1.1 HDFS文件系统中的三个角色:
- NameNode:主节点,存元数据,全局只有一个。
- DataNode:数据节点,存真实数据,全局可以有无限个。
- SecondoryNameNode:主节点备份节点,备份元数据,全局只有一个。
(以上节点的功能作用会在后续博客中更新 +关注)
1.2 伪分布搭建(一台机器充当所有节点)
一台全新的CentOS_6.5虚拟机
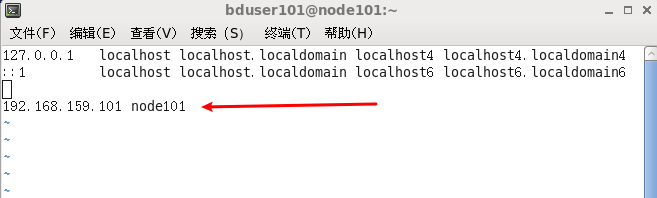
- 添加主机名称(ip空格机器名)
[bduser101@node101 .ssh]$ sudo vi /etc/hosts
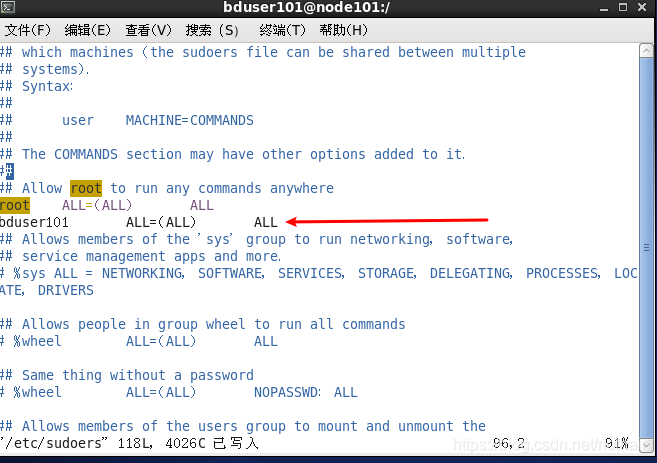
- 为当前用户bduser101赋予root权限
[bduser101@node101 .ssh]$ su
密码:
[root@node101 .ssh]# vim /etc/sudoers
- 设置ssh无密登录
[bduser101@node101 ~]$cd ~
[bduser101@node101 ~]$ ssh-keygen -t rsa -P ''
#验证密钥创建成功的方法
[bduser101@node101 ~]$ cd .ssh
[bduser101@node101 .ssh]$ ll
总用量 8
-rw-------. 1 bduser101 bduser101 1675 3月 13 20:22 id_rsa
-rw-r--r--. 1 bduser101 bduser101 399 3月 13 20:22 id_rsa.pub
#将公钥写入authorized_keys文件
[bduser101@node101 .ssh]$ cat id_rsa.pub >> authorized_keys
[bduser101@node101 .ssh]$ ll
总用量 12
-rw-rw-r--. 1 bduser101 bduser101 399 3月 13 20:22 authorized_keys
-rw-------. 1 bduser101 bduser101 1675 3月 13 20:22 id_rsa
-rw-r--r--. 1 bduser101 bduser101 399 3月 13 20:22 id_rsa.pub
[bduser101@node101 .ssh]$ chmod 600 authorized_keys
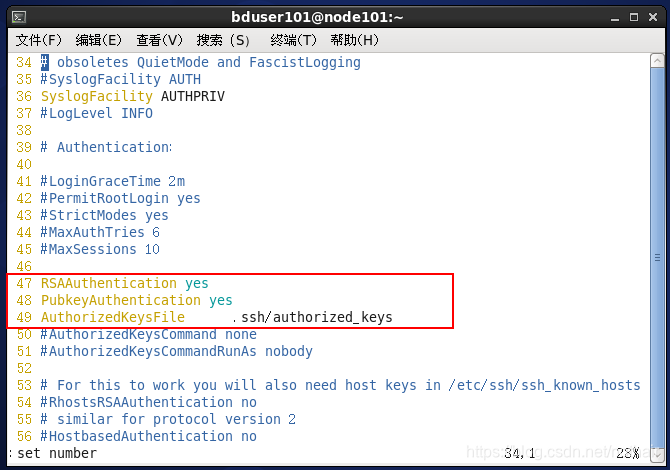
#将以下文件的 47,48,49行的注释去掉
[bduser101@node101 .ssh]$ sudo vim /etc/ssh/sshd_config
重启sshd服务
[bduser101@node101 .ssh]$ sudo service sshd restart
运行以下代码确定ssh无密登录的成功
[bduser101@node101 ~]$ ssh node101
Last login: Fri Mar 13 22:15:00 2020 from 192.168.159.99
- 关闭防火墙,并将默认状态改为关闭
[bduser101@node101 modules]$ sudo service iptables stop
iptables:将链设置为政策 ACCEPT:filter [确定]
iptables:清除防火墙规则: [确定]
iptables:正在卸载模块: [确定]
[bduser101@node101 modules]$ sudo chkconfig iptables off
- 准备好jdk、hadoop压缩包
jdk版本是8.10
hadoop版本是2.7.6
点此进入Hadoop各版本下载地址
 进入下载界面点击箭头位置下载并保存到本地
进入下载界面点击箭头位置下载并保存到本地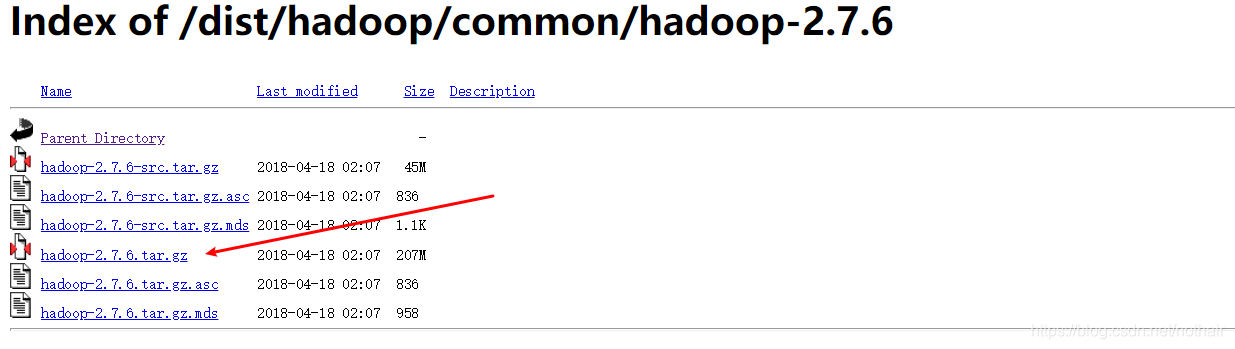
- 在虚拟机的home/bduser101下创建两个文件夹
software :用来存放准备的压缩包
modules :解压后的文件存放位置 - 借助MobaXterm工具将jdk、hadoop压缩包复制到software文件夹下
- 将jdk、hadoop压缩包解压至modules
[bduser101@node101 ~]$cd ~
[bduser101@node101 ~]$cd software
[bduser101@node101 software]$tar -zxvf jdk-8u144-linux-x64.tar.gz -C ../modules/
#解压过程
[bduser101@node101 software]$tar -zxvf hadoop-2.7.6.tar.gz -C ../modules/
#解压过程
[bduser101@node101 software]$cd ~/modules
#将jdk和hadoop冗长的名称改为简写
[bduser101@node101 modules]$mv jdk1.8.0_144/ jdk
[bduser101@node101 modules]$mv hadoop-2.7.6.tar.gz/ hadoop
- 配置java、hadoop的环境变量
[bduser101@node101 modules]$cd ~
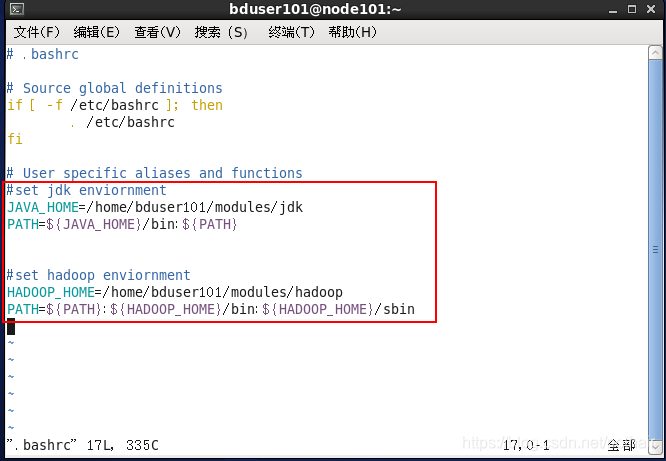
[bduser101@node101 ~]$ vi .bashrc
#在文件中加入以下内容
(JAVA_HOME,HADOOP_HOME的值因虚拟机的当前用户不同所以地址值不同,大体应该为/home/当前用户名/modules/jdk或者/hadoop)
验证java,hadoop环境变量是否成功
[bduser101@node101 ~]$resource .bashrc
[bduser101@node101 ~]$java -version
#显示jdk版本号
[bduser101@node101 ~]$hadoop version
#显示hadoop版本号
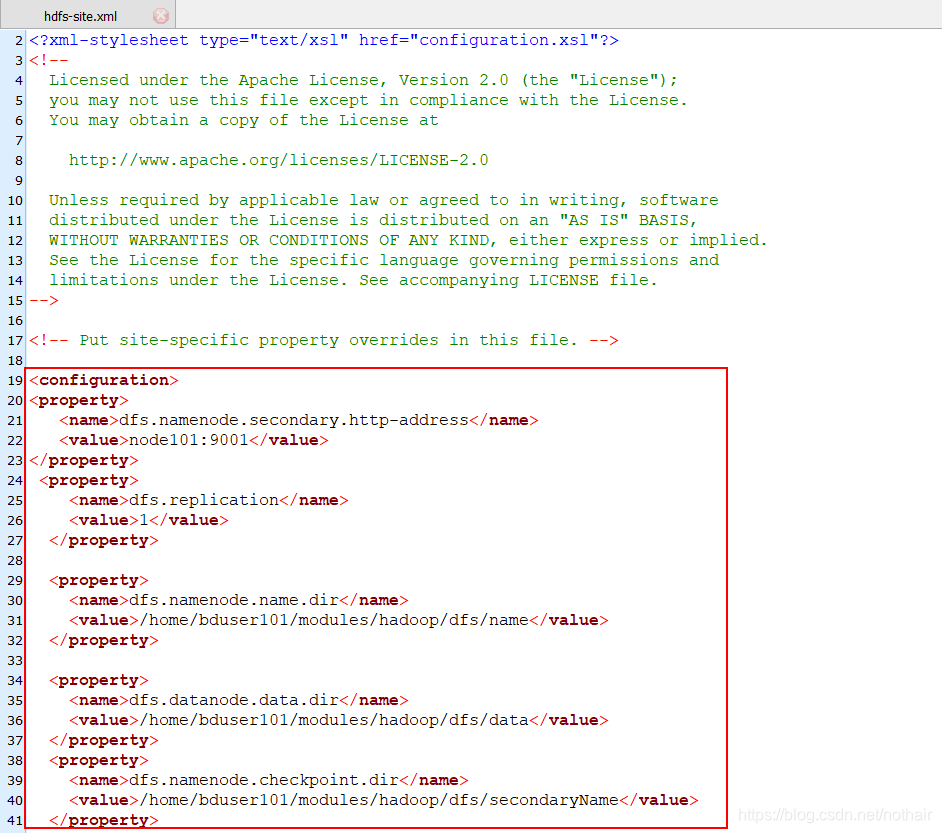
- 修改/home/bduser101/modules/hadoop/etc/hadoop/中的6个文件
1.hdfs-site.xml
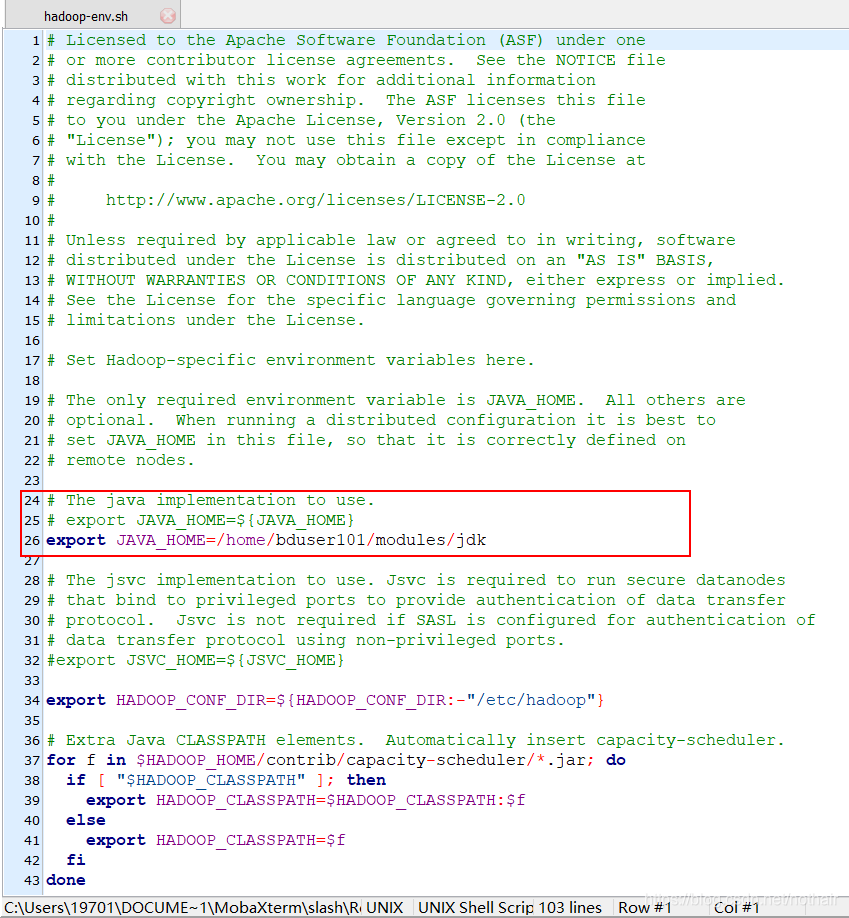
2.hadoop-env.sh
3.core-site.xml

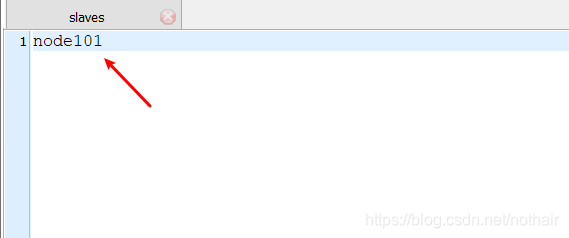
4.slaves
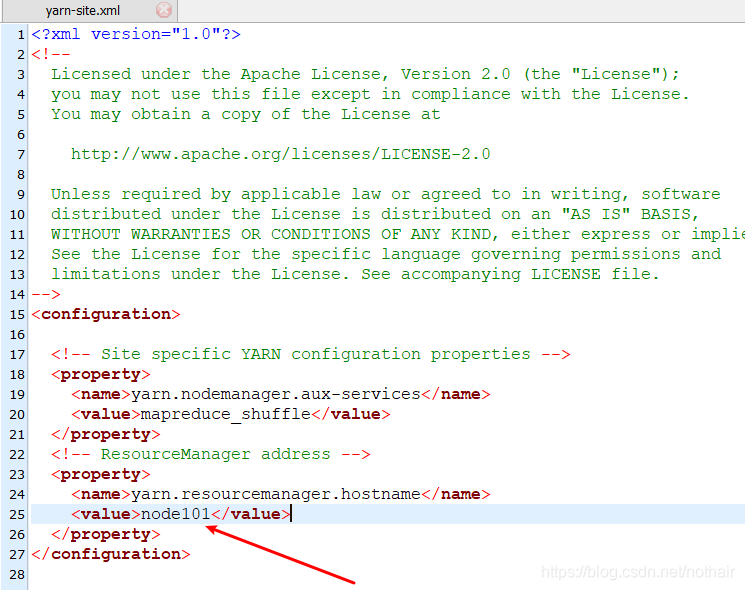
5.yarn-site.xml
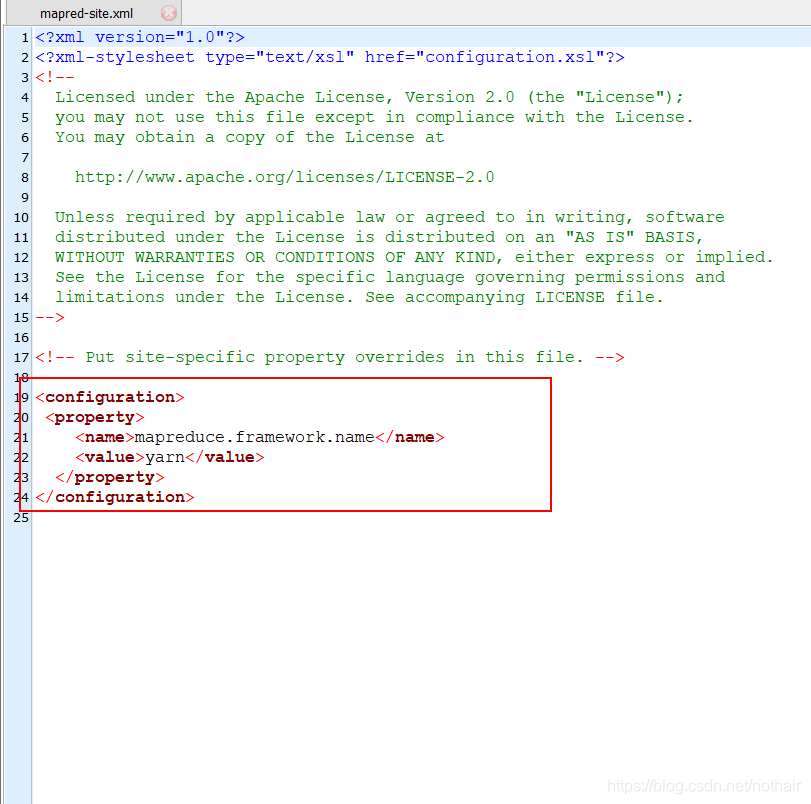
6.mapred-site.xml
- 格式化namenode(第一次启动集群之前格式化)
[bduser101@node101 modules]$ hadoop namenode -format
验证格式化成功
[bduser101@node101 modules]$cd /home/bduser101/modules/hadoop
[bduser101@node101 hadoop]$ ls
bin dfs etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[bduser101@node101 hadoop]$ cd dfs
[bduser101@node101 dfs]$ ls
name
- 启动集群
[bduser101@node101 ~]$ start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [node101]
node101: starting namenode, logging to /home/bduser101/modules/hadoop/logs/hadoop-bduser101-namenode-node101 .out
node101: starting datanode, logging to /home/bduser101/modules/hadoop/logs/hadoop-bduser101-datanode-node101 .out
Starting secondary namenodes [node101]
node101: starting secondarynamenode, logging to /home/bduser101/modules/hadoop/logs/hadoop-bduser101-seconda rynamenode-node101.out
starting yarn daemons
starting resourcemanager, logging to /home/bduser101/modules/hadoop/logs/yarn-bduser101-resourcemanager-node 101.out
node101: starting nodemanager, logging to /home/bduser101/modules/hadoop/logs/yarn-bduser101-nodemanager-nod e101.out
验证集群启动成功
[bduser101@node101 ~]$ jps
3217 SecondaryNameNode
3057 DataNode
3362 ResourceManager
2930 NameNode
3462 NodeManager
3754 Jps
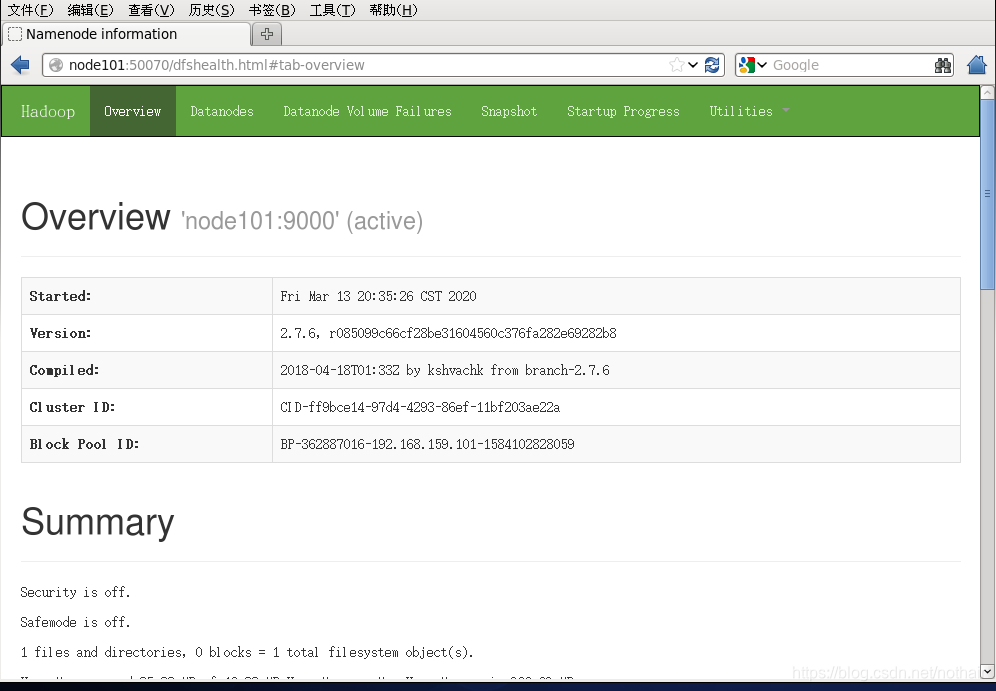
- 在虚拟机中打开火狐浏览器在地址栏输入:node101:50070,出现如下界面则表示伪分布集群搭建成功,如果不能查看,看友情贴处理http://www.cnblogs.com/zlslch/p/6604189.html