1.MyBatis的工作流程分析
一、解析配置文件
启动MyBatis时要解析配置文件,包括全局配置文件和映射器配置文件,这里面包含了我们怎么控制MyBatis的行为,和我们要对数据库下达的指令,也就是我们的SQL信息。我们会把它们解析成一Configuration对象。
二、提供操作接口
接下来就是我们操作数据库的接口,它在应用程序和数据库中间,代表我们跟数
据库之间的一次连接:这个就是SqISession对象。
我 们 要 获 得 一 个 会 话 ,必 须 有 一 个 会 话 工 厂 SqISessionFactory。 SqISessionFactory里面又必须包含我们的所有的配置信息,所以我们会通过一个
Builder来创建工厂类。
MyBatis是对JDBC的封装,也就是意味着底层一定会出现JDBC的一些核心对象,
比如执行SQL的 Statement,结果集ResultSet。在 Mybatis里面,SqISession只是提
供给应用的一个接口,还不是SQL的真正的执行对象。
三、执行SQL操作
SqISession持有了一个Executor对象,用来封装对数据库的操作。
在执行器Executor执行query或者update操作的时候我们创建一系列的对象, 来处理参数、执行SQL、处理结果集,这里我们把它简化成— 对象:StatementHandler, 可以把它理解为对Statement的封装,在阅读源码的时候我们再去了解还有什么其他的
对象。
四、MyBatis主要的工作流程
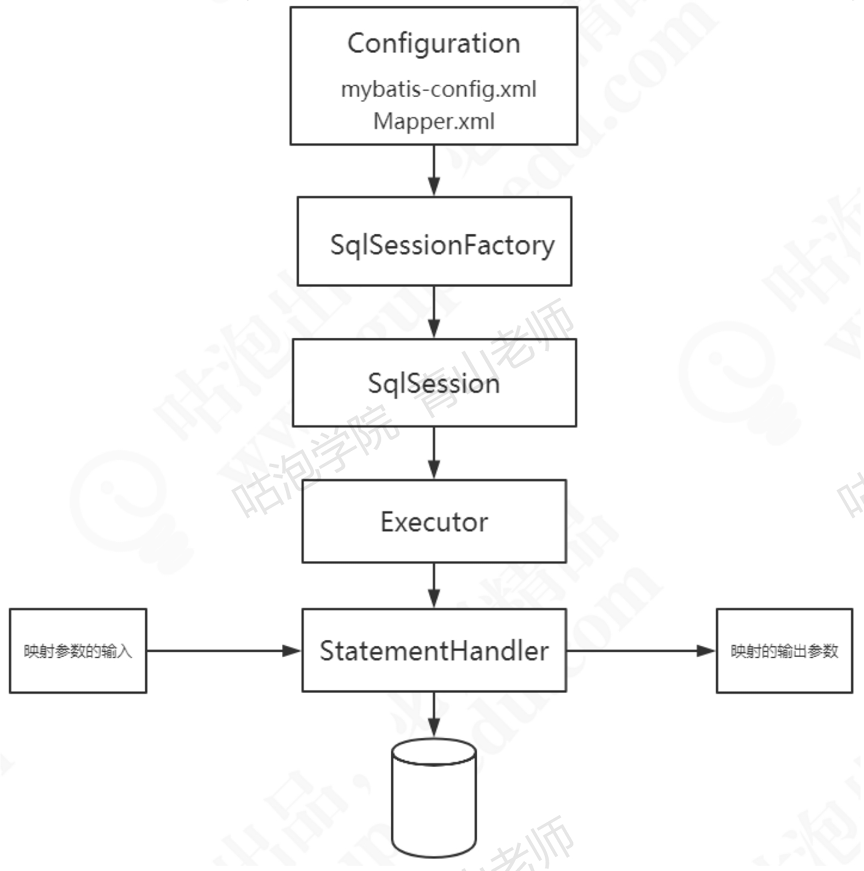
2.MyBatis架构分层与模块划分(总)
按照功能职责的不同,所有的package可以分成不同的工作层次。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xBjzFGEr-1589355509875)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510153506611.png)]
2.1.接口层
首先接口层是我们打交道最多的。核心对象是SqISession,它是上层应用和MyBatis 打交道的桥梁,SqlSession±定义了非常多的对数据库的操作方法。接口层在接收到调用请求的时候,会调用核心处理层的相应模块来完成具体的数据库操作。
2.2.核心处理层
核心处理层主要做了这几件事:
- 把接口中传入的参数解析并且映射成JDBC类型;
- 解析xml文件中的SQL语句,包括插入参数,和动态SQL的生成;
- 执 行 SQL语句;
- 处理结果集,并映射成Java对象。
2.3.基础支持层
基础支持层主要是一些抽取出来的通用的功能(实现复用),用来支持核心处理层的功能。比如数据源、缓存、日志、xml解析、反射、IO、 事务等等这些功能。
3.MyBatis缓存详解
cache缓存
cache缓存是一般的ORM框架都会提供的功能,目的就是提升查询的效率和减少数据库的压力。跟 Hibernate一样,MyBatis也有一级缓存和二级缓存,并且预留了集成第三方
缓存的接口。
缓存体系结构
MyBatis跟缓存相关的类都在cache包里面,其中有一个Cache接口,只有一个默
认的实现类PerpetualCache,它是用HashMap实现的。
PerpetualCache这个对象一定会创建,所以这个叫做基础缓存。但是缓存又可以有 很多额外的功能,比如回收策略、日志记录、定时刷新等等,如果需要的话,就可以给
基础缓存加上这些功能,如果不需要,就不加。
除了基础缓存之外,MyBatis也定义了很多的装饰器,同样实现了 Cache接口,通 过这些装饰器可以额外实现很多的功能。
// 煎饼加鸡蛋加香肠
以
“装饰者模式(Decorator Pattern)是指在不改变原有对象的基础之上,将功能附加到对象上,提供了比继承更有弹 性的替代方案(扩展原有对象的功能)。”

debug源码的时候,有可能会看到基础缓存被装饰四五层,当然不管怎么装饰,经 过多少层装饰’最后使用的还是基本的实现类(默认PerpetualCache)。

所有的缓存实现类总体上可分为三类:基本缓存、淘汰算法缓存、装饰器缓存。

3.1.一级缓存
—级缓存也叫本地缓存(Local Cache), MyBatis的一级缓存是在会话(SqISession)
层面进行缓存的。MyBatis的一级缓存是默认开启的,不需要任何的配置
(localCacheScope 设置为 STATEMENT 关闭一级缓存)。
首先我们必须去弄清楚一个问题,在 MyBatis执行的流程里面,涉及到这么多的对 象’那么缓存PerpetualCache应该放在哪个对象里面去维护?
如果要在同一个会话里面共享一级缓存,最好的办法是在SqISession里面创建的,
作为SqISession的一个属性,跟 SqISession共存亡,这样就不需要为SqISession编III 号、
再根据SqISession的编号去查找对应的缓存了。
DefaultSqISession 里面只有两个对象属性:Configuration 和 Executoro
Configuration是全局的,不属于SqISession,所以缓存只可能放在Executor里面 维护----实际上它是在基本执行器 SimpleExecutor/ReuseExecutor/BatchExecutor 的 父类BaseExecutor的构造函数中持有了 PerpetualCache
在同一个会话里面,多次执行相同的SQL语句,会直接从内存取到缓存的结果,不
会再发送SQL到数据库。但是不同的会话里面,即使执行的SQL一模一样(通过一个
Mapper的同一个方法的相同参数调用),也不能使用到一级缓存。

接下来我们来验证一下,MyBatis的一级缓存到底是不是只能在一个会话里面共享, 以及跨会话(不同session)操作相同的数据会产生什么问题。
3.2.一级缓存验证
注意演示一级缓存需要先关闭二级缓存,localCacheScope设置为SESSION。
怎么判断是否命中缓存?
如果再次发送SQL到数据库执行(控制台打印了 SQL语
句 ),说明没有命中缓存;如果直接打印对象,说明是从内存缓存中取到了结果。
—级缓存在什么时候put,什么时候get,什么时候clear?
—级缓存在 BaseExecutor 的 query。——queryFromDatabase()中存入。在 queryFromDatabase 之前会 get()
—级缓存怎么命中? CacheKey怎么构成?
BaseExecutor 的 queryFromDatabase()
一级缓存什么时候会被清空呢?
同一个会话中,update (包括delete)会导致一级缓存被清空
只有更新会清空缓存吗?查询会清空缓存吗?如果要清空呢?
—级缓存是在BaseExecutor中的update()方法中调用clearLocalCache()清空的 (无条件),如果是query会判断(只有select标签的HushCache=true才清空)。
一级缓存的工作范围是一个会话。如果跨会话,会出现什么问题?
其他会话更新了数据,导致读取到过时的数据(一级缓存不能跨会话共享)
3.3.二级缓存
二级缓存是用来解决一级缓存不能跨会话共享的问题的,范围是namespace级别 的,可以被多个SqISession共 享 (只要是同一个接口里面的相同方法,都可以共享), 生命周期和应用同步。
思考一个问题:如果开启了二级缓存,二级缓存应该是工作在一级缓存之前,还是
在一级缓存之后呢?二级缓存是在哪里维护的呢?
作为一个作用范围更广的缓存,它肯定是在SqISession的夕卜层,否则不可能被多个
SqISession 共享。
而一级缓存是在SqISession内部的,所以第一个问题,肯定是工作在一级缓存之前, 也就是只有取不到二级缓存的情况下才到一个会话中去取一级缓存。
第二个问题,二级缓存放在哪个对象中维护呢? 要跨会话共享的话,SqISession本 身和它里面的BaseExecutor已经满足不了需求了,那我们应该在BaseExecutor之外创
建一个对象。
但是,二级缓存是不一定开启的。也就是说,开启了二级缓存,就启用这个对象,
如果没有,就不用这个对象,我们应该怎么做呢?就好像你的煎饼果子要加鸡蛋就加鸡
重,要加火腿就加火腿(又来了)……
实际上MyBatis用了一个装饰器的类来维护,就是CachingExecutoro 如果启用了二级缓存,MyBatis在 创 建 Executor对象的时候会对Executor进行装饰。
CachingExecutor对于查询请求,会判断二级缓存是否有缓存结果,如果有就直接 返回,如果没有委派交给真正的查询器Executor实现类,比 如 SimpleExecutor来执行 查询,再走到一级缓存的流程。最后会把结果缓存起来,并且返回给用户。

我们知道,一级缓存是默认开启的,那二级缓存怎么开启呢?我们来看下二级缓存
的开启方式。
3.4.开启二级缓存的方法
第一步:在 mybatis-config.xml中 配 置 了 (可以不配9 置,默认是true):
<setting name="cacheEnabled" value="true"/>
只要没有显式地设置cacheEnabled=false,都 会 用 CachingExecutor装饰基本的执 行 器 (SIMPLE. REUSE、BATCH)。
二级缓存的总开关是默认开启的。但是每个Mapper的二级缓存开关是默认关闭的。 一 个 Mapper要用到二级缓存,还要单独打开它自己的开关。
第二步:在 Mapper.xml中配置<cache/>标签:
<!-- 声明这个namespace使用二级缓存 -->
<cache type="org.apache.ibatis.cache.impl.PerpetualCache"
size="1024" <!—最多缓存对象个数,默认1024-->
eviction="LRU" <!—回收策略-->
flushInterval="120000" <!— 自动刷新时间ms ,未配置时只有调用时刷新——>
readOnly="false"/> <!—默认是false (安全),改为true可读写时,对象必须支持序列化-->
cache属性详解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uA8RFwdQ-1589355509878)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510184419636.png)]
Mapper.xml 配 置了<cache>之 后 ,select会被缓存。update、delete、insert
会刷新缓存。
如果二级缓存拿到结果了,就直接返回(最外层的判断),否则再到一级缓存,最
后到数据库。
如 果 cacheEnabled=true, Mapper.xml没有配置<cache>标签,还有二级缓存吗?还会出现CachingExecutor包装对象吗?
只要cacheEnabled=true基本执行器就会被装饰。有没有配置<cache>,决定了在 启动的时候会不会创建这个mapper的 Cache对象,最终会影响到CachingExecutor
query方法里面的判断:
if (cache != null) {
也就是说,此时会装饰,但是没有cache对象,依然不会走二级缓存流程。
如果一个Mapper需要开启二级缓存,但是这个里面的某些查询方法对数据的实时 性要求很高,不需要二级缓存,怎么办?
我们可以在单个Statement ID上显式关闭二级缓存(默认是true):
<select id="selectBlog" resultMap="BaseResultMap" useCache="false">
CachingExecutor query方法有对这个属性的判断:
3.5.二级缓存验证
(验证二级缓存需要先开启二级缓存)
1、 事务不提交,二级缓存不存在
思考:为什么事务不提交,二级缓存不生效?
因为二级缓存使用TransactionalCacheManager (TCM )来管理,最后又调用了 TransactionalCache 的 getObject()、 putObject 和 commit方法,TransactionalCache
里面又持有了真正的Cache对象,比如是经过层层装饰的PerpetualCache
在 putObject的时候,只是添加到了 entriesToAddOnCommit里面,只有它的 commit方法被调用的时候才会调用flushPendingEntries()真正写入缓存。它就是在 DefaultSqISession调用commit()的时候被调用的。
2、使用不同的session和 mapper,并且提交事务,验证二级缓存可以跨session
存在
3、在其他的session中执行增删改操作,验证缓存会被刷新
为什么增删改操作会清空缓存?
在CachingExecutor的update方法里面会调用flushCacheIfRequired(ms),isFlushCacheRequired就是从标签里面渠道的flushCache的值。而增删改操作的 flushCache属性默认为true。
也就是说,如果不需要清空二级缓存,可以把flushCache属性修改为false (这样 会造成过时数据的问题)。
什么时候开启二级缓存?
一级缓存默认是打开的,二级缓存需要配置才可以开启。那么我们必须思考一个问
题,在什么情况下才有必要去开启二级缓存?
1、 因为所有的增删改都会刷新二级缓存,导致二级缓存失效,所以适合在查询为主
的应用中使用,比如历史交易、历史订单的查询。否则缓存就失去了意义。
2、 如果多个namespace中有针对于同一个表的操作,比如Blog表,如果在一个 namespace中刷新了缓存,另一个namespace中没有刷新,就会出现读到脏数据的情
况。
所以,推荐在一个Mapper里面只操作单表的情况使用。
如果要让多个namespace共享一个二级缓存,应该怎么做?
跨 namespace的缓存共享的问题,可以使用<cache-ref>来解决:
<cache-ref namespace="com.gupaoedu.crud.dao.DepartmentMapper" />
cache-ref代表引用别的命名空间的Cache配置,两个命名空间的操作使用的是同一个Cache。在关联的表比较少,或者按照业务可以对表进行分组的时候可以使用。
注意:在这种情况下,多个Mapper的操作都会弓I起缓存刷新,缓存的意义已经不
大了。
3.6.第三方缓存做二级缓存
除了 MyBatis自带的二级缓存之外,我们也可以通过实现Cache接口来自定义二级
缓存。
MyBatis官方提供了一些第三方缓存集成方式,比如ehcache和 redis: https://github.com/mybatis/reclis-cache
pom文件引入依赖:
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
Mapper.xml 配置,type 使用 RedisCache:
<cache type="org.mybatis.caches.redis.RedisCache"
eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
redis.properties 酉己置:
host=localhost
port=6379
connectionTimeout=5000
soTimeout=5000
database=0
当然’在分布式环境中,我们也可以使用独立的缓存服务 不使用MyBatis自带的
二级缓存。
4.MyBatis源码解读
4.1.带着问题去看源码
分析源码,我们还是从编程式的demo入手。
@Before
public void prepare() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
}
/**
* 通过 SqlSession.getMapper(XXXMapper.class) 接口方式
* @throws IOException
*/
@Test
public void testSelect() throws IOException {
SqlSession session = sqlSessionFactory.openSession(); // ExecutorType.BATCH
try {
BlogMapper mapper = session.getMapper(BlogMapper.class);
Blog blog = mapper.selectBlogById(1);
System.out.println(blog);
} finally {
session.close();
}
}
把文件读取成流的这一步我们就省略了。所以下面我们分成五步来分析。
第一步,我们创建一个工厂类,配置文件的解析就是在这一步完成的,包括
mvbatis-config.xml 和 Mapper 映射器文件。
这一步我们关心的内容:解析的时候做了什么,产生了什么对象,解析的结果存放
到了哪里。解析的结果决定着我们后面有什么对象可以使用,和到哪里去取。
第二步,通过 SqISessionFactory 创建一个 SqlSession
问题:SqISession上面定义了各种增删改查的API, 是给客户端调用的。返回了什么实现类?除了 SqISession,还创建了什么对象,创建了什么环境?
第三步,获得一个Mapper对象。
问题:Mapper是一个接口,没有实现类,是不能被实例化的,那获取到的这个 Mapper对象是什么对象?为什么要从SqISession里面去获取?为什么传进去一个接口,然后还要用接口类型来接收?
第四步,调用接口方法。
问题:我们的接口没有创建实现类,为什么可以调用它的方法?那它调用的是什么
方法?
这一步实际做的事情是执行SQ L,那它又是根据什么找到XML映射器里面的SQL
的? 此外,我们的方法参数(对象或者Map)是怎么转换成SQL参数的?获取到的结 果集是怎么转换成对象的?
最后一步,关闭session,这一步是必须要做的。
F面我们会按照这五个步骤,去理解MyBatis的运行原理,这里面会涉及到很多核心的对象和关键的方法。
4.2.看源码的注意事项
1、 一定要带着问题去看,猜想验证。
2、 不要只记忆流程,学编程风格,设计思想(他的代码为什么这么写?如果不这么写
呢?包括接口的定义,类的职责,涉及模式的应用,高级语法等等)。
3、 先抓重点,就像开车熟路,哪个地方限速,哪个地方变道,要走很多次才会熟练。
先走主干道,再去覆盖分支小路。
4、 记录核心流程和对象,总结层次、结构、关系,输 出 (图片或者待注释的源码)。
5、 培养看源码的信心和感觉,从带着看到自己去看,看更多的源码。
6、 debug还是直接Ctrl+Alt+B跟方法?
debug可以看到实际的值,比如到底是哪个实现类,value到底是什么。
5.配置解析过程
首先我们要清楚的是配您 置解析的过程全部只解析了两种文件。一个是
mybatis-config.xml全局配置文件。另外就是所有的Mapper.xml文件,也包括在
Mapper接口类上面定义的注解。
我们从mybatis-config.xml开始。在第一节课的时候我们已经分析了核心配置了, 大概明白了 MyBatis有哪些配置项,和这些配9 置项的大致含义。这里我们再具体看一下 这里面的标签都是怎么解析的,解析的时候做了什么。
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
首先我们new 了一个SqISessionFactoryBuilder,这是建造者模式的运用(建造者模式用来创建复杂对象,而不需要关注内部细节,是一种封装的体现)。MyBatis中很 多地方用到了建造者模式(名字以Builder结尾的类还有9个)。
SqISessionFactoryBuilder 中用来创建 SqISessionFactory 对象的方法是 build(),build方 法 有 9 个 重 载 ,可以用不同的方式来创建sqISessionFactory对象。
SqISessionFactory对象默认是单例的。
5.1.XMLConfigBuilder
这 里 面 创 建 了 一 个 XMLConfigBuilder对 象 (用来存放所有配置信息的
Configuration对象也是这个时候创建的)。
XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties);
XMLConfigBuilder是抽象类BaseBuilder的一个子类,专门用来解析全局配置文
件,针对不同的构建目标还有其他的一些子类(关联到源码路径),比如:
XMLMapperBuilder:解析 Mapper 映射器
XMLStatementBuilder:解析增删改查标签
XMLScriptBuilder:解析动态 SQL
根据我们解析的文件流,这里后面两个参数都是空的,创建了一个parser。
return build(parser.parse());
这里有两步,第一步是调用parser的 parse。方法’它会返回一个Configuration
类。
之前我们说过,也就是配置文件里面所有的信息都会放在Configuration里面。<configuration>的子标签跟Configuration类的属性是直接对应的。
我们先看一下parse方法:
首先会检查全局配置文件是不是已经解析过,也就是说在应用的生命周期里面,
config配置文件只需要解析一次,生成的Configuration对象也会存在应用的整个生命
周期中。
接下来就是 parseConfiguration 方法:
parseConfiguration(parser.evalNode("/configuiation"));
解析XML有很多方法,MyBatis对 dom和 SAX做了封装,方便使用。
这下面有十几个方法,对应着config文件里面的所有一级标签。
问题:MyBatis全局配置文件中标签的顺序可以颠倒吗?比如把settings放在 p山gin之后?会报错。所以顺序必须严格一致。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8w9yH3ds-1589355509887)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510192403100.png)]
5.2.propertiesElement()
第一个是解析<properties>标 签 ,读取我们引入的外部配置文件,例如
db.properties
这里面又有两种类型,一种是放在resource目录下的,是相对路径,一种是写的绝对路径的(url)。
解析的最终结果就是我们会把所有的配置信息放到名为defaults的 Properties对象
里面(Hashtable 对象,KV 存储),最后把 XPathParser 和 Configuration 的 Properties
属性都设置成我们填充后的Properties对象。
parser.setVariables(defaults);
configuration.setVariables(defaults);
5.3.settingsAsProperties()
第二个,我们把〈settings〉标签也解析成了一个Properties对象,对于〈settings〉
标签的子标签的处理在后面(先解析,后设置)。
Properties settings = settingsAsProperties(root.evalNode("settings"));
在早期的版本里面解析和设置都是在后面一起的,这里先解析成Properties对象是 因为下面的两个方法要用到。
5.4.loadCustomVfs(settings)
loadCustomVfs是获取Vitual File System 的自定义实现类,比如要读取本地文件,
或者FTP远程文件的时候,就可以用到自定义的VFS类。
根据〈settings〉标签里面的<vfslmpl>标签,生成了一个抽象类V FS 的子类,在
MyBatis中有JBoss6VFS和 DefaultVFS两个实现,在 io 包中。
Class<? extends VFS> vfslmpl = (Class<? extends VFS>)Resources.classForName(clazz);
configuration.setVfslmpl(vfslmpl);
最后赋值到Configuration中。
5.5.loadCustomLoglmpl(settings)
loadCustomLoglmpI是根据<loglmpl>标签获取日志的实现类,我们可以用到很 多的日志的方案,包括LOG4Jz LOG4J2, SLF4J等等,在 logging包中。
Class<? extends Log> loglmpl = resolveClassCprops.getProperty("loglmpl"));
configuration. setLoglmpl(loglmpl);
这里生成了一个Log接口的实现类,并且赋值到Configuration中。
5.6.typeAliasesElement
这一步解析的是类型别名。
我们在讲配置的时候也讲过,它有两种定义方式,一种是直接定义一个类的别名(例
如 com.domain.Blog定义成b lo g ), —种就是指定一个package ,那么这个包下面所
有的类的名字就会成为这个类全路径的别名。
类的别名和类的关系,我们放在一个TypeAliasRegistry对象里面。
tpeAliasRegistry.registerAlias(alias, clazz);
大家也可以推测一下,如果要保存这种类名(String)和 类 (Class)的对应关系,
TypeAliasRegistry应该是一个什么样的数据结构。
5.7.pluginElement
这一步是解析<environments>标签
我们前面讲过,一个environment就是对应一个数据源,所以在这里我们会根据配置的<transactionManager>创建一个事务工厂,根据<dataSource>标签创建一个数据 源,最后把这两个对象设置成Environment对象的属性,放到Configuration里面。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YRfTmoqR-1589355509889)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510193754091.png)]
5.8.databaseldProviderElement()
解析databaseldProvider标签,生成DatabaseldProvider对 象 (用来支持不同厂
商的数据库)。
5.9.typeHandlerElement()
跟 TypeAlias—样,TypeHandler有两种配置方式,一种是单独配置一个类,一种
是指定一个package。最后我们得到的是JavaType和 JdbcType,以及用来做相互映射 的 TypeHandler之间的映射关系,存放在TypeHandlerRegistry对象里面。
typeHandlerRegistry.register(javaTypeClass, jdbcType, typeHandlerClass);
问题:这种三个对象(Java类型,JDBC类型,Handler)的关系怎么映射? (Map
里面再放一个Map)
5.10.mapperElement()
http://www.mybatis.org/mybatis-3/zh/configuration.html#mappers
最后就是<mappers>标签的解析。
根据全局配置文件中不同的注册方式,用不同的方式扫描,但最终都是做了两件事
情,对于语句的注册和接口的注册。

private void mapperElement(XNode parent) throws Exception {
if (parent != null) {
for (XNode child : parent.getChildren()) {
// 不同的定义方式的扫描,最终都是调用 addMapper()方法(添加到 MapperRegistry)。这个方法和 getMapper() 对应
// package 包
if ("package".equals(child.getName())) {
String mapperPackage = child.getStringAttribute("name");
configuration.addMappers(mapperPackage);
} else {
String resource = child.getStringAttribute("resource");
String url = child.getStringAttribute("url");
String mapperClass = child.getStringAttribute("class");
if (resource != null && url == null && mapperClass == null) {
// resource 相对路径
ErrorContext.instance().resource(resource);
InputStream inputStream = Resources.getResourceAsStream(resource);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments());
// 解析 Mapper.xml,总体上做了两件事情 >>
mapperParser.parse();
} else if (resource == null && url != null && mapperClass == null) {
// url 绝对路径
ErrorContext.instance().resource(url);
InputStream inputStream = Resources.getUrlAsStream(url);
XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments());
mapperParser.parse();
} else if (resource == null && url == null && mapperClass != null) {
// class 单个接口
Class<?> mapperInterface = Resources.classForName(mapperClass);
configuration.addMapper(mapperInterface);
} else {
throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one.");
}
}
}
}
}
先从解析 Mapper.xml 的 mapperParser.parse()方法入手。
public void parse() {
// 总体上做了两件事情,对于语句的注册和接口的注册
if (!configuration.isResourceLoaded(resource)) {
// 1、具体增删改查标签的解析。
// 一个标签一个MappedStatement。 >>
configurationElement(parser.evalNode("/mapper"));
configuration.addLoadedResource(resource);
// 2、把namespace(接口类型)和工厂类绑定起来,放到一个map。
// 一个namespace 一个 MapperProxyFactory >>
bindMapperForNamespace();
}
}
configurationElement---- 解析所有的子标签,最终获得MappedStatement对
象。
bindMapperForNamespace()---- 把 namespace (接口 类 型 ) 和 工 厂 类 MapperProxyFactory 绑定起来。
1) configurationElement()
configuration Element是 对 Mapper.xml中 所 有 具 体 标 签 的 解 析 ,包括 namespace, cache、parameterMap、resultMap、sql 和 select|insert|update|delete
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
// 添加缓存对象
cacheRefElement(context.evalNode("cache-ref"));
// 解析 cache 属性,添加缓存对象
cacheElement(context.evalNode("cache"));
// 创建 ParameterMapping 对象
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
// 创建 List<ResultMapping>
resultMapElements(context.evalNodes("/mapper/resultMap"));
// 解析可以复用的SQL
sqlElement(context.evalNodes("/mapper/sql"));
// 解析增删改查标签,得到 MappedStatement >>
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
在 buildStatementFromContext。方法中,创建了用来解析增删改查标签的 XMLStatementBuilder,并且把创建的 MappedStatement 添加至ij mappedStatements 中。
MappedStatement statement = statementBuilder.build();
// 最关键的一步,在 Configuration 添加了 MappedStatement >>
configuration.addMappedStatement(statement);
return statement;
2) bindMapperForNamespace()
主要是是调用了 addMapper()
configuration.addMapper(boundType);
addMapper方法中,把接口类型注册到MapperRegistry中:实际上是为接口创 建 一 个 对 应 的 MapperProxyFactory (用 于 为 这 个 type提 供工厂类 创建 MapperProxy)。
knownMappers.put(type, new MapperProxyFactoiy<>(type));
注 册 了 接 口 之 后 ,开 始 解 析 接 口 类 和 所 有 方 法 上 的 注 解 ,例如
@CacheNamespace、 @Select
此处创建了一个MapperAnnotationBuilder专门用来解析注解。
MapperAimotationBuilder parser = new MappeiAiinotationBuilder(config, type);
parser.parse();
parse方 法 中 的 parseCache()和 parseCacheRef()方 法 其 实 是 对 @CacheNamespace 和 @CacheNamespaceRef 这两个注解的处理。
public void parse() {
String resource = type.toString();
if (!configuration.isResourceLoaded(resource)) {
// 先判断 Mapper.xml 有没有解析,没有的话先解析 Mapper.xml(例如定义 package 方式)
loadXmlResource();
configuration.addLoadedResource(resource);
assistant.setCurrentNamespace(type.getName());
// 处理 @CacheNamespace
parseCache();
// 处理 @CacheNamespaceRef
parseCacheRef();
// 获取所有方法
Method[] methods = type.getMethods();
for (Method method : methods) {
try {
// issue #237
if (!method.isBridge()) {
// 解析方法上的注解,添加到 MappedStatement 集合中 >>
parseStatement(method);
}
} catch (IncompleteElementException e) {
configuration.addIncompleteMethod(new MethodResolver(this, method));
}
}
}
parsePendingMethods();
}
parseStatement()方法里面的各种getAnnotation,都是对相应的注解的解析, 比如@Options, @SelectKey,@ResultMap 等等。
最后同样会创建MappedStatement对象,添加到MapperRegistry中。也就是说在XML中配置,和使用注解配置,最后起到一样的效果。
// 最后 增删改查标签 也要添加到 MappedStatement 集合中
assistant.addMappedStatement(
mappedStatementId,
sqlSource,
statementType,
sqlCommandType,
fetchSize,
timeout,
// ParameterMapID
null,
parameterTypeClass,
resultMapId,
getReturnType(method),
resultSetType,
flushCache,
useCache,
// TODO gcode issue #577
false,
keyGenerator,
keyProperty,
keyColumn,
// DatabaseID
null,
languageDriver,
// ResultSets
options != null ? nullOrEmpty(options.resultSets()) : null);
4) build
Mapper.xml解析完之后,调用另一个build()方法,返 回 SqISessionFactory的默 认实现类 DefaultSqlSessionFactory
public SqlSessionFactoiy build(Configuration config) {
return new DefaultSqlSessionFactoiy(config);
}
总结
在这一步,我们主要完成了 config配置文件、Mapper文件、Mapper接口中注解
的解析。
我们得到了一个最重要的对象Configuration,这里面存放了全部的配置信息,它在 属性里面还有各种各样的容器。
最后,返回了一个 DefaultSqISessionFactory,里面持有了 Configuration 的实例。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xd2sd6LH-1589355509890)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510201250500.png)]
6.会话创建过程
程序每一次操作数据库,都需要创建一个会话,我们用openSession()方法来创建。
SqlSession session = sqlSessionFactory.openSession();
里 用 到 了 上 一 步 创 建 的 DefaultSqISessionFactory , 在 openSessionFromDataSource()方法中创建。
这个会话里面,需要包含一个Executor用来执行SQL。Executor又要指定事务类型和执行器的类型。
所以我们会先从Configuration里面拿到Enviroment, Enviroment里面就有事务
工厂。
6.1.创建 Transaction
这里会从Environment对象中取出一个TransactionFactory,它是解析 <environments>标签的时候创建的。
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
final Transaction tx = transactionFactory.newTransaction(connection);
事务工厂类型可以配置成JDBC或者MANAGED

如果配置的是 JDBC,则会使用 Connection 对象的 commit、rollback、close()
管理事务。
如果9配置成MANAGED,会把事务交给容器来管理,比如JBOSS, Weblogic。因
为我们跑的是本地程序,如果配置成MANAGE不会有任何事务。
如 果 是 Spring + MyBatis , 则 没 有 必 要 配 置 , 因 为 我 们 会 直 接 在
您
applicationContext.xml里面配置数据源和事务管理器,覆盖MyBatis的配您 置。
6.2.创建 Executor
使用newExecutor方法创建:
// 根据事务工厂和默认的执行器类型,创建执行器 >>
final Executor executor = configuration.newExecutor(tx, execType);
可以细分成三步。
1 )创建执行器
Executor 的 基 本 类 型 有 三 种 :SIMPLE、BATCH、R EU SE,默认是 SIMPLE (settingsElement()读取默认值)。
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
// 默认 SimpleExecutor
executor = new SimpleExecutor(this, transaction);
}
}
他们都继承了抽象类BaseExecutor。 抽象类实现了 Executor接口。

为什么要让抽象类BaseExecutor实现Executor接口,然后让具体实现类继承抽象
类?
这是模板方法的体现。
模板方法定义一个算法的骨架,并允许子类为一个或者多个步骤提供实现。模板方法使得子类可以在不
改变算法结构的情况下,重新定义算法的某些步骤。
抽象方法是在子类中实现的,BaseExecutor最终会调用到具体的子类。
@Override
protected int doUpdate(MappedStatement ms, Object parameter) throws SQLException {
throw new UnsupportedOperationException("Not supported.");
}
@Override
protected List<BatchResult> doFlushStatements(boolean isRollback) throws SQLException {
throw new UnsupportedOperationException("Not supported.");
}
@Override
protected <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
throw new UnsupportedOperationException("Not supported.");
}
2)缓存装饰
如果cacheEnabled=true ,会用装饰器模式对executor进行装饰。
// 二级缓存开关,settings 中的 cacheEnabled 默认是 true
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
3)插件代理
装饰完毕后,会执行:
// 植入插件的逻辑,至此,四大对象已经全部拦截完毕
executor = (Executor) interceptorChain.pluginAll(executor);
此处会对executor植入插件逻辑。
4)返回SqISession实现类
最终返回 DefaultSqISession,它的属性包括 Configuration. Executor 对象。
return new DefaultSqlSession(configuration, executor, autoCommit);
6.3.总结
创建会话的过程,我们获得了一个DefaultSqISession,里面包含了一个Executor, Executor是 SQL的实际执行对象。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DOtANbGP-1589355509892)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510203132329.png)]
7.获得Mapper对象
在 旧 版 的 MyBatis中 ,DefaultSqISession的 selectOne()方法可以直接根据 Mappenxml中的StatementID ,找到SQL执行。但是这种方式属于硬编码,我们没办
法知道有多少处调用,修改起来也很麻烦。
另一个问题是如果参数传入错误,在编译阶段也是不会报错的,不利于预先发现问
题。
Blog blog = (Blog) session.selectOne("org.mybatis.example.BlogMapper.selectBlogById", 1);
在 MyBatis后期的版本提供了第二种调用方式,就是定义一个接口,然后再调用
Mapper接口的方法。
由于我们的接口名称跟Mapper.xml的 namespace是对应的,接口的方法跟 statement ID也都是对应的,所以根据方法就能找到对应的要执行的SQL。
BlogMapper mapper = session.getMapper(BlogMapper.class);
这里有两个问题需要解决:
1、getMapper获得的是一个什么对象?为什么可以执行它的方法?
2、到底是怎么根据Mapper找到XML中的SQL执行的?
7.1.getMapper()
DefaultSqISession 的 getMapper()方法,调用了 Configuration 的 getMapper
方法。
configuration.<T>getMapper()
Configuration 的 getMapper()方法,又调用了 MapperRegistry 的 getMapper方法。
return mapperRegistry.getMapper(type, sqlSession);
我们知道,在解析mapper标签和Mapper.xml的时候已经把接口类型和类型对应
的 MapperProxyFactory放到了一个Map中。获取Mapper代理对象 实际上是从
Map中获取对应的工厂类后,调用以下方法创建对象:
@SuppressWarnings("unchecked")
public <T> T getMapper(Class<T> type, SqlSession sqlSession) {
final MapperProxyFactory<T> mapperProxyFactory = (MapperProxyFactory<T>) knownMappers.get(type);
if (mapperProxyFactory == null) {
throw new BindingException("Type " + type + " is not known to the MapperRegistry.");
}
try {
return mapperProxyFactory.newInstance(sqlSession);
} catch (Exception e) {
throw new BindingException("Error getting mapper instance. Cause: " + e, e);
}
}
在 newlnstance()方法中,先创建 MapperProxy
MapperProxy 实现了 InvocationHandler 接口,主要属性有三个:sqISession、 mapperinterface、methodCache。
public T newInstance(SqlSession sqlSession) {
final MapperProxy<T> mapperProxy = new MapperProxy<>(sqlSession, mapperInterface, methodCache);
return newInstance(mapperProxy);
}
最终通过JDK动态代理模式创建、返回代理对象:
也就是说,getMapperQ返回的是一个JDK动 态 代 理 对 象 ( 类 型 数 字 ) 。 这个代理对象会继承Proxy类,实现被代理的接口,里面持有了一个MapperProxy类
型的触发管理类。
回答了前面的问题:为什么要在MapperRegistry中保存一个工厂类/原来它是用
来创建返回代理类的。
这里是代理模式的一个非常经典的应用
但是为什么要直接代理一个接口呢?
7.2.MapperProxy如何实现对接口的代理
我们知道,JDK的动态代理,有三个核心角色:被代理类(实现类)、接口、实现
了 InvocationHandler的触发管理类,用来生成代理对象。
被代理类必须实现接口,因为要通过接口获取方法,而且代理类也要实现这个接口。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-X6gMNO49-1589355509895)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510204834382.png)]
而 MyBatis里面的Mapper没有实现类,怎么被代理呢?它忽略了实现类,直接对
接口进行代理。
MyBatis的动态代理:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uF1xLXpu-1589355509896)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510204916531.png)]
在 MyBatis里面,动态代理为什么不需要实现类呢?
这里我们要想想我们的目的。我们的目的是根据一个可以执行的方法,直接找到
Mapper.xml 中的 Statement ID ,方便调用。
如果根据接口类型+ 方法的名称找到Statement ID 这个逻辑在Handler类 (MapperProxy)中就可以完成,其实也就没有实现类的什么事了。
7.3.总结
获得Mapper对象的过程,实质上是获取了 一个JDK动态代理对象(类型是$ Proxy 数字)。这个代理类会继承Proxy类,实现被代理的接口,里面持有了一个MapperProxy 类型的触发管理类。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yFeWOIVm-1589355509897)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510205019344.png)]
8.执行SQL
Blog blog = mapper.selectBlog(1);
由于所有的Mapper都是JDK动态代理对象,所以任意的方法都是执行触发管理类
MapperProxy 的 invoke()方法。
问题1:我们引入MapperProxy为了解决什么问题?硬编码和编译时检查问题。它 需要做的事情是:根据方法查找Statement ID的问题。
问题2 :进入到invoke方法的时候做了什么事情?它是怎么找到我们要执行的SQL
的?
我们看一下invoke方法:
8.1.MapperProxy. invoke()
1 )首先判断是否需要去执行SQ L,还是直接执行方法。Object本身的方法不需要
去执行 S Q L,比如 toString、hashCode、equals、getClass()
2 )获取缓存
这里加入缓存是为了提升MapperMethod的获取速度。很巧妙的设计。缓存的使 用在MyBatis中随处可见。
// 获取缓存,保存了方法签名和接口方法的关系
final MapperMethod mapperMethod = cachedMapperMethod(method);
Map的 computelfAbsent()方法:根 据 key获取值,如果值是n u ll,则把后面 Object的值赋给key。
Java8和 Java9 中的接口默认方法有特殊处理,返回DefaultMethodlnvoker。
普通的方法返回的是PlainMethodlnvoker,返回MapperMethod。
MapperMethod中有两个主要的属性:
private final SqlCommand command;
private final MethodSignature method;
一个 是 SqlCommand , 封 装 了 statement id ( 例 如 : com.gupaoedu.mapper.BlogMapper.selectBlogByld)和 SQL 类型。
—个是Methodsignature,主要是主要封装是返回值的类型。
这两个属性都是MapperMethod的内部类。
另外MapperMethod种定义了多种executeQ方法。
8.2.MapperMethod. execute()
接下来又调用了 mapperMethod的 execute方法:
mapperMethod.execute(sqlSession, args);

在这一步,根据不同的type (INSERT. UPDATE. DELETE. SELECT)和返回类型:
-
调用convertArgsToSqlCommandParam。将方法参数转换为SQL的参数。
-
调用 sqISession 的 insert、update、delete、selectOne ()方法。我们以
查询为例,会走到selectOne。方法。
Object param = method. convertArgsToSqlCommandParam( args);
result = sqISession.selectOne(command.getName(), param);
8.3.DefaultSqlSession. selectOne()
这里来到了对外的接口的默认实现类DefaultSqlSession。
selectOne()最终也是调用了 selectList()
@Override
public <T> T selectOne(String statement, Object parameter) {
// 来到了 DefaultSqlSession
// Popular vote was to return null on 0 results and throw exception on too many.
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
在 SelectList中,我们先根据 command name (Statement ID)从 Configuration 中拿到MappedStatemento ms里面有xml中增删改查标签配置的所有属性,包括id、 statementType、sqISource、useCache.入参、出参等等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o45uDS8S-1589355509899)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510205703683.png)]
然后执行了 Executor的 query方法。
Executor是第二步openSession的时候创建的,创建了执行器基本类型之后,依次执行了二级缓存装饰,和插件拦截。
所以,如果有被插件拦截,这里会先走到插件的逻辑。如果没有显式地在settings
中配置cacheEnabled=false,再走到CachingExecutor的逻辑,然后会走到BaseExecutor 的 query方法。
8.4.CachingExecutor. query()
1 ) 创建 CacheKey
二级缓存的CacheKey是怎么构成的呢?或者说,什么样的查询才能确定是同一个
查询呢?
在 BaseExecutor的 createCacheKey方法中,用到了六个要素:
cacheKey.update(ms.getId()); // com.gupaoedu.mapper.BlogMapper.selectBlogById
cacheKey.update(rowBounds.getOffset()); // 0
cacheKey.update(rowBounds.getLimit()); // 2147483647 = 2^31-1
cacheKey.update(boundSql.getSql());
也就是说,方法相同、翻页偏移相同、SQL相同、参数值相同、数据源环境相同,
才会被认为是同一个查询。
CacheKey的实际值举例(toString生成的),debug可以看到:
// -1381545870:4796102018:com.gupaoedu.mapper.BlogMapper.selectBlogById:0:2147483647:select * from blog where bid = ?:1:development
注意看一下CacheKey的属性,里面有一个List按顺序存放了这些要素。
private static final int DEFAULT_MULTIPLIER = 37;
private static final int DEFAULT_HASHCODE = 17;
private final int multiplier;
private int hashcode;
private long checksum;
private int count;
// 8/21/2017 - Sonarlint flags this as needing to be marked transient. While true if content is not serializable, this is not always true and thus should not be marked transient.
private List<Object> updateList;
怎么比较两个CacheKey是否相等呢?如果一上来就是依次比较六个要素是否相等, 要比较6次,这样效率不高。有没有更高效的方法呢?继承Object的每个类,都有一个 hashCode ()方法,用来生成哈希码。它是用来在集合中快速判重的。
在生成CacheKey的时候(update方 法 ),也更新了 CacheKey的 hashCode,它 是用乘法哈希生成的(基数baseHashCode=17 ,乘法因子multiplier=37 )。
hashcode = multiplier * hashcode + baseHashCode;
Object中的hashCode。是一个本地方法,通过随机数算法生成(OpenJDK8 , 默 认,可以通过-XX:hashCode修 改 )。CacheKey中的hashCodeQ方法进行了重写,返 回自己生成的hashCode。
为什么要用37作为乘法因子呢?跟 String中的31类似。
CacheKey中的equals也进行了重写,比较CacheKey是否相等。
@Override
public boolean equals(Object object) {
// 同一个对象
if (this == object) {
return true;
}
// 被比较的对象不是 CacheKey
if (!(object instanceof CacheKey)) {
return false;
}
final CacheKey cacheKey = (CacheKey) object;
// hashcode 不相等
if (hashcode != cacheKey.hashcode) {
return false;
}
// checksum 不相等
if (checksum != cacheKey.checksum) {
return false;
}
// count 不相等
if (count != cacheKey.count) {
return false;
}
for (int i = 0; i < updateList.size(); i++) {
Object thisObject = updateList.get(i);
Object thatObject = cacheKey.updateList.get(i);
if (!ArrayUtil.equals(thisObject, thatObject)) {
return false;
}
}
return true;
}
如果哈希值(乘法哈希)、校验值(加法哈希)、要素个数任何一个不相等,都不
是同一个查询,最后才循环比较要素,防止哈希碰撞。
CacheKey生成之后,调用另一个query方法。
2)处理二级缓存
首先从ms中取出cache对象,判断cache对象是否为空,如果为空,则没有查询 二级缓存、写入二级缓存的流程。
Cache cache = ms.getCache();
// cache 对象是在哪里创建的? XMLMapperBuilder类 xmlconfigurationElement()
// 由 <cache> 标签决定
if (cache != null) {
}
Cache对象是什么时候创建的呢?
用来解析 Mapper.xml 的 XMLMapperBuilder 类,cacheElement方法:
cacheElement(context.evalNode("cache"));
只有Mapper.xml中的<cache>标签不为空才解析。
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
此处创建了一个Cache对象。
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
大家可以自行验证一下,注释<cache>,是否不解析,cache是否为null。开启
<cache>,是否解析,cache是否不为null。
二级缓存为什么要用TCM来管理?
我们来思考一个问题,在一个事务中:
1、 首先插入一条数据(没有提交),此时二级缓存会被清空。
2、 在这个事务中查询数据,写入二级缓存。
3、 提交事务,出现异常,数据回滚。
此时出现了数据库没有这条数据,但是二级缓存有这条数据的情况。所以MyBatis 的二级缓存需要跟事务关联起来。
疑问:为什么一级缓存不这么做?
因为一个session就是一个事务,事务回滚,会话就结束了,缓存也清空了,不存 在读到一级缓存中脏数据的情况。二级缓存是跨session的,也就是跨事务的,才有可 能出现对同一个方法的不同事务访问。
1 )写入二级缓存
tcm.putObject(cache, key, list);
从 map中拿出TransactionalCache对象,把 value添加到待提交的Map。 此时缓
存还没有真正地写入。
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
只有事务提交的时候缓存才真正写入(close或者commit最后分析)。
2 ) 获取二级缓存
List<E> list = (List<E>) tcm.getObject(cache, key);
从 map中拿出TransactionalCache对象,这个对象也是对PerpetualCache经过
层层装饰的缓存对象:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z0vamVCH-1589355509900)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510212633616.png)]
得到再getObject(), 这个是一个会递归调用的方法,直到到达PerpetualCache,
拿到value。
public Obj ect getObject(Object key) {
return cache.get(key);
}
8.5.BaseExecutor.query ()
1)清空本地缓存
querystack用于记录查询栈,防止递归查询重复处理缓存。
flushCache=true的时候,会先清理本地缓存(—级缓存):
if (queiyStack == 0 && msJsFlushCacheReqiiiredO) {
clearLocalCache();
}
如果没有缓存,会从数据库查询:queryFromDatabase
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
如果 LocalCacheScope == STATEMENT,会清理本地缓存。
2)从数据库查询
a)缓存
先在缓存用占位符占位。执行查询后,移除占位符,放入数据。
localCache.putObject(key, EXECUTION_PLACEHOLDER);
b)查询
执行 Executor 的 doQuery; 默认是 SimpleExecutor
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
8.6.SimpleExecutor. doQuery
1)创建 StatementHandler
在 configuration.newStatementHandler(), new—个 StatementHandler, 先 得到 RoutingStatementHandler
RoutingStatementHandler里 面 没 有 任 何 的 实 现 ,是 用 来 创 建 基 本 的 StatementHandler 的。这里会根据 MappedStatement 里面的 statementType 决定 StatementHandler 的 类 型 。 默认是 PREPARED ( STATEMENT. PREPARED、
CALLABLE)
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// StatementType 是怎么来的? 增删改查标签中的 statementType="PREPARED",默认值 PREPARED
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
// 创建 StatementHandler 的时候做了什么? >>
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
StatementHandler里面包含了处理参数的ParameterHandler和处理结果集的
ResultSetHandler
这两个对象都是在上面new的时候创建的。
// 创建了四大对象的其它两大对象 >>
// 创建这两大对象的时候分别做了什么?
this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
}
这三个对象都是可以被插件拦截的四大对象之一,所以在创建之后都要用拦截器进
行包装的方法。
// 植入插件逻辑(返回代理对象)
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
// 植入插件逻辑(返回代理对象)
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
// 植入插件逻辑(返回代理对象)
resultSetHandler = (ResultSetHandler) interceptorChain.pluginAll(resultSetHandler);
至此,四大对象的包装已经全部完成。
P S :四大对象还有一个是谁?在什么时候创建的? (Executor)
2 ) 创建 Statement
用 new 出来的 StatementHandler 创建 Statement 对象。
如果有插件包装,会先走到被拦截的业务逻辑。
// 用Connection创建一个Statement
stmt = handler.prepare(connection, transaction.getTimeout());
prepareStatement()方法对语句进行预编译,处理参数:
handler.parameterize(stmt);
这里面会调用parameterHandler设置参数,如果有插件包装,会先走到被拦截的
业务逻辑。
@Override
public void parameterize(Statement statement) throws SQLException {
delegate.parameterize(statement);
}
执行的 StatementHandler 的 query方法
RoutingStatementHandler 白勺 query方法 。 delegate 委派,最终执行 PreparedStatementHandler 的 query()方法。
4 ) 执行 PreparedStatement 的 execute方法
后面就是JDBC包中的PreparedStatement的执行了。
- ResultSetHandler 处理结果集
如果有插件包装,会先走到被拦截的业务逻辑。
return resultSetHandler.handleResultSets(ps);
问题:怎么把ResultSet转换成List<Object>?
ResultSetHandler 只有一个实现类:DefaultResultSetHandler。也就是执行 DefaultResultSetHandler 的 handleResultSets ()方法。
首先我们会先拿到第一个结果集,如果没有配置一个查询返回多个结果集的情况,
—般只有一个结果集。如果下面的这个while循环我们也不用,就是执行一次。
然后会调用handleResultSet方法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vXDz17MO-1589355509903)(https://hexo-1257630696.cos.ap-singapore.myqcloud.com/img/image-20200510214703265.png)]
9.MyBatis核心对象
参考资料:
1.咕泡学院·MyBatis体系结构与工作原理·青山