概率分布
离散变量对应概率质量函数(就是离散变量的概率,加起来为1,教材叫分布律)
连续变量对应概率密度函数(积分为1)
边缘概率
已知一组变量的联合概率分布,其中变量的一个子集的概率分布称为边缘概率分布。
比如已知,可以依据下面求和法则来计算
:
对于连续型变量,需要用积分替代求和:
条件概率
在的条件下,
发生的条件概率为:
条件概率只有在时有定义。
概率的链式法则或乘法法则:任何多维随机变量的联合概率分布,都可以分解成只有一个变量的条件概率相乘的形式:
独立性
如果两个随机变量和
的概率分布可以表示成两个因子的乘积形式,且一个因子只包含x,另一个因子只包含y,则称这两个随机变量是相互独立的(可以扩展到n个随机变量):
如果关于和
的条件概率分布对
的每一个取值都能写成乘积的形式,那么这两个随机变量
和
在给定随机变量
时是条件独立的:
随机变量的独立性和事件的独立性是相通的。
函数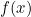 关于分布
关于分布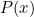 数字特征
数字特征
期望:
离散型:
连续型:
方差:
标准差:方差的平方根
协方差:在某种意义上给出了两个变量线性相关性的强度以及这些变量的尺度:
如果协方差的绝对值很大,意味着变量值变化很大,并且它们同时距离各自的均值很远。如果协方差是正的,那么两个变量都倾向于同时取得相对较大的值。如果协方差是负的,那么其中一个变量倾向于取得相对较大的值的同时,另一个变量倾向于取得相对较小的值。
相关系数:将每个变量的贡献归一化,为了只衡量变量的相关性:
协方差矩阵:随机向量的协方差矩阵为:
常用的概率分布
0-1分布(伯努利分布)
对于一次试验,该试验的结果只有两种(要么是事件A发生,要么不是),结果定义为0和1,另结果为1的概率是p,那么0-1分布可以表达为
记为
二项分布
设某事件A在一次试验中发生的概率为p,重复n次试验,则事件A发生的次数i的概率的分布称为二项分布,其表达式为
记为。0-1分布是二项分布中n取1的特殊形式。
多项分布
多项分布是多维随机变量的分布,对于一次试验,其结果有k种,各种结果出现的概率分别为,
,...,
,则重复n次试验,各种结果出现的次数分别为
,
,...,
的概率的分布称为多项分布,其表达式为
Multinoulli分布
Multinouli分布和多项分布的关系就像0-1分布和二项分布的关系,相当于是多项分布中n取1的形式。从而可知,
,...,
的约束为
在这种情况下,各结果出现的概率为就表示了Multinouli分布。
泊松分布
泊松分布是在二项分布中满足时的极限形式,它多出现在当
表示在一定的时间或空间内出现事件个数这样的场合。具体地,假设观察的时间或空间的范围为
,将该区间分成n个等长小段:
并且假定在各个小段之内:①事件发生一次的概率,近似地与段长
成正比,即可取
。又假定n很大而段很小,在段内事件发生两次或以上是不可能的,则事件
不发生的概率为
。②各段之内事件是否发生是独立的。根据这个假定可以知道
,于是事件X在范围内发生的
次的概率就可以表达为
当时,就可以由上式得到泊松分布的表达
称服从泊松分布,记作
。
当n很大且p很小时,我们可以用泊松分布来近似二项分布,此时取,通过近似求取概率可以很大的降低计算量。
均匀分布
在离散型随机变量中,均匀分布可以视为随机变量可能的取值为n个不同的取值,
取到每个取值的概率都是
。
我们更多的是讨论连续型随机变量中的均匀分布,其概率密度函数为
正态分布
一维标准正态分布
一维正态分布
多维正态分布
其中是正定对称矩阵,给出了分布的协方差矩阵。常把协方差矩阵固定成一个对角矩阵。
如果想要了解正态分布的发现和发展历程,可以阅读下面资料:
科学松鼠会 » 正态分布的前世今生(上) http://songshuhui.net/archives/76501
科学松鼠会 » 正态分布的前世今生(下) http://songshuhui.net/archives/77386
关于多元高斯分布的推导(介绍为什么是用协方差矩阵):https://www.cnblogs.com/bingjianing/p/9117330.html
指数分布
From:如何推导指数分布的概率密度曲线?
指数分布可以定义为:在事件(关于时间t)没有发生的情况下,事件在下一个内发生的概率为
(类似于泊松分布中分小段的假定,事件发生的概率与小区间长成正比,并且发生两次或以上次数的概率为0),那么事件在接下来的前n个内没有发生,而在第n+1个
发生的概率为
所以,事件在t时刻后的一个内发生的概率就等于
于是可以写出事件关于时间t发生的概率分布函数为
求导即得指数分布的概率密度函数为
指数分布的一个重要性质是无记忆性(指数分布也可以定义为具有无记忆性的取值范围为0到正无穷的连续分布)。
拉普拉斯分布
如果随机变量的概率密度函数分布为
那么它就是拉普拉斯分布。其中,是位置参数,
是尺度参数。如果
, 那么,正半部分恰好是
倍
的指数分布。正态分布是用相对于 μ 平均值的差的平方来表示,而拉普拉斯概率密度用相对于平均值的差的绝对值来表示。因此,拉普拉斯分布的尾部比正态分布更加平坦。
狄拉克分布
狄拉克函数函数是定义为除了0以外的所有点都为0,并且在
上的积分为1的广义函数。在一些情况,我们希望概率分布中的所有质量都集中在一个点
上,这可以通过使用
函数定义概率密度函数来实现
称之为狄拉克分布。
经验分布
经验分布是基于观测数据的分布(其实就是经验分布函数所表示的分布,是基于观测数据给出的)。狄拉克分布经常作为经验分布的一个组成部分实现(其实就是把概率密度分给给定数据集/采样集中出现的数据的频数,但在这种情况下是应用到连续型的情况):
经验分布将概率密度付给m个点
中的每一个,
是来自给定的数据集或采样的集合。
更多资料:计算与推断思维 九、经验分布
混合分布
混合分布由一些组件分布构成(其实就是通过组件分布加权得到的混合的概率分布,权重和为1,即权重服从Multinouli分布):
这里是组件分布,
是对各组件分布的一个Multinouli分布(各组件分布的权重)。
潜变量:潜变量/隐变量是我们不能直接观测到的随机变量。混合模型的组件标识变量c就是其中的一个例子。
混合高斯模型:混合模型中一个重要的模型,它的每一个组件是高斯分布,各有各自的参数——均值
和协方差矩阵
。
关于混合高斯模型和EM算法可参考资料:详解EM算法与混合高斯模型(Gaussian mixture model, GMM)
logistic sigmoid函数和softplus函数
贝叶斯规则
全概率公式
贝叶斯定理
先验概率与后验概率
最大后验假设
极大似然假设
https://blog.csdn.net/w_doudou/article/details/80596490