简明数据类型指南
![]()
 聚焦数据类型大小
聚焦数据类型大小
![]()
正确的顺序
如何创建你自己的头文件
编译器的工作原理
![]()

![]()
 不要重新编译所有文件
不要重新编译所有文件
![]()

![]()
![]()
![]()

勿以小杯盛大物
赋值时要保证值的类型与保存它的变量类型相匹配。
不同数据类型的大小不同,千万别让值的大小超过变
量。
short 比 int 的空间小, int 又比 long 小。所以下面的代码是可行的。
short x = 15;int y = x;printf("y 的值是 %i\n", y);
但是反过来,比如你想在 short 变量中保存 int 值,就
不行。
int x = 100000;short y = x;print("y 的值是 %hi\n", y); //%hi用来格式化
有时,编译器能发现你想在小变量中保存大值,
然后给出一条警告,但大多数情况下编译器不会
发现。
这时当你运行代码,计算机无法在 short
变量中保存100 000。计算机能装多少0、1就装多
少,而最终
保存在变量 y 中的数字已面目全非。
使用类型转换把float值存进整型变量
int x = 7;int y = 2;//float z = x / y;//printf("z = %f\n", z);float z = (float)x / (float)y;printf("z = %f\n", z);
因为 x 和 y 都是整型,而两个整型相除,
结果是一个舍入的整数,在这个例子中z= 3 。
如果希望两个整数
相除的结果
是浮点数,应该先把整数保存到 float 变量
中,做法就是使用类型转换临时转换数值的类型。
(float) x会把 int 值转换为 float 值,计算时就可以把变量当成浮点数来
用。
事实上,如果编译器发现有整数在加、减、乘、除浮点数,会自动替
你完成转换,因此可以减少代码中显式类型转换的次数:
float z = (float)x / y; // y会被编译器自动转换成float
数据类型前的关键字
unsigned
用unsigned修饰的数值只能是非负数。由于无需记录
负数,无符号数有更多的位可以使用,因此它可以保
存更大的数。unsigned int可以保存0到最大值的数。
这个最大值是int可以保存最大值的两倍左右。还有
signed关键字,但你几乎从没见过,因为所有数据类型
默认都是有符号的。
unsigned char c; // 保存0到255的数
long
你可以在数据类型前加long,让它变长。long
int是加长版的int;long int可以保存范围更广的数
字;
long long比long更长;还可以对浮点数用long。
long double d;long long l; //注意:只有C99和C11标准支持long long。
代码示例:
# include <stdio.h>float total = 0.0;short count = 0;short tax_percent = 6;float add_with_tax(float f) {
float tax_rate = 1 + tax_percent/100.0; // 有了.0,计算就会以浮点数进行,否则表达式会返回整数 total = total + (f * tax_rate); count = count+1; return total;}int main() {
float val; printf("Price of item:"); while(scanf("%f",&val)==1) {
printf("Total so far: %.2f\n",add_with_tax(val)); // %.2f把浮点数格式化为小数点后两位。 printf("Price of item:"); } printf("\nFinal total: %.2f\n", total); printf("Number of items: %hi\n", count); %hi用来格式化short return 0;}
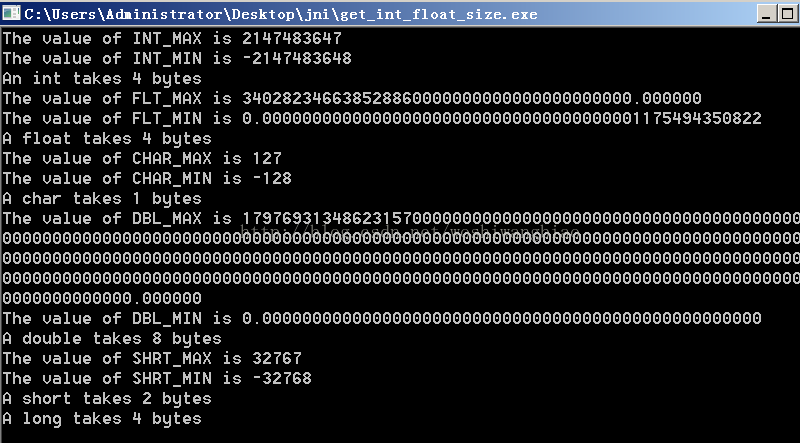
运行结果
不同平台上数据类型的大小不同,
下面这个程
序将告诉你 int 与 float 的最大值和所占字节数。
#include <stdio.h>#include <limits.h>#include <float.h>int main() {
printf("The value of INT_MAX is %i\n", INT_MAX); printf("The value of INT_MIN is %i\n", INT_MIN); printf("An int takes %i bytes\n", sizeof(int)); printf("The value of FLT_MAX is %f\n", FLT_MAX); printf("The value of FLT_MIN is %.50f\n", FLT_MIN); printf("A float takes %i bytes\n", sizeof(float)); //如果你想知道char、 double或long的细节呢?也很简单,只要把 //INT 和 FLT 替换成 CHAR (char) 、 DBL (double) 、 SHRT (short) 或 //LNG (long) 即可。 printf("The value of CHAR_MAX is %i\n", CHAR_MAX); printf("The value of CHAR_MIN is %i\n", CHAR_MIN); printf("A char takes %i bytes\n", sizeof(char)); printf("The value of DBL_MAX is %f\n", DBL_MAX); printf("The value of DBL_MIN is %.50f\n", DBL_MIN); printf("A double takes %i bytes\n", sizeof(double)); printf("The value of SHRT_MAX is %i\n", SHRT_MAX); printf("The value of SHRT_MIN is %i\n", SHRT_MIN); printf("A short takes %i bytes\n", sizeof(short));// printf("The value of LNG_MAX is %l\n", LNG_MAX);// printf("The value of LNG_MIN is %l\n", LNG_MIN); printf("A long takes %i bytes\n", sizeof(long)); return 0;}
运行结果:
问: 为什么不同操作系统的数据类型大小不同?设成一样不是更明了?
答: 为了适应硬件,C语言在不
同的操作系统与处理器上使用不同的
数据类型大小。
C语言诞生之初还是8位机
的天下,
但现在大部分计算机都是32
位和64位的,因为C语言没有指定数
据类型的具体大小,
所以才能与时俱
进。即使新的计算机出来,
C语言还
是能够很好地适应。
问: 8位、64位到底是什么意思?
答: 从技术上讲,计算机的位数
有多种含义,它既可以代表CPU指令
的长度,也可以代表CPU一次从存储
器读取数据的大小。
实际上,位数是
计算机能够处理的数值长度。
问: 这和int、double的大小有什么关系?
答: 如果一台计算机能处理32位
的数值,就会把基本数据类型(例如
int)的大小设为32位。
(在不使用头文件的情况下)同一个源文件中,如果一个函数的定义放在了其调用的地方之后,一般就会报编译器错误。
因为计算机从上往下执行代码时,调用一个函数如果发现前面代码中没有的话,它并不知道该函数的返回值类型,
因此他会先假设函数返回int,但实际上函数可能返回了float ,这就造成了冲突。
在某些场景中,没有正确的顺序
如果有两个函数,它们互相调用对方,那么总有一个函数在定义前被
调用。
声明与定义分离
如果编译器一开始就知道函数的返回类型,就不用自己假设为int了
,
你可以通过 函数声明 显式地告诉编
译器函数会返回什么类型,如:
float add_with_tax()(float f); // 声明没有函数体
如果代码中有很多函数,你又不想管它们在文件中的顺序,可以在
代码的开头列出函数声明:
float do_something_fantastic();double awesomeness_2_dot_0();int stinky_pete();char make_maguerita(int count);
甚至可以把这些声明拿到代码外,放到一个头文件中。
1.创建一个扩展名为.h的文件,并把你的声
明写在里面。
2.在主代码中包含该头文件
#include "totaller.h" // #include是预处理命令
注意:头文件的名字用双引号括起来,而不是尖括号,它们的区别
是:当编译器看到尖括号,就会到标准库代码所在目录
查找头文件,但现在你的头文件和.c文件在同一目录下,用
引号把文件名括起来,编译器就会在本地查找文件。
本地头文件也可以带目录名,但通常会把
它和C文件放在相同目录中
问: 你提到了编译器预处理,为什么编译器需要预处理?
答: 严格意义上讲,编译器只
完成编译的步骤,即把C源代码转化
为汇编语言。但宽泛地讲,编译是将
C源代码转化为可执行文件
的整个过
程,这个过程由很多阶段组成,而
gcc允许你控制这些阶段。gcc会预
处理和编译代码。
问: 什么是预处理?
答: 预处理是把C源代码转化为可
执行文件的第一个阶段。预处理会在正
式编译开始之前修改代码,创建一个新
的源文件。
拿你的代码来说,预处理会
读取头文件中的内容,插入主文件。
问: 预处理器会真的创建一个文件吗?
答: 不会,为了提高编译的效
率,编译器通常会用管道在两个阶段
之间发送数据。
问: gcc就是在哪里找到 stdio.h头文件的?
答: 是的,在类Unix操作系统
中, stdio.h 位于 /usr/include/stdio.h ;
如果在Windows中安装了MinGW编译
器,
stdio.h 就很有可能在 C:\MinGW\
include\stdio.h 中。
C语言是一种很小的语言,所有的保留字都在这里(排名不分先后)。
1.预处理:修改代码。
编译器需要用 #include 指令
添加相关头文件;编译器可能还需要跳过程序中的某些代码,
或补充
一些代码。改完以后就可以随时编译源代码了。
2.编译:转换成汇编代码。
C语言看似底层,但计算机还是无法理解它。计算机只理解更低层
的机器代码指令,
汇编语言描述了程序运行时中央处理器需要执行的指
令。
3.汇编:生成目标代码。
编译器需要将这些符号代码汇编成机器代码或目标代码,即
CPU内部电路执行的二进制代码。
4.链接:放在一起。
一旦有了全部的目标代码,就需要像拼“七巧板”那样把它们拼在
一起,构成可执行程序。当某个目标代码的代码调用了另一个目标
代码的函数时,编译器会把它们连接在一起。同时,链接还会确保
程序能够调用库代码。最后,程序会写到一个可执行程序文件中,
文件格式视操作系统而定,操作系统会根据文件格式把程序加载到
存储器中运行。
共享代码需要自己的头文件
如果想在多个程序之间共享encrypt.c代码,需要想办
法让这些程序知道它,为此你可以用头文件。
比如你想让其他c文件调用下面这个函数
// encrypt.c 文件
#include "encrypt.h"- void encrypt(char *message) {
char c; while (*message) {
*message = *message ^ 31; message++; }}
先要把该函数声明到一个头文件中,并像上面那样自己include该头文件
// encrypt.h 文件void encrypt(char *message);
接下来,在你想调用该函数的源文件中也include上面这个头文件即可。
//message_hider.c文件
#include <stdio.h>#include "encrypt.h" //将包含encrypt.h,这样程序就有了encrypt()函数的声明int main() {
char msg[80]; while(fgets(msg,80,stdin)) { encrypt(msg); printf("%s",msg); }}
为了把多个源文件编译成一个可执行文件,只需执行下面的命令:
gcc message_hider.c encrypt.c -o message_hider
运行结果:
共享变量
你已经知道如何在不同的文件之间
共享函数,但如果你想共享变量呢?
为了防止两个源文件中的同名变量相
互干扰,
变量的作用域仅限于某个文
件内。如果你想共享变量,就应该
在头文件中声明,
并在你当前文件中声明该变量,并在变量名前加上
extern关键字:
- // password.h文件
-
- int passcode = 100;
//message_hider.c文件#include <stdio.h>#include "password.h"- extern int password; // 说明该变量是外部的(这句可不写,写了更好)
int main() {
printf("%i",password);}
运行结果:
如果只修改了一两个源文件便为程序重新编译所有源文件就是浪费。
更有效率的做法:
首先,把源代码编译为目标文件
// 得到单个源文件的目标文件命令:gcc -c xxx.c ---->将生成对应的.o目标文件// 为了得到所有源文件的目标代码,可以输入以下命令:命令:gcc -c *.c --->将生成 所有源文件对应的.o目标文件
然后,把目标文件链接起来
// 链接两个目标文件成可执行文件命令:gcc xxx.o yyy.o -o launch --->将生成可执行文件launch.exe(windows下)// 链接所有目标文件成可执行文件命令:gcc *.o -o launch --->将生成可执行文件launch.exe(windows下)
这样的话,如果你只改了xxx.c文件,就只需再编译一次xxx.c,然后再链接即可,不用再编译所有源文件了。
问题:
如果只改了一个源文件,那还好,但如果你改了很
多文件,就很容易忘记哪些改过哪些没改过
。
要是有工具能自动重新编译那些修改
过的源文件就好了。
解决问题
用make工具自动化构建
make 编译的文件叫目标(target)。严格意义上讲, make 不仅
仅可以用来编译文件。目标可以是任何用其他文件生成的文件,
也就是说目标可以是一批文件压缩而成的压缩文档。
对每个目标, make 需要知道两件事:
1.
依赖项---->
生成目标需要用哪些文件。
2.
生成方法---->
生成该文件时要用哪些指令
依赖项和生成方法合在一起构成了
一条规则。有了规则, make
就知道如何生成目标。
注意:make在Windows中另有其名。
来自UNIX世界的
make在Windows
中有很多“艺名”,MinGW 版
的make叫mingw32-make,而
微软有自己的NMAKE。
用makefile向make描述代码
所有目标、依赖项和生成方法的细节信息需要保存在一
个叫makefile或Makefile的文件中。
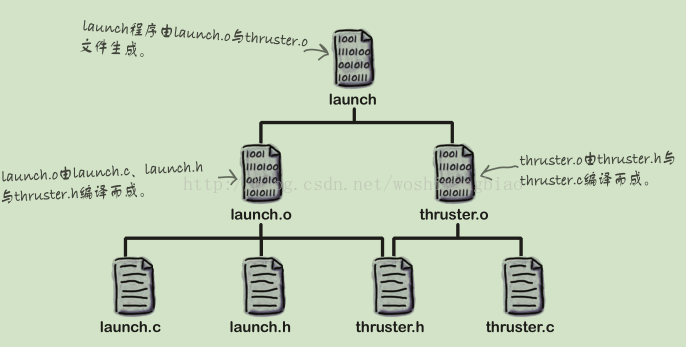
假设由下面这几个文件生成launch.
那么makefile文件应该这么写:
注意:生成方法都必须以tab开头。如果尝试用空格缩进,就无法生成程序。
将 make 规则保存在当前目录下一个叫Makefile的文本文件中,
然后执行命令:make launch
注意:上面的是类Unix系统中的做法。
windows下用makefile命令有所不同:
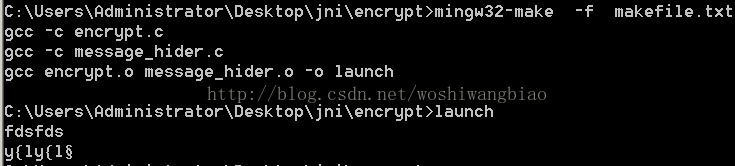
mingw32-make -f makefile.txt
假如makefile.txt文件中是这么写的,那么他只会执行第一条命令
gcc -c encrypt.c。
encrypt.o: encrypt.c encrypt.h gcc -c encrypt.claunch:encrypt.o message_hider.o gcc encrypt.o message_hider.o -o launchmessage_hider.o:encrypt.h message_hider.c gcc -c message_hider.c
想要一次执行所有的命令,就把最后一条合成的命令写到最前面,如
launch:encrypt.o message_hider.o gcc encrypt.o message_hider.o -o launchmessage_hider.o:encrypt.h message_hider.c gcc -c message_hider.cencrypt.o: encrypt.c encrypt.h gcc -c encrypt.c
这样的话他的执行次序就是:
gcc -c encrypt.cgcc -c message_hider.cgcc encrypt.o message_hider.o -o launch
最后生成了一个launch.exe文件。
运行结果:
如果现在我只修改了encrypt.c文件,再执行命令,你发现只有修改的文件由重新编译了,这就是我们想要的效果!
问: 除了编译代码,我能用make做其他事情吗?
答: 可以,虽然make一般用来编译代码,但你也可
以用它充当命令行下的安装程序或源代码控制工具。事实
上,任何可以在命令行中执行的任务,你都可以用make
来做。
make减轻了编译文件时的痛苦,但如果你觉得它还
不够自动化,可以试一试这个叫autoconf的工具:
http://www.gnu.org/software/autoconf/
autoconf可以用来生成makefile。