据某种规则对插入队列尾部的元素进行排序
特点
- 理论上 PriorityBlockingQueue存放数据的数量是无边界的, 内部维护了一个Object的数组,随着数据的增加会动态扩容
public static void main(String[] args) {
// 指定初始容量,空构造器的默认初始容量是11,泛型必须是Comparable接口子类,否则抛出类型转换异常
PriorityBlockingQueue<Integer> priorityBlockingQueue = new PriorityBlockingQueue(10);
// 不存在阻塞写方法,因为priorityBlockingQueue是无边界的,添加方法都会自动排序一遍
// add, offer, put
// 不存在阻塞读方法 无边界
}
LinkedBlockingQueue
可选边界基于链表实现的FIFO队列
public static void main(String[] args) {
// 默认无参构造器是无边界
// 指定边界的方式创建
LinkedBlockingQueue<Integer> integerLinkedBlockingQueue = new LinkedBlockingQueue<>(10);
// 其他方法与ArrayBlokcingQueue类似
}
DelayQueue
无边界阻塞队列, 容器内的元素会被延迟单位后消费, 元素按照过期时间排序, 快要过期的元素在前面
容器内的元素类型必须实现Delayed接口的子类 需要重写getDelay方法用于计算距离过期时间
import java.util.concurrent.Delayed;
import java.util.concurrent.TimeUnit;
/**
* @author sun 2020/9/17 16:28
*/
public class MessageDelay implements Delayed {
/**
* 元素数据的内容
*/
private final String message;
/**
* 用于计算失效的时间(单位秒)
*/
private final long time;
public MessageDelay(String message, long second) {
this.message = message;
this.time = second + System.currentTimeMillis() / 1000;
System.out.println(time);
}
@Override
public long getDelay(TimeUnit unit) {
long convert = unit.convert(time - System.currentTimeMillis() / 1000, TimeUnit.SECONDS);
System.out.println("转换的时间: " + convert);
return convert;
}
@Override
public int compareTo(Delayed o) {
return Long.compare(this.time, ((MessageDelay) o).getTime());
}
public long getTime() {
return time;
}
@Override
public String toString() {
return "MessageDelay{" +
"message='" + message + '\'' +
", time=" + time +
'}';
}
}
public static void main(String[] args) throws InterruptedException {
DelayQueue<MessageDelay> delayQueue = new DelayQueue<>();
// 1秒后过期
delayQueue.put(new MessageDelay("data1", 2));
// 3秒后过期
delayQueue.put(new MessageDelay("data2", 5));
// 非阻塞读方法,时间未到则立即返回null
MessageDelay poll = delayQueue.poll();
// 阻塞读方法, 时间未到则一直阻塞
MessageDelay take = delayQueue.take();
// 其他方法与ArrayBlockingQueue类似
System.out.println();
}
SynchronousQueue
尽管SynchronousQueue是一个队列,但是它的主要作用在于在两个线程之间进行数据交换,区别于Exchanger的主要地方在于(站在使用的角度)SynchronousQueue所涉及的一对线程一个更加专注于数据的生产,另一个更加专注于数据的消费(各司其职),而Exchanger则更加强调一对线程数据的交换。
public class SynchronousQueueTest {
public static void main(String[] args) {
// 定义String类型的SynchronousQueue
SynchronousQueue<String> queue = new SynchronousQueue<>();
// 启动两个线程,向queue中写入数据
IntStream.rangeClosed(0, 1).forEach(i ->
new Thread(() -> {
try {
// 若没有对应的数据消费线程,则put方法将会导致当前线程进入阻塞
queue.put(currentThread().getName());
System.out.println(currentThread() + " put element " + currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start());
// 启动两个线程从queue中消费数据
IntStream.rangeClosed(0, 1).forEach(i ->
new Thread(() -> {
try {
// 若没有对应的数据生产线程,则take方法将会导致当前线程进入阻塞
String value = queue.take();
System.out.println(currentThread() + " take " + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start()
);
}
}
LinkedBlockingDeque
LinkedBlockingDeque是一个基于链表实现的双向(Double Ended Queue,Deque)阻塞队列,双向队列支持在队尾写入数据,读取移除数据;在队头写入数据,读取移除数据。LinkedBlockingDeque实现自BlockingDeque(BlockingDeque又是BlockingQueue的子接口),并且支持可选“边界”,与LinkedBlockingQueue一样,对边界的指定在构造LinkedBlockingDeque时就已经确定
https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/LinkedBlockingDeque.html
LinkedTransferQueue
无界队列 先进先出
A线程调用transfer方法将数据添加到尾部并开始阻塞直至有线程消费(poll,take)这个数据
public class TransferQueueTest {
public static void main(String[] args) throws InterruptedException {
// 定义LinkedTransferQueue
LinkedTransferQueue<String> queue = new LinkedTransferQueue<>();
// 通过不同的方法在队列尾部插入三个数据元素
queue.add("hello");
queue.offer("world");
queue.put("Java");
// 此时该队列的数据元素为(队尾)Java->world->hello
new Thread(() -> {
try {
// 创建匿名线程,并且执行transfer方法
queue.transfer("Alex");
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("current thread exit.");
}).start();
// 此刻队列的数据元素为(队尾)Alex->Java->world->hello
TimeUnit.SECONDS.sleep(2);
// 执行take方法从队列头部移除消费元素hello,但是匿名线程仍旧被阻塞
System.out.println(queue.take());
// 在队尾插入新的数据元素(队尾)Scala->Alex->Java->world
queue.put("Scala");
// 执行poll方法从队列头部移除消费元素world,匿名线程继续被阻塞
System.out.println(queue.poll());
// 执行take方法从队列头部移除消费元素Java,匿名线程继续阻塞中
System.out.println(queue.take());
// 执行take方法从队列头部移除消费元素Alex,匿名线程退出阻塞
System.out.println(queue.take());
}
}
BlockingQueue总揽

ConcurrentQueue 并发队列
不用关心临界值的判断, 操作该队列的线程不会被挂起并且等待被其他线程唤醒,并且是线程安全的
public static void main(String[] args) {
// 无锁,线程安全的, 性能高效的, 基于链表结构实现的FIFO 单向队列
ConcurrentLinkedQueue<Integer> concurrentLinkedQueue = new ConcurrentLinkedQueue<>();
// 无锁,线程安全的, 性能高效的, 基于链表结构实现的FIFO 双向队列
ConcurrentLinkedDeque<Integer> concurrentLinkedDeque = new ConcurrentLinkedDeque<>();
}
并发队列使用中需注意
-
避免使用size()方法 由于链表结构的特性, 获取元素个数时需要从头到尾遍历一遍从而影响性能
由于并发队列无锁的特点,所以在线程遍历获取size时可能由于其他线程的操作导致当前遍历得到的结果不准确
-
存在内存泄露问题
内存泄露: 内存无法被回收
解决方法: 使用 ConcurrentHashSet 替代
ConcurrentMap 并发映射
ConcurrentHashMap
concurrentHashMap内部由多个segment(默认16个)组成, 每一个segment锁对象均可用于同步每个散列映射表的若干个桶(HashBuket)
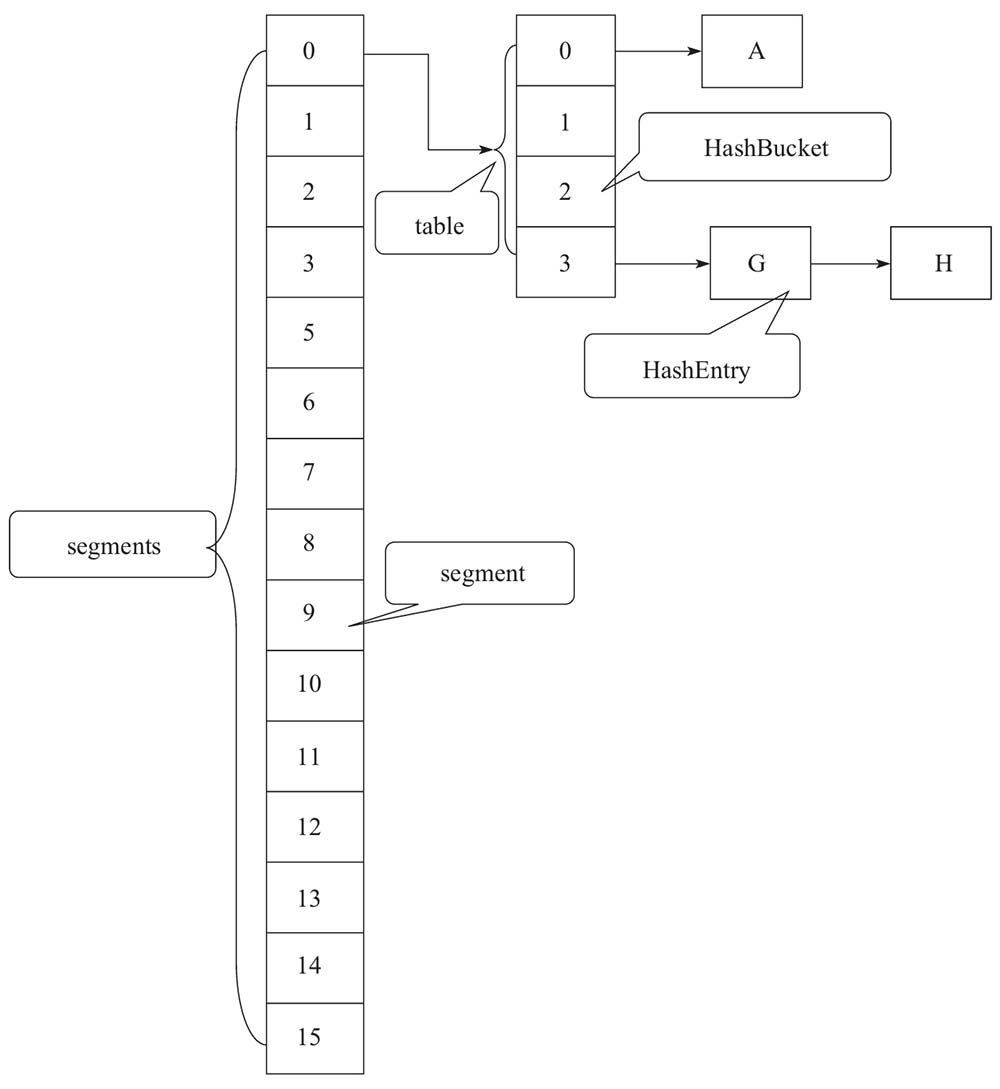
segment可用于减小锁的粒度, ConcurrentHashMap被分隔成若干个segment, 在put的时候只需要锁住一个segment,而get的时候不加锁,而使用volatile属性已保证被其他线程同步修改后的可见性
在Java的实现中采用数组+链表+红黑树的实现方式

ConcurrentSkipListMap
线程安全的并发访问的排序映射表,内部是SkipList(跳表), 增删改查的时间复杂度是O(log(n))
优点:
-
key有序
-
ConcurrentSkipListMap支持更高的并发,ConcurrentSkipListMap的存取时间复杂度是O(log(n)),与线程数几乎无关,也就是说,在数据量一定的情况下,并发的线程越多,ConcurrentSkipListMap越能体现出它的优势
CopyOnWrite 写时拷贝算法
简称COW, 读时不加锁, 写时加锁, 写的过程是将原来的数据拷贝一份,在拷贝的数据中进行修改,修改完后再把最新的设置回去
这是一种读写分离的思想, 读和写使用的是不同的容器, 不会存在读写冲突, 这个容器常常被用于 读操作远远高于写操作并且对数据实时性不严格的场景
Java5引入的两个实现类
- CopyOnWriteArrayList
- CopyOnWriteArraySet
缺点:
- 数据一致性问题
- 数组复制的内存开销
Executor包
ThreadPoolExecutor
构造方法
- corePoolSize 用于指定在线程池中维护的核心线程数量,即使当前线程中的核心线程不工作, 核心线程的数量也不会减少
- maximumPoolSize 用于设置线程池中允许的线程数量的最大值
- keepAliveTime 当线程中的线程数量超过核心线程数并且处于空闲时, 线程池将回收一部分线程让退出系统资源,该参数可用于设置超过coreSize数量的线程在多长时间后被回收
- TimeUnit 用于设定keepAliveTime的时间
- workQueue 用于存放已提交至线程池但未被执行的任务
- ThreadFactory 用于创建线程的工厂
- RejectedExecutionHandler 当任务数量超过阻塞列边界时, 这时候线程池就会拒绝添加新的任务, 该参数设置拒绝策略
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
10,
20,
1, TimeUnit.MINUTES,
new ArrayBlockingQueue<Runnable>(10),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardPolicy()
);
}
线程池成功构造后, 其内部的线程并不会立即被创建, 而是首次调用执行任务的时候才会创建
当线程池中的活跃(工作)线程大于等于核心线程数量并且任务队列未满时,任务队列中的任务不会立即执行,而是等待工作线程空闲时轮询任务队列以获取任务。
当任务队列已满且工作线程小于最大线程数量时,线程池会创建线程执行任务,但是线程数量不会超过最大线程数,
当任务队列已满且线程池中的工作线程达到最大线程数量,并且此刻没有空闲的工作线程时,会执行任务拒绝策略,任务将以何种方式被拒绝完全取决于构造ThreadExecutorPool时指定的拒绝策略。若将执行任务的循环最大次数更改为15,再次执行时会发现只有14个任务被执行,第15个任务被丢弃(这里指定的拒绝策略为丢弃)。
若线程池中的线程是空闲的且空闲时间达到指定的keepAliveTime时间,线程会被线程池回收(最多保留corePoolSize数量个线程),当然如果设置允许线程池中的核心线程超时,那么线程池中所有的工作线程都会被回收。
ThreadFactory
用于定义线程池中的线程, 可以指定线程的命名规则, 优先级, 是否为守护线程等
public class MyThreadFactory implements ThreadFactory {
private final String PREFIX = "SUN";
private final AtomicInteger atomicInteger = new AtomicInteger();
@Override
public Thread newThread(Runnable r) {
ThreadGroup threadGroup = new ThreadGroup("order");
Thread thread = new Thread(threadGroup, r, PREFIX + atomicInteger.incrementAndGet());
// 线程优先级
thread.setPriority(10);
return thread;
}
}
拒绝策略
new ThreadPoolExecutor.DiscardPolicy()丢弃策略, 任务会被直接无视丢弃而等不到执行AbortPolicy中止策略 抛出运行时异常DiscardOldestPolicy丢弃任务队列中最老任务CallerRunsPolicy不丢弃任务 在当前线程阻塞的完成
关闭
- 有序关闭(shutdown)shutdown提供了一种有序关闭ExecutorService的方式,当该方法被执行后新的任务提交将会被拒绝,但是工作线程正在执行的任务以及线程池任务(阻塞)队列中已经被提交的任务还是会执行,当所有的提交任务都完成后线程池中的工作线程才会销毁进而达到ExecutorService最终被关闭的目的。
- 立即关闭(shutdownNow)shutdownNow方法首先会将线程池状态修改为shutdown状态,然后将未被执行的任务挂起并从任务队列中排干,其次会尝试中断正在进行任务处理的工作线程,最后返回未被执行的任务,当然,对一个执行了shutdownNow的线程池提交新的任务同样会被拒绝。
- 组合关闭(shutdown&shutdownNow)通常情况下,为了确保线程池被尽可能安全地关闭,我们会采用两种关闭线程池的组合方式,以尽可能确保正在运行的任务被正常执行的同时又能提高线程池被关闭的成功率。
Executors的工厂方法
// 固定线程数量,任务队列是无边界的
ExecutorService executorService = Executors.newFixedThreadPool(3);
// 创建只有一个工作线程的线程池
ExecutorService executorService1 = Executors.newSingleThreadExecutor();
// 缓存线程池 通常用于提高执行量大, 耗时短, 异步任务程序
ExecutorService executorService2 = Executors.newCachedThreadPool();
// 创建调度线程
ScheduledExecutorService scheduledExecutorService1 = Executors.newScheduledThreadPool(10);
// 并发度等于CPU核数
ExecutorService executorService3 = Executors.newWorkStealingPool();
Future
Future代表未来的结果
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newSingleThreadExecutor();
Future<String> submit = executorService.submit(() -> {
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "result";
});
System.out.println("todo something");
System.out.println("返回值: " + submit.get());
System.out.println("todo something2");
}
Callback
与Runnable接口非常类似, 解决Runnable接口无返回值问题
运行执行错误
Runnable类型的任务中,如果出现错误只能被运行它的线程捕获, 运行它的主线程很难获取到运行时出现的异常
而future则是通过get方法异常方式来获取异步任务的异常
Fork/Join Framework
旨在充分利用多核CPU, 将一个复杂任务拆分(fork)成若干个并行计算, 然后将结果合并, 分而治之思想
无论是RecursiveTask还是RecursiveAction,对任务的拆分与合并都是在compute方法中进行的,可见该方法的职责(fork,join,计算)太重,不够单一,且可测试性比较差,因此在Java 8版本中提供了接口Spliterator,其对任务的拆分有了进一步的高度抽象
RecurciveTask
RecursiveTask任务类型除了进行子任务的运算之外,还会将最终子任务的计算结果返回,下面通过一个简单的实例来认识一下RecursiveTask。该示例通过高并发多线程的方式计算一个数组中所有元素之和,数组会被拆分成若干分片,每一个异步任务都会计算对应分片元素之和,最后所有的子任务结果会被join在一起作为最终的结果返回。示例代码如下:
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
import java.util.stream.LongStream;
/**
* @author sun 2020/9/20 11:09
*/
public class RecursiveTest extends RecursiveTask<Long> {
private final long[] numbers;
private final int startIndex;
private final int endIndex;
/**
* 每个子任务运算的最多元素数量
*/
private static final long THRESHOLD = 10_000L;
private RecursiveTest(long[] numbers) {
this(numbers, 0, numbers.length);
}
private RecursiveTest(long[] numbers, int startIndex,
int endIndex) {
this.numbers = numbers;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
protected Long compute() {
int length = endIndex - startIndex;
// 当元素数量少于等于 THRESHOLD时,任务将不必再拆分
if (length <= THRESHOLD) {
// 直接计算
long result = 0L;
for (int i = startIndex; i < endIndex; i++) {
result += numbers[i];
}
return result;
}
// 拆分任务(一分为二,被拆分后的任务有可能还会被拆分:递归)
int tempEndIndex = startIndex + length / 2;
// 第一个子任务
RecursiveTest firstTask = new RecursiveTest(numbers, startIndex, tempEndIndex);
// 异步执行第一个被拆分的子任务(子任务有可能还会被拆,这将取决于元素数量)
firstTask.fork();
// 拆分第二个子任务
RecursiveTest secondTask = new RecursiveTest(numbers, tempEndIndex, endIndex);
// 异步执行第二个被拆分的子任务(子任务有可能还会被拆,这将取决于元素数量)
secondTask.fork();
// join等待子任务的运算结果
Long secondTaskResult = secondTask.join();
Long firstTaskResult = firstTask.join();
// 将子任务的结果相加然后返回
return (secondTaskResult + firstTaskResult);
}
public static void main(String[] args) {
// 创建一个数组
long[] numbers = LongStream.rangeClosed(1, 9_000_000).toArray();
// 定义RecursiveTask
RecursiveTest forkJoinSum = new RecursiveTest(numbers);
// 创建ForkJoinPool并提交执行RecursiveTask
Long sum = ForkJoinPool.commonPool().invoke(forkJoinSum);
// 输出结果
System.out.println(sum);
// validation result验证结果的正确性
assert sum == LongStream.rangeClosed(1, 9_000_000).sum();
}
}
RecurciveAction
RecursiveAction类型的任务与RecursiveTask比较类似,只不过它更关注于子任务是否运行结束,下面来看一个将数组中的每一个元素并行增加10倍(每一个数字元素都将乘10)的例子,该示例使用RecursiveAction任务的方式来实现。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import static java.util.concurrent.ThreadLocalRandom.current;
/**
* @author sun 2020/9/20 11:21
*/
public class RecursiveActionTest extends RecursiveAction {
private List<Integer> numbers;
// 每个任务最多进行10个元素的计算
private static final int THRESHOLD = 10;
private int start;
private int end;
private int factor;
private RecursiveActionTest(List<Integer> numbers, int start, int end, int factor) {
this.numbers = numbers;
this.start = start;
this.end = end;
this.factor = factor;
}
@Override
protected void compute() {
// 直接计算
if (end - start < THRESHOLD) {
computeDirectly();
} else {
// 拆分
int middle = (end + start) / 2;
RecursiveActionTest taskOne =
new RecursiveActionTest(numbers, start, middle, factor);
RecursiveActionTest taskTwo =
new RecursiveActionTest(numbers, middle, end, factor);
invokeAll(taskOne, taskTwo);
}
}
private void computeDirectly() {
for (int i = start; i < end; i++) {
numbers.set(i, numbers.get(i) * factor);
}
}
public static void main(String[] args) {
// 随机生成数字并且存入list中
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 100; i++) {
list.add(current().nextInt(1_000));
}
// 输出原始数据
System.out.println(list);
// 定义 ForkJoinPool
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 定义RecursiveAction
RecursiveActionTest forkJoinTask = new RecursiveActionTest(list, 0, 10, 10);
// 将forkJoinTask提交至ForkJoinPool
forkJoinPool.invoke(forkJoinTask);
System.out.println(list);
}
}
CompletionService
异步任务提交和计算结果Future解耦
CompletionService很好地解决了异步任务的问题,在CompletionService中提供了提交异步任务的方法(真正的异步任务执行还是由其内部的ExecutorService完成的),任务提交之后调用者不再关注Future,而是从BlockingQueue中获取已经执行完成的Future,在异步任务完成之后Future才会被插入阻塞队列,也就是说调用者从阻塞队列中获取的Future是已经完成了的异步执行任务,所以再次通过Future的get方法获取结果时,调用者所在的当前线程将不会被阻塞。
本节学习了CompletionService及其实现ExecutorCompletionService,它并不是ExecutorService的一个实现或者子类,而是对ExecutorService提供了进一步的封装,使得任务的提交者不再关注追踪所返回的Future,并且通过CompletionService直接获取已经运算结束的异步任务,这种方式实现了调用者和Future之间的解耦合,在一定程度上解决了Future会使调用者线程进入阻塞的问题,尤其是通过ExecutorService提交批处理任务为如何快速使用最早结束的异步任务运算结果提供了一种新的思路和实现方式