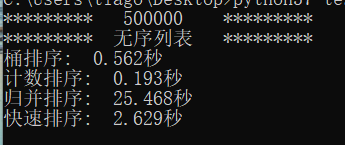
首先证明一波排序算法的运算性能,如下图。对于50万个数据的无序列表,时间复杂度为的桶排序和计数排序明显比复杂度为
的归并排序和快速排序性能好至少一个数量级。
1. 计数排序
1.1 基本原理:首先确定列表的最大值max和最小值min,然后创建一个 (max+1-min) 长度的二维空列表,第一维是数据的大小,第二维记录该数据的个数。然后对待排序列表进行逐个元素扫描,将元素根据大小放入 (max+1-min) 长度的空列表,比如值为 min的元素就放在第0个,并且相应计数加1。直至列表扫描结束,那么(max+1-min) 长度的二维列表会记录每个值的个数,然后数据再逐个从列表弹出至原列表即可,动画效果。
1.2 python代码
def countsort(lst):
if len(lst)<2:
return lst
L = lst[:]
min = L[0]
max = L[0]
for i in range(1,len(L)):
if L[i]>max:
max = L[i]
elif L[i]<min:
min = L[i]
L_tmp = [[x, 0] for x in range(min, max+1)]
for x in L:
L_tmp[x-min][1] += 1
L.clear()
for i in range(min, max+1):
while L_tmp[i-min][1]:
L_tmp[i-min][1] -= 1
L.append(i)
return L2. 桶排序
2.1 基本原理:首先求得列表的最大值max和最小值min,确定列表的范围。然后设置桶的容量,那么根据列表总数和桶的容量,就可以得到桶的数量。现在可以根据数据大小,把数据放入相应桶中,示例如下。此时对每个桶进行排序,堆排序或者快速排序都可以,最后把排好序的数据放回原列表就可以了。
#桶排序原理
L = [3,7,1,0,5,7,7,9,3,1]
----------------------------------------第一步----------------------------------------
确定列表最大值max=9, 最小值min=0;这里调整桶的容量为3,则math.ceil(10/3)得到4个空桶
并且第一个空桶放0-2的数据,第二个空桶放3-5的数据,第三个空桶放6-8的数据,第二个空桶放9-11的数据
----------------------------------------第一步----------------------------------------
扫描列表L,根据数据大小放入不同的桶,[[1,0,1], [ 3,5,3], [7,7,7], [9]]
此时各个桶之间是有序的,我们再对各个桶内的数据使用快排进行排序,最后再把数据添加至原列表即可。2.2 python代码
def bucketsort(lst):
if len(lst)<2:
return lst
L = lst[:]
min = L[0]
max = L[0]
for i in range(1,len(L)):
if L[i]>max:
max = L[i]
elif L[i]<min:
min = L[i]
m_len = 10
cnt_m = math.ceil((max+1-min)/m_len)
L_m = [[] for i in range(cnt_m)]
for x in L:
L_m[(x-min)//m_len].append(x)
L.clear()
for l_m in L_m:
L.extend(quicksort1(l_m))
return L3. 基数排序
3.1 基本原理:对数据的每一位(个位、十位、百位)进行排序,分为最低有效位LSD(从个位开始排序)和最高有效位MSD(从最高位开始排序)。网上都说对于位数多的数据,采用MSD更好,但没找到原因,自己揣测是因为位数多数据少的话,更容易有序,如下简单例子。
L = [8,16,123,15,3,9,678,287]
#MSD
---------------------------------------第一步---------------------------------------
最大值是123,则得到位数为3,从百位开始排序,根据百位是多少,放入第几个列表(总共10个,0-9),没有则空着,如下。
得到L=[[8,16,15,3,9], [123], [287], [], [], [], [678], [], [], []]
---------------------------------------第二步---------------------------------------
其实此时数据已经大致有序,[123],[287],[678]三个列表不需要排序,只需对LL=[8,16,15,3,9]进行排序。
此时对LL=[8,16,15,3,9]的十位进行排序.
得到LL=[[8,3,9], [16,15], [], [], [], [], [], [], [], []]
---------------------------------------第三步---------------------------------------
此时再对个位进行排序,则可得到排好序的整个列表
#LSD
---------------------------------------第一步---------------------------------------
最大值是123,则得到位数为3,逐个扫描,从个位开始排序,根据个位是多少,放入第几个列表,没有则空着,如下。
得到L=[[], [], [], [123,3], [], [15], [16], [287], [8,678], [9]]
---------------------------------------第二步---------------------------------------
LSD通过个位排序后的列表“看起来”更乱了。而且LSD与MSD不同,LSD此时需要把各个列表重新合并到一个列表,
得到LL=[123,3,15,16,287,8,678,9]。然后现在对数据逐个扫描并对十位进行排序,得到如下列表。
得到LL=[[3,8,9], [15,16], [123], [], [], [], [], [678], [287], []]
---------------------------------------第三步---------------------------------------
此时到最后一步,列表大致有序了。如果位数多的话,那么进行到第三步时,数据看着还是挺乱的,因此排序代价也更高。
最后再合并得到LLL=[3,8,9,15,16,123,678,287],然后对数据逐个扫描并对百位进行排序,得到如下列表。
LLL=[[3,8,9,15,16], [123], [287], [], [], [], [678], [], [], []]
此时列表已有序,最后合并即可
3.2 MSD代码
def resort(lst, cnt):
if not cnt:
return lst
div = pow(10, cnt-1)
L_tmp = [[] for i in range(10)]
for x in lst:
L_tmp[x//div%10].append(x)
lst.clear()
for i in range(10):
lst.extend(resort(L_tmp[i], cnt-1))
return lst
def basesort(lst):
if len(lst)<2:
return lst
L = lst[:]
max = L[0]
for i in range(1,len(L)):
if L[i]>max:
max = L[i]
cnt_bit = 0
while max:
cnt_bit += 1
max //= 10
return resort(L, cnt_bit)4. 运算性能及总结
4.1 性能分析
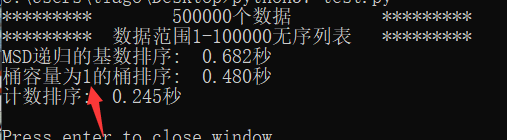
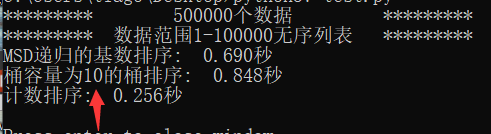
此时桶容量为10效果较好
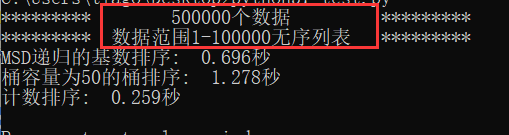
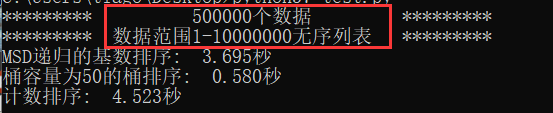
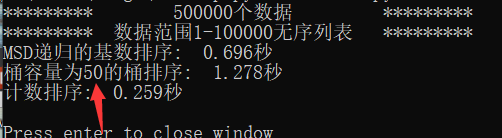
此时桶容量为50效果较好,所以桶容量应随着数据范围的增大而相应增大。
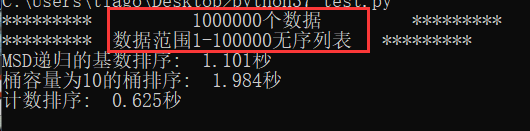
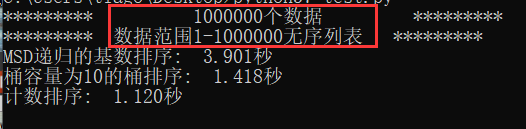
通过数据的位数变化以及范围变化,可以得到基数排序因为数据的位数增多而性能下降,计数排序则由于数据范围增加而性能下降。
4.2 总结:
① 计数排序非常简单易懂,而且运算性能也不差,但是运算性能随着数据范围的增大而减弱。
② 桶排序需要根据数据范围调整桶的容量来确定桶的个数,桶数量越多,数据分布越均匀(这样每个桶的数据量差不多),排序性能越好,因为N个数据,M个桶,每个桶有N/M的数据,则每个桶排序复杂度为,M个桶的排序复杂度为
,N/M越小越好,即桶越多越好。最好情况是一个桶中只有一个数据,都不需要排序,但是内存消耗也相应增加;桶数量越少,排序性能越差。
③ 基数排序,运算性能受数据位数增多而下降