2020/12/5 [email protected]
一、hadoop伪分布式集群搭建
一台全新的CentOS_6.5虚拟机
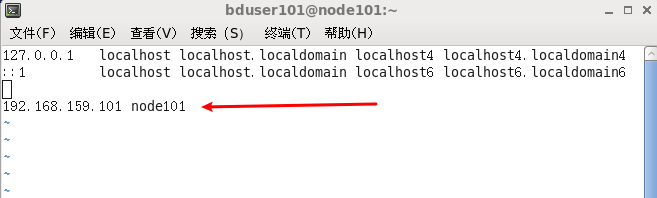
1.1、添加主机名称(ip空格机器名)
[bduser101@node101 .ssh]$ sudo vi /etc/hosts
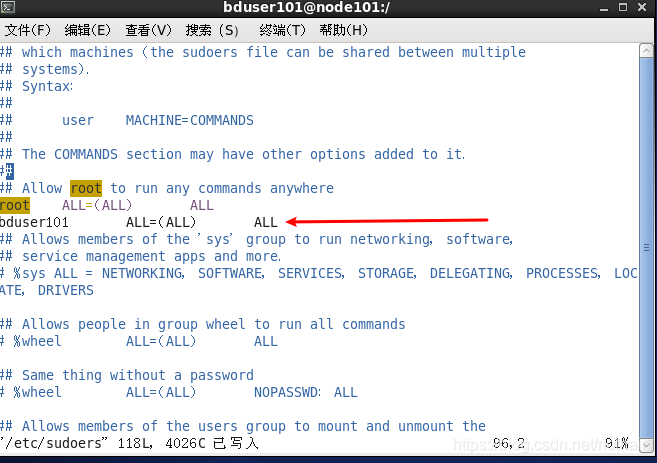
1.2、为当前用户bduser101赋予root权限
[bduser101@node101 .ssh]$ su
密码:
[root@node101 .ssh]# vim /etc/sudoers
1.3、设置ssh无密登录
[bduser101@node101 ~]$cd ~
[bduser101@node101 ~]$ ssh-keygen -t rsa -P ''
#验证密钥创建成功的方法
[bduser101@node101 ~]$ cd .ssh
[bduser101@node101 .ssh]$ ll
总用量 8
-rw-------. 1 bduser101 bduser101 1675 3月 13 20:22 id_rsa
-rw-r--r--. 1 bduser101 bduser101 399 3月 13 20:22 id_rsa.pub
#将公钥写入authorized_keys文件
[bduser101@node101 .ssh]$ cat id_rsa.pub >> authorized_keys
[bduser101@node101 .ssh]$ ll
总用量 12
-rw-rw-r--. 1 bduser101 bduser101 399 3月 13 20:22 authorized_keys
-rw-------. 1 bduser101 bduser101 1675 3月 13 20:22 id_rsa
-rw-r--r--. 1 bduser101 bduser101 399 3月 13 20:22 id_rsa.pub
[bduser101@node101 .ssh]$ chmod 600 authorized_keys
#将以下文件的 47,48,49行的注释去掉
[bduser101@node101 .ssh]$ sudo vim /etc/ssh/sshd_config
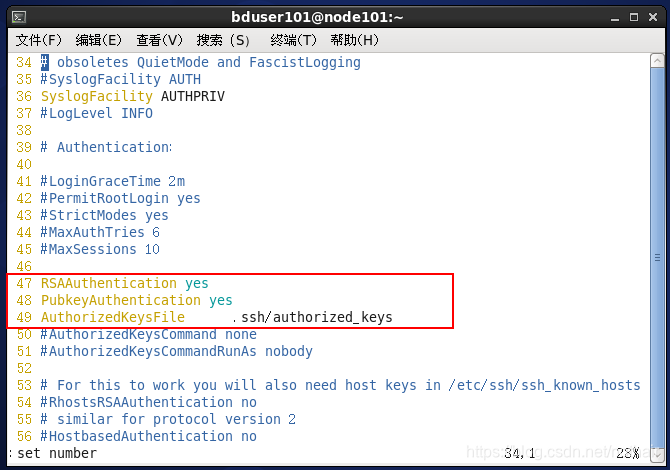
重启sshd服务
[bduser101@node101 .ssh]$ sudo service sshd restart
运行以下代码确定ssh无密登录的成功
[bduser101@node101 ~]$ ssh node101
Last login: Fri Mar 13 22:15:00 2020 from 192.168.159.99
1.4、关闭防火墙,并将默认状态改为关闭
[bduser101@node101 modules]$ sudo service iptables stop
iptables:将链设置为政策 ACCEPT:filter [确定]
iptables:清除防火墙规则: [确定]
iptables:正在卸载模块: [确定]
[bduser101@node101 modules]$ sudo chkconfig iptables off
1.5、准备好jdk、hadoop压缩包
jdk版本是8.10
hadoop版本是2.7.6
点此进入Hadoop各版本下载地址
 进入下载界面点击箭头位置下载并保存到本地
进入下载界面点击箭头位置下载并保存到本地
- 在虚拟机的home/bduser101下创建两个文件夹
software :用来存放准备的压缩包
modules :解压后的文件存放位置 - 借助MobaXterm工具将jdk、hadoop压缩包复制到software文件夹下
- 将jdk、hadoop压缩包解压至modules
[bduser101@node101 ~]$cd ~
[bduser101@node101 ~]$cd software
[bduser101@node101 software]$tar -zxvf jdk-8u144-linux-x64.tar.gz -C ../modules/
#解压过程
[bduser101@node101 software]$tar -zxvf hadoop-2.7.6.tar.gz -C ../modules/
#解压过程
[bduser101@node101 software]$cd ~/modules
#将jdk和hadoop冗长的名称改为简写
[bduser101@node101 modules]$mv jdk1.8.0_144/ jdk
[bduser101@node101 modules]$mv hadoop-2.7.6.tar.gz/ hadoop
- 配置java、hadoop的环境变量
[bduser101@node101 modules]$cd ~
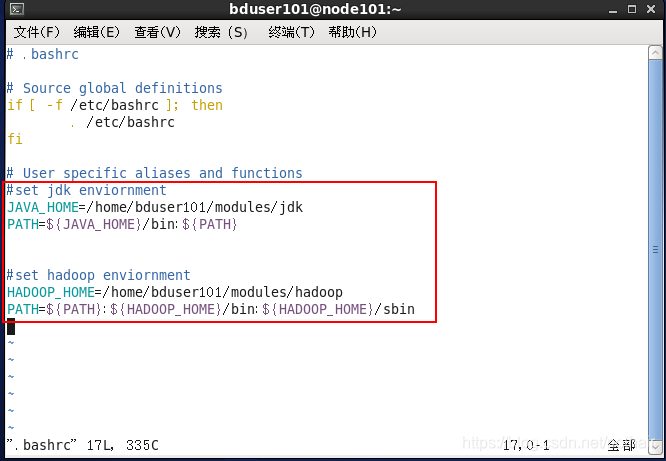
[bduser101@node101 ~]$ vi .bashrc
#在文件中加入以下内容
(JAVA_HOME,HADOOP_HOME的值因虚拟机的当前用户不同所以地址值不同,大体应该为/home/当前用户名/modules/jdk或者/hadoop)
验证java,hadoop环境变量是否成功
[bduser101@node101 ~]$resource .bashrc
[bduser101@node101 ~]$java -version
#显示jdk版本号
[bduser101@node101 ~]$hadoop version
#显示hadoop版本号
1.6、修改配置文件
- 修改/home/bduser101/modules/hadoop/etc/hadoop/中的6个文件
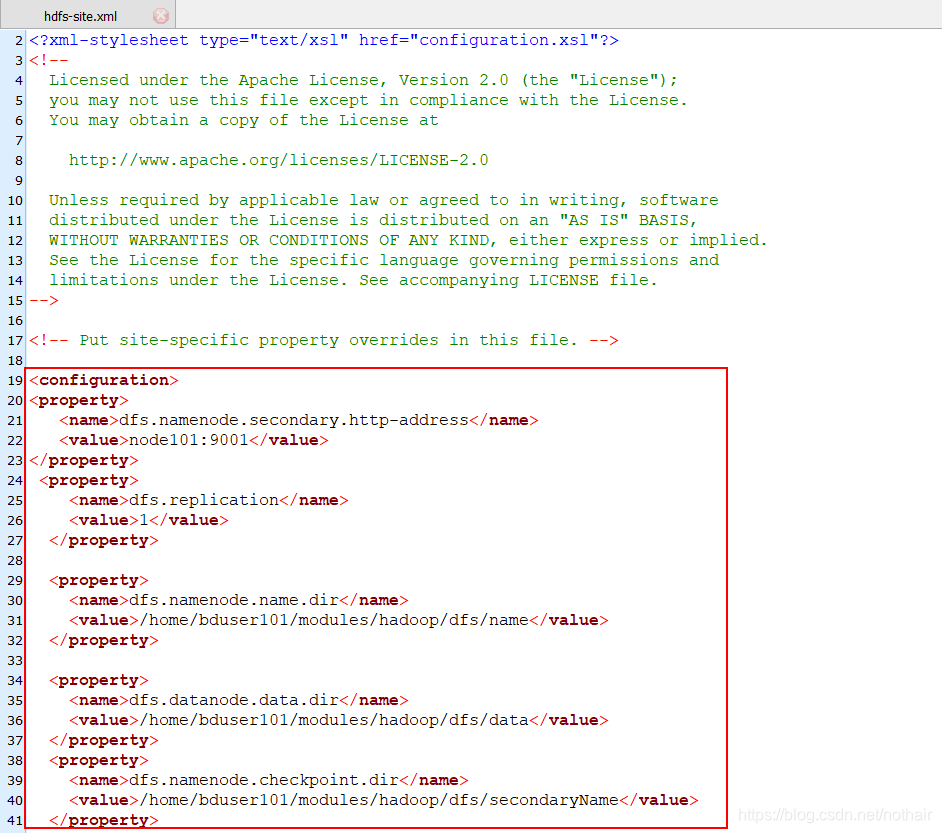
1.hdfs-site.xml
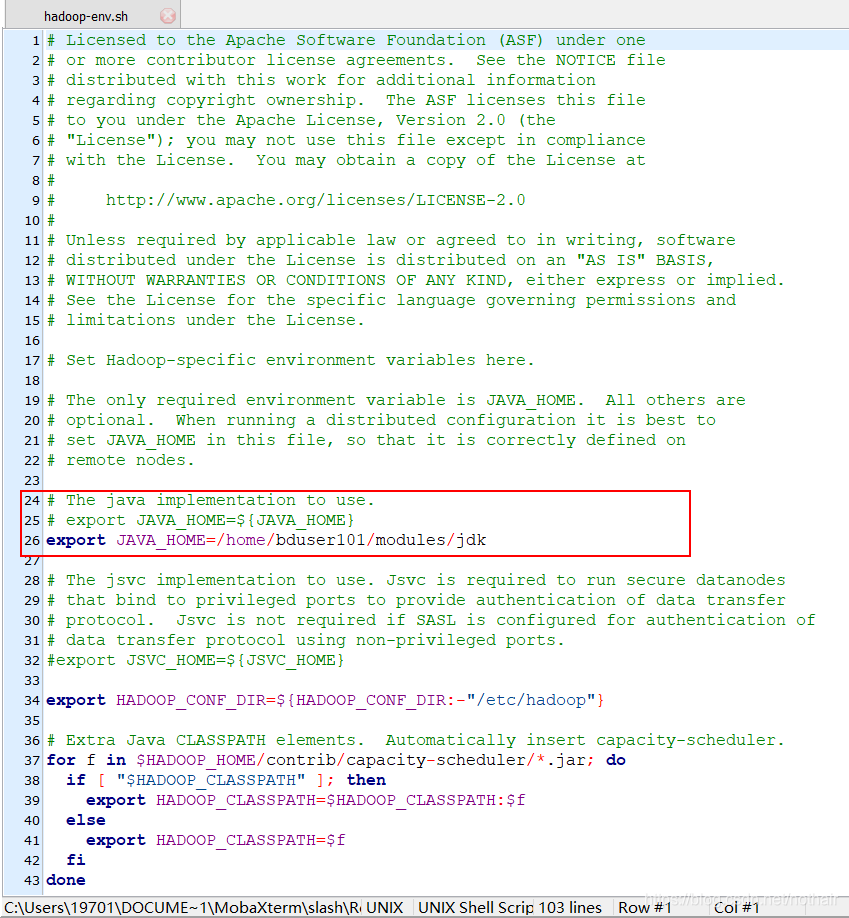
2.hadoop-env.sh
3.core-site.xml

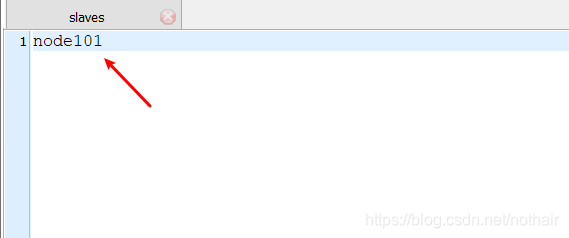
4.slaves
5.yarn-site.xml
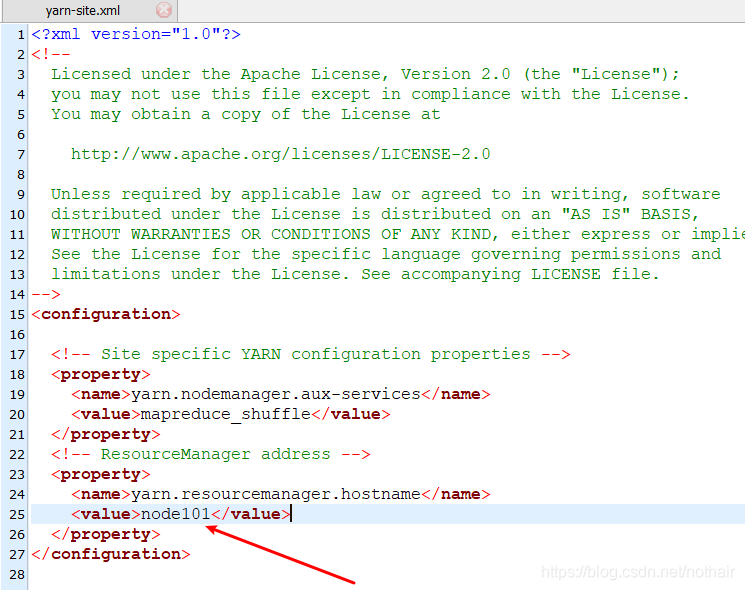
6.mapred-site.xml
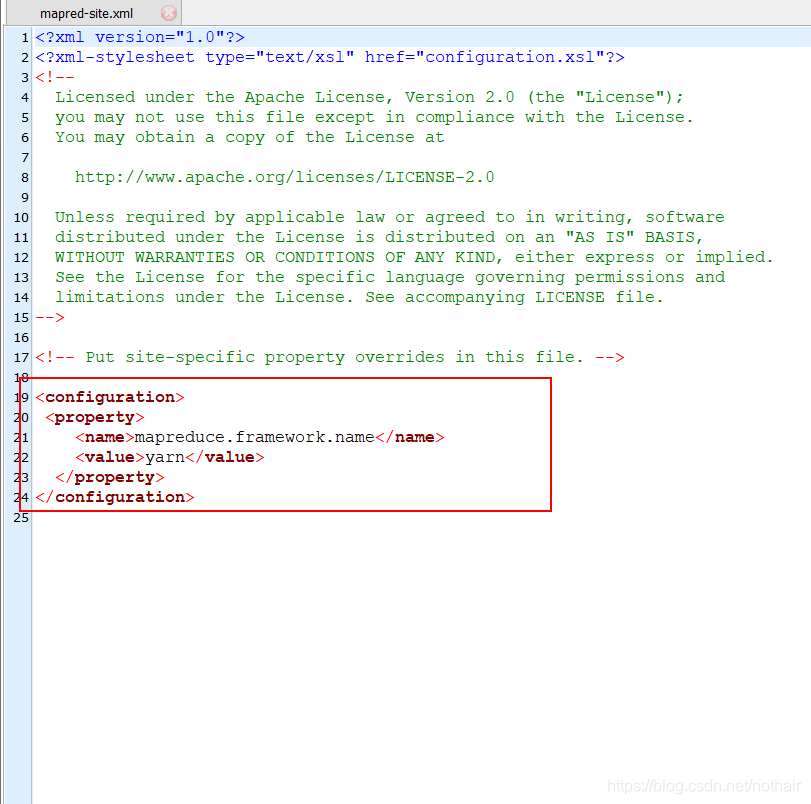
- 格式化namenode(第一次启动集群之前格式化)
1.7、格式化namenode(第一次启动集群之前格式化)
[bduser101@node101 modules]$ hadoop namenode -format
验证格式化成功
[bduser101@node101 modules]$cd /home/bduser101/modules/hadoop
[bduser101@node101 hadoop]$ ls
bin dfs etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[bduser101@node101 hadoop]$ cd dfs
[bduser101@node101 dfs]$ ls
name
- 启动集群
[bduser101@node101 ~]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [node101]
node101: starting namenode, logging to /home/bduser101/modules/hadoop/logs/hadoop-bduser101-namenode-node101 .out
node101: starting datanode, logging to /home/bduser101/modules/hadoop/logs/hadoop-bduser101-datanode-node101 .out
Starting secondary namenodes [node101]
node101: starting secondarynamenode, logging to /home/bduser101/modules/hadoop/logs/hadoop-bduser101-seconda rynamenode-node101.out
starting yarn daemons
starting resourcemanager, logging to /home/bduser101/modules/hadoop/logs/yarn-bduser101-resourcemanager-node 101.out
node101: starting nodemanager, logging to /home/bduser101/modules/hadoop/logs/yarn-bduser101-nodemanager-nod e101.out
验证集群启动成功
[bduser101@node101 ~]$ jps
3217 SecondaryNameNode
3057 DataNode
3362 ResourceManager
2930 NameNode
3462 NodeManager
3754 Jps
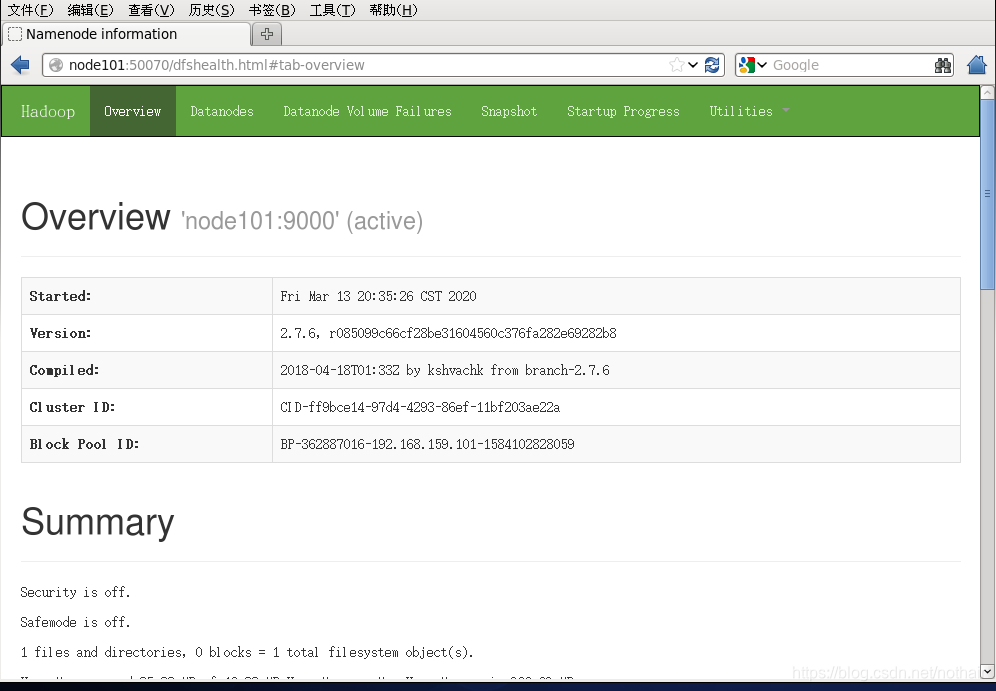
- 在虚拟机中打开火狐浏览器在地址栏输入:node101:50070,出现如下界面则表示伪分布集群搭建成功,如果不能查看,看友情贴处理http://www.cnblogs.com/zlslch/p/6604189.html
二、hadoop完全分布式集群搭建
- 传统使用iso镜像的方式创建多个节点
- 以完整的原型机为基础,做克隆
本文使用的方法为第二种:对已经进行伪分布式的机器(node101)进行克隆两次
2.1、创建节点
鼠标右键伪分机器->管理->克隆->虚拟机中的当前状态->创建完整克隆->填写虚拟机名称以及选择虚拟机存储位置
直接克隆出两台机器,分别命名为node102、node103

2.2、网络配置(node102,node103)
- 2.1把eth0网卡行注释掉,然后把eth1改成eth0,复制当前eth0里的mac地址
[bduser101@node102 ~]$ su root
密码:
[root@node102 bduser101]# vi /etc/udev/rules.d/70-persistent-net.rules

- 2.2把mac地址粘贴至图示位置,修改ip地址为192.168.159.102
[root@node102 bduser101]# vi /etc/sysconfig/network-scripts/ifcfg-eth0

- 2.3重启网卡
[root@node102 bduser101]# service network restart
正在关闭接口 eth0: 设备状态:3 (断开连接)
[确定]
关闭环回接口: [确定]
弹出环回接口: [确定]
弹出界面 eth0: 活跃连接状态:激活的
活跃连接路径:/org/freedesktop/NetworkManager/ActiveConnection/2
[确定]
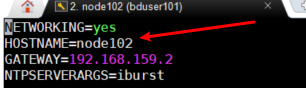
2.3、修改主机名(node102,node103)
修改HOSTNAME为当前机器名
[root@node102 bduser101]# vi /etc/sysconfig/network
2.4、在主节点(node101)创建两个脚本
[bduser101@node101 bin]$ su root
[root@node101 ~]$ cd /usr/local/bin/
[root@node101 ~]$ touch xcall
[root@node101 ~]$ touch xsync
[root@node101 ~]$ chmod a+x xcall
[root@node101 ~]$ chmod a+x xsync
[root@node101 ~]$ vi xcall
- 在xcall文件中填写如下代码
该脚本的作用是在主节点就可以对其余节点执行操作命令
for循环中的host=102;host<=103是指对那些节点进行操作,如果你的机器名不是node102,node103,就需要修改for循环
#!/bin/bash
pcount=$#
if((pcount==0));then
echo no args;
exit;
fi
echo --------localhost----------
$@
for((host=102; host<=103; host++)); do
echo ----------node$host---------
ssh node$host $@
done
使用样例xcall jps查看所有节点当前运行的进程
- 在xsync文件中填写如下代码
该脚本的作用是将带有绝对路径的文件或者文件夹同步到for循环中的机器中,同样如果机器名不同需要修改for循环中的内容
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=102; host<=103; host++)); do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- node$host ----------------
echo rsync -rvl $pdir/$fname $user@node$host:$pdir
rsync -rvl $pdir/$fname $user@node$host:$pdir
done
使用样例xsync /etc/hosts:将/etc/hosts文件同步至node102,node103的相同位置下
2.5、修改映射关系
vim /etc/hosts
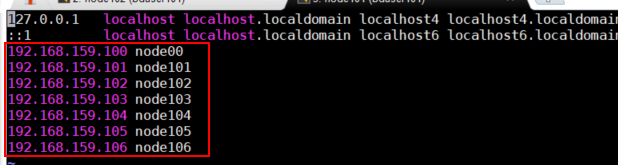
使用xsync脚本进行同步[root@node101 bin]# xsync /etc/hosts
2.6、修改hadoop配置文件(node101)
[bduser101@node101 ~]$ cd ~/modules/hadoop/etc/hadoop/
[bduser101@node101 ~]$ vi 以下几个文件
- 6.1 slaves:设置dataNode位置

- 6.2hdfs-site.xml

使用xsync脚本同步配置xsync ~/modules/hadoop/etc/hadoop
2.7、格式化(node101)
[bduser101@node101 hadoop]$ hadoop namenode -format
2.8、启动服务(node101)
[bduser101@node101 hadoop]$ start-all.sh
使用xcall查看所有节点进程
[bduser101@node101 hadoop]$ xcall jps
--------localhost----------
2800 NameNode
2914 DataNode
3622 Jps
3192 ResourceManager
3305 NodeManager
----------node102---------
3495 NodeManager
3627 Jps
3375 DataNode
----------node103---------
2546 Jps
2322 SecondaryNameNode
2212 DataNode
2405 NodeManager
注意所有节点需要关闭防火墙以及时间同步