1-排序简单介绍
排序:将无序键重新排列,使之有序
键集:键的集合,这里默认待排序的数据都是唯一的,即不存在重复数据,这是一种理想情况,通常不作为重点
有序:升序和降序
内排序和外排序:内存数据排序和外存数据排序(通常外排序是通过调入内存中实现排序)
稳定性:假设某次待排序的数据中,存在相同数据,排序前其物理顺序与排序后物理顺序不变,即对于所有数据,任意排序,只要依然用这种算法,其顺序是不会改变的
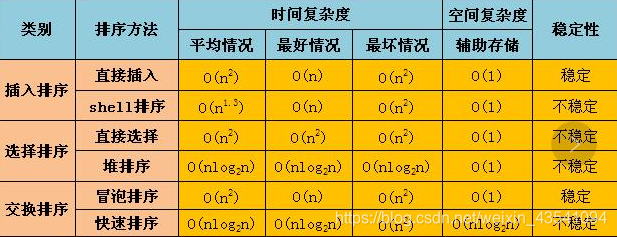
三大类六种排序算法:
(1):直接插入排序,希尔排序
(2):直接选择排序,堆排序(利用完全二叉树)
(3):直接交换排序(冒泡排序),快速排序
对每一种排序算法,通常需要从下面几个方面研究:
(1):算法
(2):C代码的实现
(3):算法的时间复杂度
(4):算法的极端效率分析(最优情况,最劣情况)
(5):稳定性分析
2-直接插入排序
for (i = 1; i < count; i++) {
tmp = data[i];
for (j = 0; j < i && tmp >= data[j]; j++) {
}
for (t = i; t > j; t--) {
data[t] = data[t - 1];
//在j ~ i-1内的所有元素从后向前依次后移一位
}
data[j] = tmp;
}
}

3- 直接选择排序
for (i = 0; i < count - 1; i++) {
minIndex = i;
for (j = i; j < count; j++) {
if (data[j] < data[minIndex]) {
minIndex = j;
}
}
if (minIndex != i) {
tmp = data[i];
data[i] = data[minIndex];
data[minIndex] = tmp;
}
}

4-直接交换排序(冒泡排序)
int hasSwap = 1;
for (i = 0; hasSwap && i < count - 1; i++) {
hasSwap = 0;
for (j = 0; j < count - i - 1; j++) {
if (data[j] > data[j+1]) {
tmp = data[j];
data[j] = data[j+1];
data[j+1] = tmp;
hasSwap = 1;
}
}
}
对一组待排序数,每次相邻的两个数比较,这两个数中,将数值大的放在后面,数值小的交换到前面,第一轮交换结束后,最后一个数就是待排序数列中的最大数,第二轮后,倒数第二个数就是第二大的数,直到只剩下一个数时停止
5- 希尔排序(改良的直接插入排序)
void shellOneSort(int *data, int count, int start, int step) {
int i;
int j;
int t;
int tmp;
for(i = start + step; i < count; i+=step) {
//每次将下标为start+=step的元素放入一组
tmp = data[i];
for(j = start; j < i && tmp >= data[j]; j += step){
//本组开始进行直接插入排序
; //遍历依次找到合适位置
}
for(t = i; t > j; t -= step) {
//要交换的两个值中间间距为step
data[t] = data[t - step];
//则这两个值中间的元素依次后移step位
}
data[j] = tmp;
}
}
void shellSort(int *data, int count) {
int start;
int step;
for(step = count/2; step; step/2) {
//计算step,step不能小于0
for(start = 0; start < step; start++) {
//控制分组的次数,step为几,就有几个start
shellOneSort(data, count, start, step);
//若干个start,每次对一组直插排序
}
}
}

直接插入排序是步长为1的希尔排序
6-堆排序(改良的直接选择排序)
堆排序基于直接选择排序,使用了完全二叉树的概念
基于 大根堆(升序) 小根堆(降序) 完成排序
大根堆:一颗完全二叉树,它的任意一个非子叶结点的值,都比其左右子树中的最大值都大(小根堆参考此概念)
事实上,任意一个连续的,有n个元素的一维数组,都可以看成一颗完全二叉树,且存在如下特点:(在下标为0的前提下)
若某个非子叶结点的下标为 i:则其左孩子下标为 2 * i + 1,
右孩子下标为 2 * i + 2,下标最大的非子叶结点下标值为 n / 2 - 1
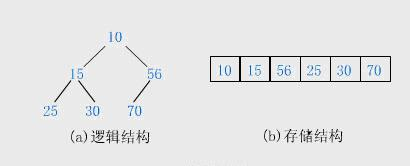
用大根堆排序的过程:
1-将数组内数据依次插入完全二叉树中,建立一个大根堆
2-将大根堆进行调整,直到满足:父结点的值一定大于左右孩子的值
3-将最后一个子叶结点的数与最大值(最上面的根结点)互换位置,并将最大数所在的子叶结点从大根堆中取出
4-取出后,继续调整大根堆,执行第二步,让大数先上浮,小数下沉
调整结束后,再执行第三步,直到排序完成
初始化一个大根堆
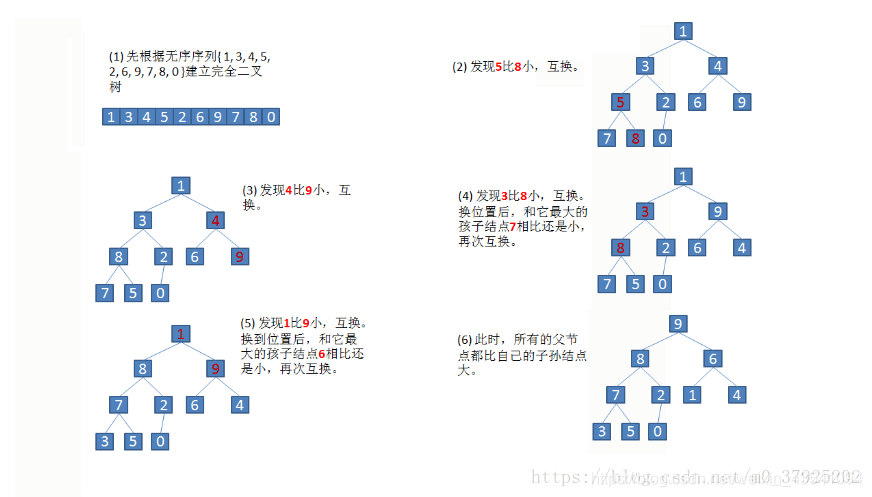
用大根堆完成堆排序

void adjustHeap(int *data,int count, int root) {
int left;
int right;
int maxNode;
int tmp;
while(root <= count/2 - 1) {
// count/2-1是编号最大的非子叶结点,
//包括它和比它大的都是非子叶结点
left = 2*root - 1;
right = left + 1;
//该非子叶节点的左右孩子下标
maxNode = right >= count ? left
:(data[left] > data[right]
? left : right);
//比较某非子叶结点左右孩子大小,右孩子下标不可能大于等于count
//就是左孩子为最大,或比较值,输出值较大的下标
maxNode = data[root] > data[maxNode]
? root : maxNode;
//比较该非子叶节点的值和maxNode,确定新的maxNode
if(maxNode == root) {
return;
//非子叶结点的值为最大值,则什么也不做
}
tmp = data[root];
data[root] = data[maxNode];
data[maxNode] = tmp;
//若非子叶点值较小,则交换值
root = maxNode;
//令新的非子叶结点的值为maxNode
//data[0]是根结点,此处root意为每次进行判断的非子叶结点
}
}
void headSort(int *data, int count) {
int root;
int tmp;
for(root = count / 2 - 1; root > 0; root--){
adjustHeap(data, count, root);
//从最后一个非子叶结点向上遍历
//直到只剩最上面的一个元素,
//每次adjust该结点的值及其左右孩子的值,
//令大的值上浮,小的值下沉
};
while(count) {
adjustHeap(data, count, 0);
//此时调整最上面元素的值变为最大值
tmp = data[0];
data[0] = data[count - 1];
//取出当前数组末尾子叶结点的小值
data[count - 1] = tmp;
//将本次取出的最大数放入数组最后面
--count;
//每次得到一个最大值后,
//去掉一个最后面的子叶结点
//数组长度减一
}
}
7- 快速排序
void quickOnce(int *data, int count, int head, int tail) {
int tmp = data[head];
int start = head;
int end = tail;
if (head >= tail) {
return;
}
while (head < tail) {
while (head < tail && data[tail] >= tmp) {
--tail;
}
if (head < tail) {
data[head] = data[tail];
++head;
}
while (head < tail && data[head] <= tmp) {
++head;
}
if (head < tail) {
data[tail] = data[head];
--tail;
}
}
data[head] = tmp;
//确定第一次当作基准数的位置
quickOnce(data, count, start, head - 1);
quickOnce(data, count, head + 1, end);
//对当前tmp左右的两组数再进行递归快排,
//直到若干组数每组数只剩两个
}
void qucikSort(int *data, int count) {
quickOnce(data, count, 0, count - 1);
}

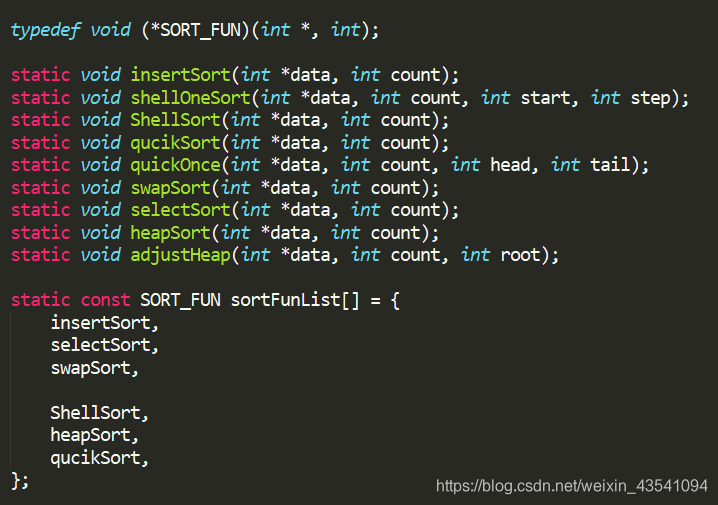
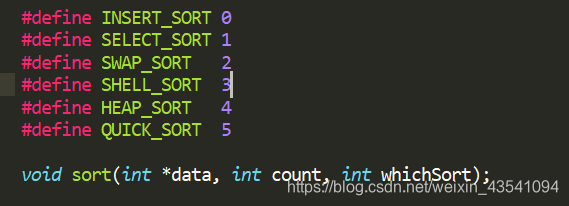
8- 排序整合
通过指向函数的指针,定义一个数组存放排序类型,并用宏定义好排序名,在使用时,输入排序方式所对应的下标,可以很方便的使用