破解百度翻译
1. 首先要分析浏览器是怎么发送请求的。
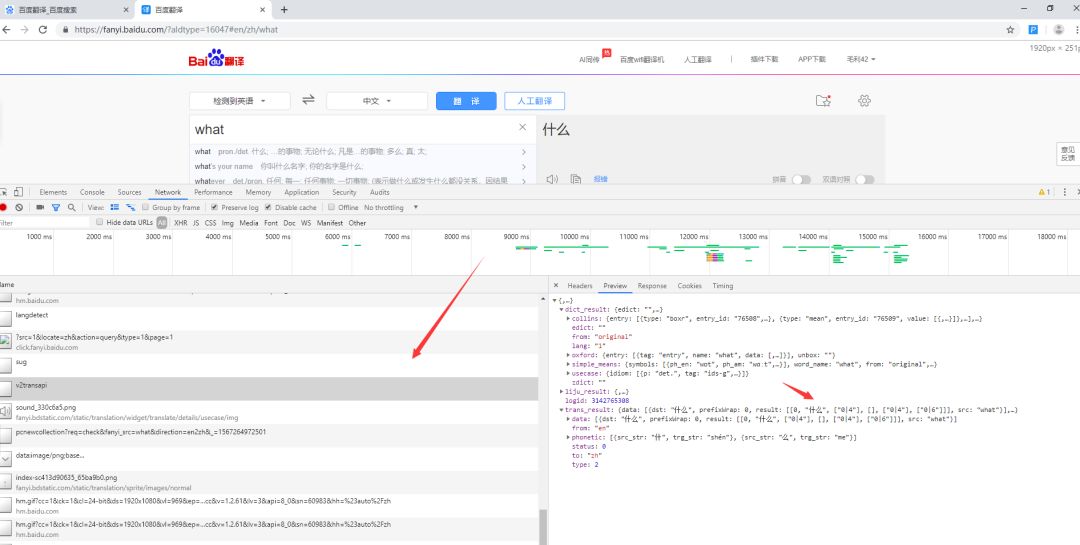
2. 构造请求
找到关键请求之后,就要分析请求,然后去构造请求。分析请求有一下几个要素,url,请求方法,请求头,请求参数。
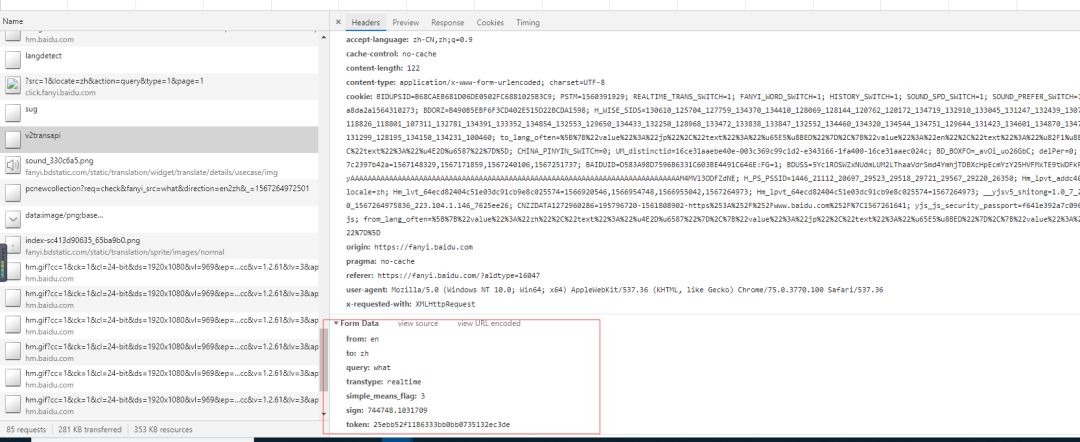
请求参数有七个,可以通过反复请求然后比较的方法得出from,to是表示翻译语言的,transtype,simple_means_flags这两个的值没有变。最关键的是query,sign,token参数,其中query是要查询的单词字符串。sign和token需要分析。
3. 关键参数token的分析
请求的参数有三个来源
第一个请求返回的页面html源码中
前面的某次请求返回的数据
请求之前由js动态生成
打开百度翻译页面源码,复制上面请求中token的值然后搜索,果然在页面源码中发现了token的值。

4. 关键参数sign的分析
经过分析,发现sign的值随着单词的不同而不同,并且因为当前请求是ajax的,所以sign一定是js动态生成的。
js逆向的三种方法
通过页面元素触发函数进行定位请求执行js代码
通过开发者调试工具
network选项中的initiator栏进行定位通过搜索参数名进行定位
我把sign搜它出来 发现sign函数
发现sign函数 去这是js看下
去这是js看下
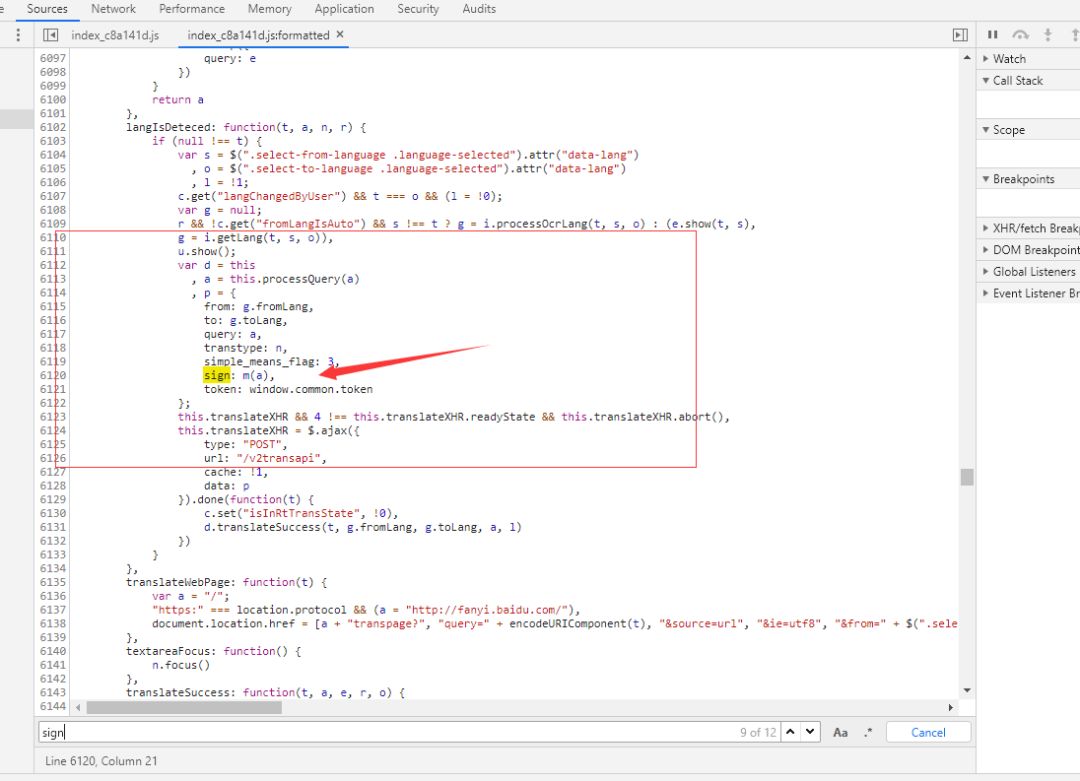
打断点,回车,运行下js
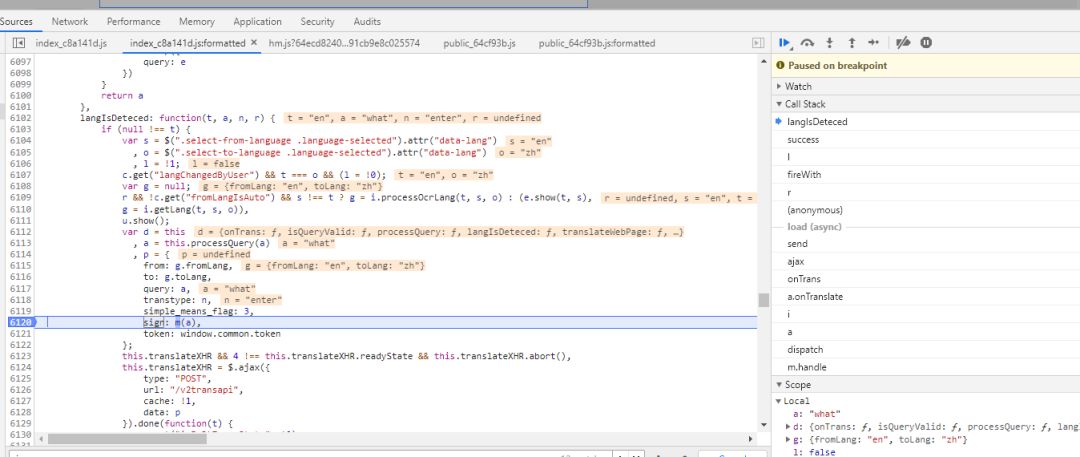
最后一步一步来调试
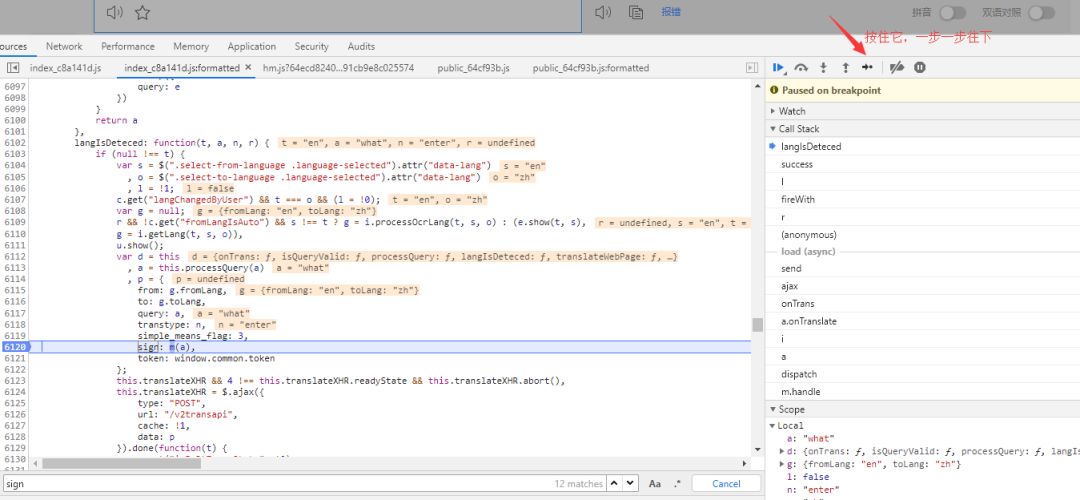
很快找到了来源

发现处理的方法就是e,n两个函数,通过PyExecJS模块进行js测试。因为这js函数看不懂,不建议改写成python函数,将这两段函数代码复制到文本中,保存为baidu.js文件
5. PyExecJS模块
PyExecJS是一个实现通过python执行js代码的库。
安装:
$ pip install PyExecJS
PyExecJS入门

直接运行e,n两个函数
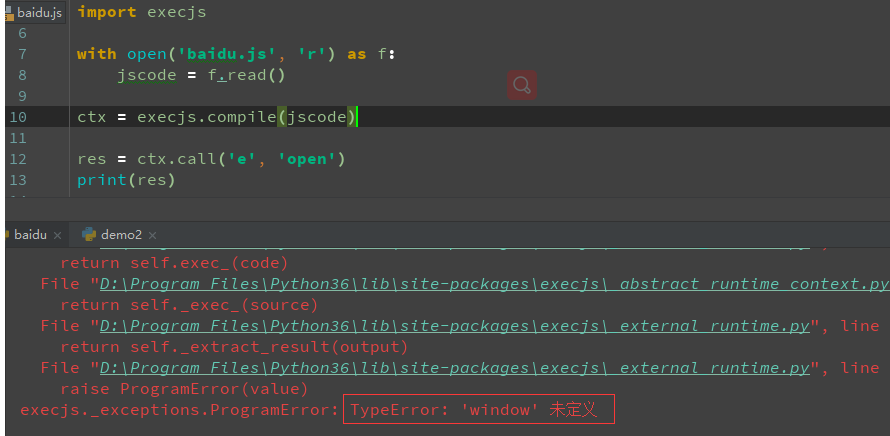
分析js代码,发现其中有个window的变量,原来window没定义
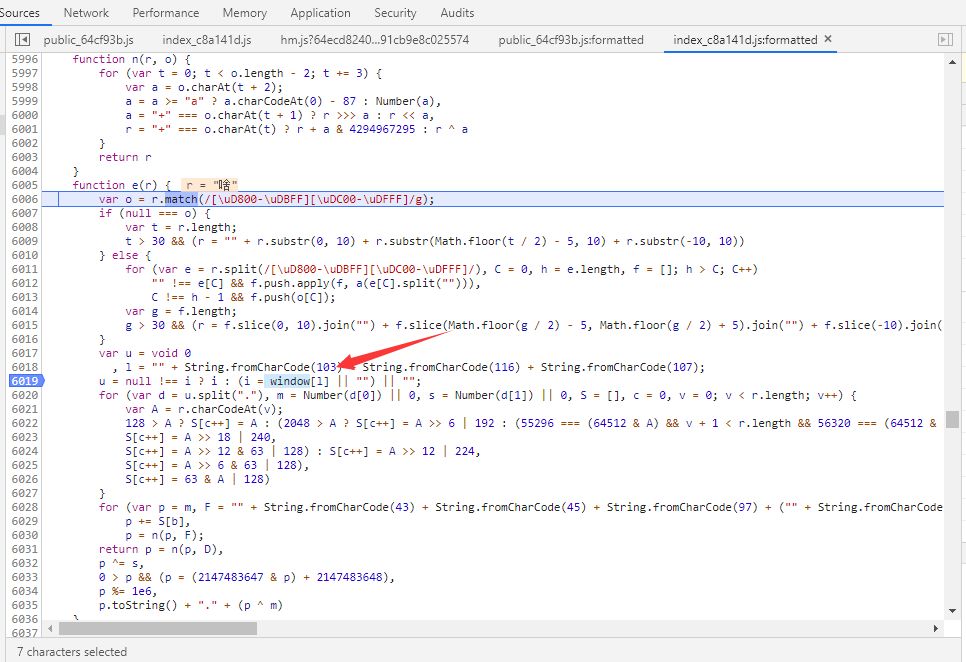
不知道它是啥,打断点,看下啥东西
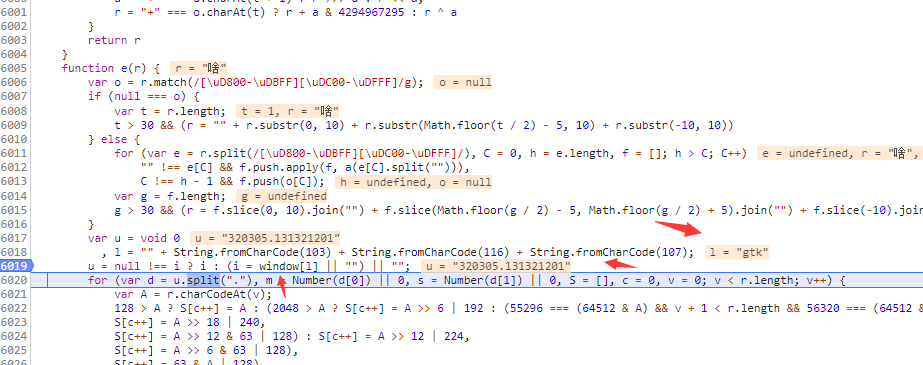
window[gbk] ,window不就是一个变量来的,去看下local变量
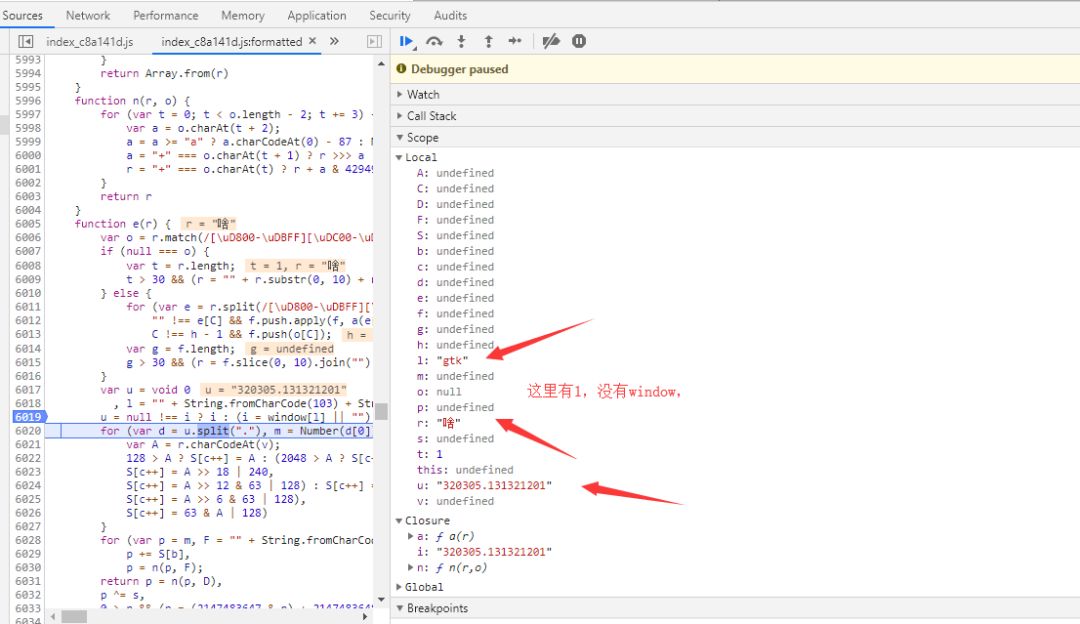
local没有,看global
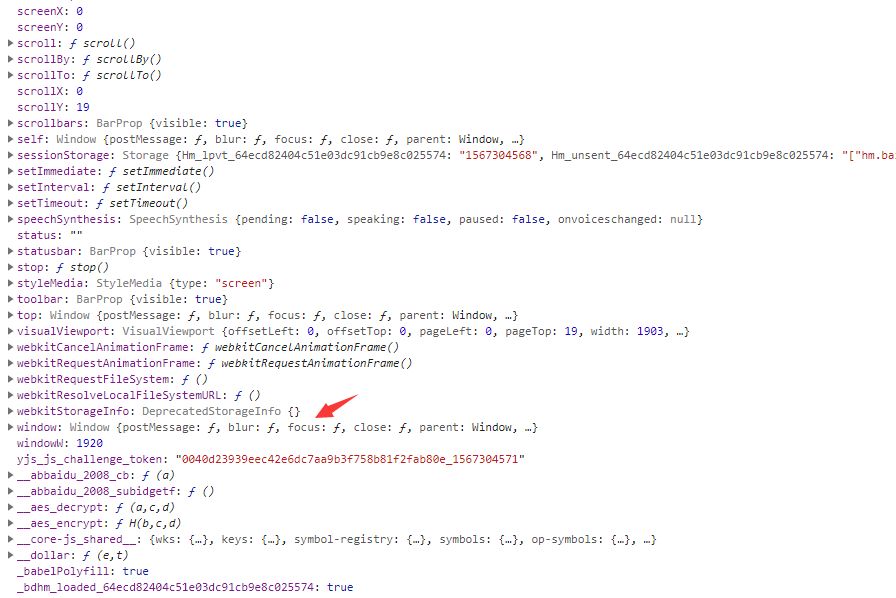
在window中寻找gbk
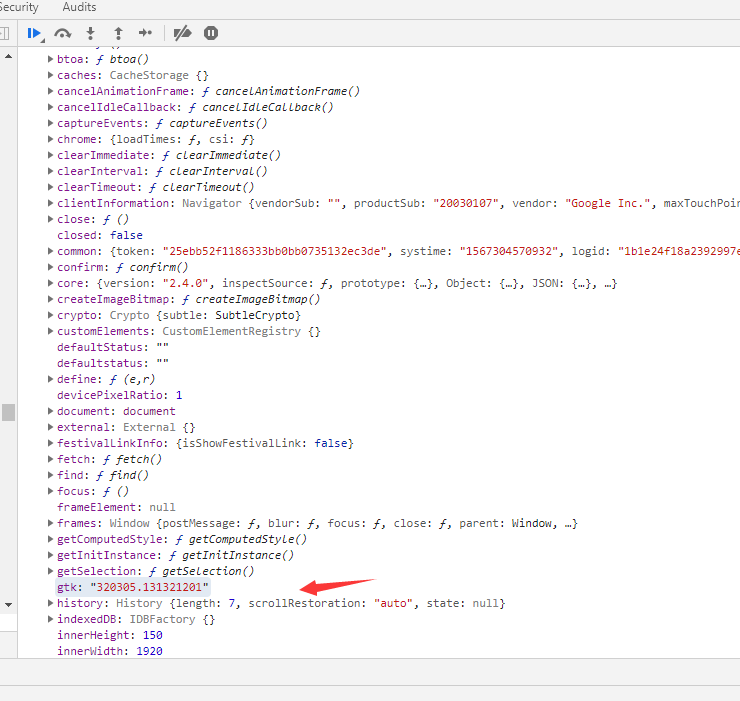
在js先用"320305.131321201" 代替window[l],运行
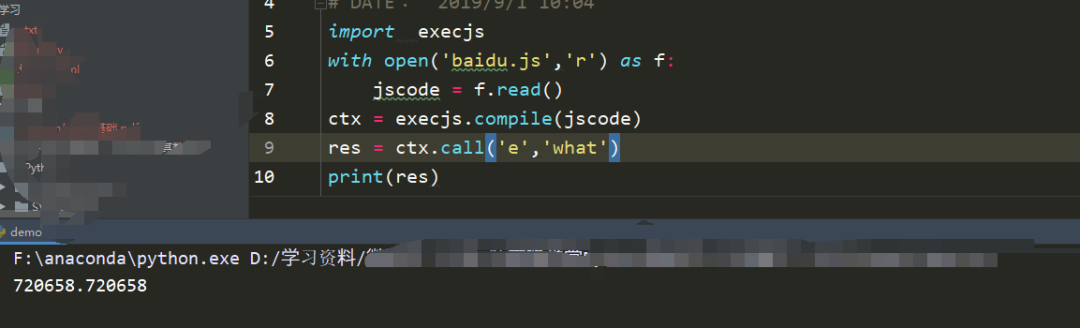
这就是我找了好久的的sign
5. 分析window[l]
是不是每个单词的sign都是一样的呢?
尝试到html页面中去查找,发现是一个在html页面中定义的变量。
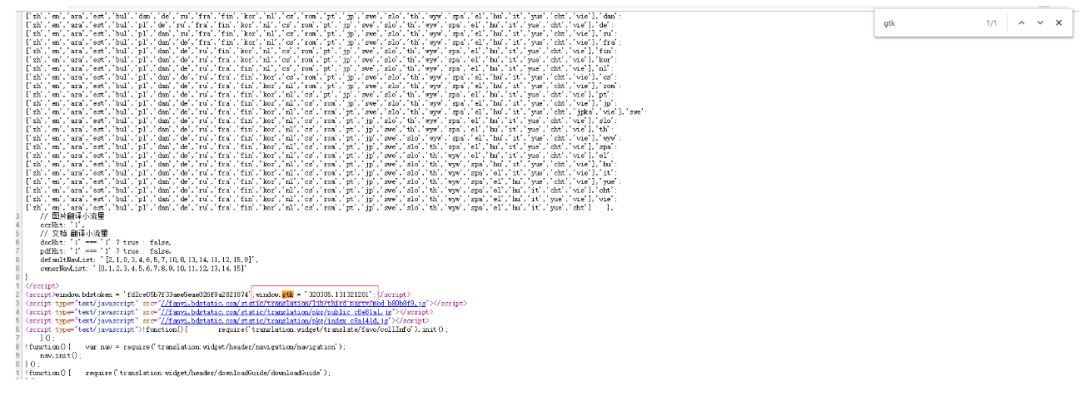
这是个固定值,可以直接写成常量,也可以取页面获取。
6. 代码编写
思路
利用正则将页面的token拿下来
window[gbk]是固定的,封装函数来得到sign
这里有个神坑:发现页面请求了两次,第一次的页面
token不是合法token。用seesion来访问保存cookie这样成功率高点
 声明:本文只做技术交流,不提供源码,如有侵权,请告知删除,谢谢。
声明:本文只做技术交流,不提供源码,如有侵权,请告知删除,谢谢。

一直原创,从未转载
请认准我,将我置标

转发,好看支持一下,感谢