Java学习笔记-Day61 MySQL高级(二)
一、建表方式
(1)SQL语句:create table 表名;
(2)通过navicat等可视化工具来创建表
(3)反向工具生成表(java类 —> 表)
(4)CDM —> PDM —> SQL
二、子查询
查询福建省的所有城市:
(1)查询结果作为where条件使用。
- 先查询福建省的provinceId,再将查询到的provinceId作为条件查询。
select * from t_province p where p.ProvinceName = '福建省';
select * from t_city c where c.ParentId = '350000';
- 子查询写法
select * from t_city c where c.ParentId in (select p.ProvinceId from t_province p where p.ProvinceName = '福建省');
(2)查询结果作为表来使用。
select * from (select * from t_province p order by id DESC limit 2) temp order by id;
(3)查询结果作为列来使用。
select c.CityId,c.CityName,(select ProvinceName from t_province p where p.provinceid = c.ParentId) '省/市' from t_city c;
三、关键字 exists 和 not exists
(1)exists 和in的等价写法
- in的功能是查询 在()中任意一个条件
select * from t_province where provinceid in(select c.ParentId from t_city c);
- exists 根据后面查询结果是否存在来决定前面的查询是否执行
select * from t_province p where exists (select c.ParentId from t_city c where c.parentid = p.ProvinceId);
(2)not exists 和not in的等价写法
select * from t_province where provinceid not in(select c.ParentId from t_city c);
select * from t_province p where not exists (select c.ParentId from t_city c where c.parentid = p.ProvinceId);

四、视图
视图就是存在数据库中的一张虚拟表。一个视图中只有一条SQL语句。
创建视图:create view 视图名 as sql语句;
-- 创建视图
create view view01 as
select CityName as 市 from t_province
inner join t_city
on t_province.ProvinceId=t_city.ParentId;
使用视图的好处:(1)简单性。(2)安全性。(3)逻辑数据独立性。
五、索引
1、索引简介
在关系数据库中,索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构,它是某个表中一列或若干列值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引以找到特定值,然后顺指针找到包含该值的行。这样可以使对应于表的SQL语句执行得更快,可快速访问数据库表中的特定信息。
2、索引方法
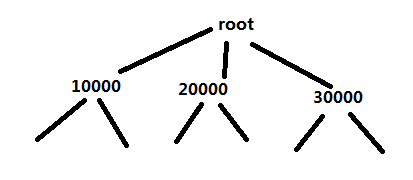
(1)Btree (B树)
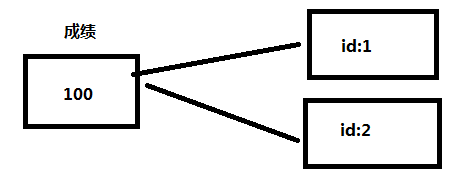
(2)hashtable (哈希表)
3、索引使用场景
(1)查询的where条件中频繁使用的列。
(2)经常用来排序的字段(order by ),更多情况是外键创建索引。
(3)经常用来连接的列。
注意点:建立的索引列,最好是not null。对于列的值只有有限的几种,最好不要建索引。类似于:性别等。
4、索引类型
(1) 标准索引
(2) 唯一索引 (唯一约束)
(3) 主键索引 (主键约束)
(4) 全文索引 (没有索引)
5、索引相关的语法
(1)创建一个标准索引
- 基本语法(建议的写法)
create INDEX 索引名 on 表名(列名);
- 修改表结构添加索引
alter table 表名 add index 索引名(列名);
(2)创建一个唯一索引
create UNIQUE INDEX 索引名 on 表名(列名);
(3)查看索引
show index from 表名;
(4)删除索引
alter table 表名 drop index 索引名;
6、查看执行计划
语法:EXPLAIN SQL语句;
EXPLAIN SELECT * FROM t_area where ParentId='120100'

- id:选择标识符。
- select_type:表示查询的类型。
- table:输出结果集的表。
- partitions:匹配的分区。
- type:表示表的连接类型。
- possible_keys:表示查询时,可能使用的索引。
- key:表示实际使用的索引。
- key_len:索引字段的长度。
- ref:列与索引的比较。
- rows:扫描出的行数(估算的行数)。
- filtered:按表条件过滤的行百分比。
- Extra:执行情况的描述和说明。
注意:模糊查询,%在前则不走索引。
explain select * from user where user_name like '%USER_0500000';
7、获得语句真正的执行时间
测试方法:获得语句真正的执行时间。
(1)set profiling = 1;
(2)SQL语句
(3)show PROFILES;
-- 获得语句真正的执行时间
-- 打开file记录工具
set profiling = 1;
select * from user where user_name = 'USER_0500000';
show PROFILES;

8、数据库执行语句优化
1、通过show status命令了解各种SQL的执行频率。
MySQL客户端连接成功后,通过show [session|global] status命令可以提供服务器状态信息,也可以在操作系统上使用mysqladmin extended-status命令获得这些消息。
下面的命令显示了当前session中部分统计参数的值:
show status like 'Com_%';
- Com_select:执行select操作的次数,一次查询只累加1。
- Com_insert:执行insert操作的次数,对于批量插入的insert操作,只累加一次。
- Com_update:执行update操作的次数。
- Com_delete:执行delete操作的次数。
上面这些参数对于所有存储引擎的表操作都会进行累计。
下面的这几个参数只是针对InnoDB存储引擎的:
- Innodb_rows_read:select查询返回的行数。
- Innodb_rows_inserted:执行insert操作插入的行数。
- Innodb_rows_updated:执行update操作更新的行数。
- Innodb_rows_deleted:执行delete操作删除的行数。
2、定位执行效率较低的SQL语句。
通过慢查询日志定位那些执行效率较低的SQL语句,将slow-query-log参数设置为1之后,MySQL会将所有执行时间超过long_query_time参数所设定的阈值的SQL,写入slow_query_log_file参数所指定的文件中。
show variables like "%slow_query_log%";

如果 slow_query_log 未开启,设置:
set global slow_query_log=on;
由于慢查询日志记录的信息比较多,会影响mysql的性能,所以生产环境不建议长期开启。
也可以写入配置文件my.ini 中:
slow-query-log=1
slow_query_log_file="DEEP-2020SXLVGO-slow.log"
修改my.ini文件:
long_query_time=1 # 慢查询日志的时间定义(秒),默认为10秒,多久就算慢查询的日志
log_queries_not_using_indexes=1 # 将所有没有使用带索引的查询语句全部写到慢查询日志中
修改完成后重启MySQL。
3、通过 DEEP-2020SXLVGO-slow.log 慢查询日志 找出执行效率较低的SQL语句,再对这些执行效率较低SQL语句操作。
(1)先查看是否添加索引。
explain select * from user where user_name like '%USER_0500000';
(2)如果没有添加索引,则添加索引。
create index idx_username on user(user_name);
六、存储过程
1、存储过程简介
MySQL 5.0 版本开始支持存储过程。存储过程是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数来调用执行。存储过程就是数据库 SQL 语言层面的代码封装与重用。
2、存储过程的创建和调用
(1)存储过程的创建
create procedure pro02(IN a int,IN b int,OUT c int)
BEGIN
set c=a+b;
END
(2)存储过程的调用
-- 调用过程(@s是一个变量)
call pro02(10,2,@s);
select @s;
3、给参数变量赋值
(1)set 输出参数变量 = 值;
create procedure pro02(IN a int,IN b int,OUT c int)
BEGIN
set c=a+b;
END
(2)select 值 into 输出参数变量 from 表;
create procedure pro02(IN uid int,OUT uname varchar(20))
BEGIN
select name into uname from users where userid=uid;
END
4、定义变量
(1)declare用来定义局部变量。局部变量的作用范围在begin到end语句块之间,是在该语句块里设置的变量。
##定义变量(declare 变量名 变量类型)
declare vbalance DOUBLE;
(2)@用来定义会话变量,会话变量在整个会话过程都是有作用的,有点类似于全局变量一样。这种变量用途比较广,因为只要在一个会话内(就是某个应用的一个连接过程中),这个变量可以在被调用的存储过程或者代码之间共享数据。
call transfer_out(1,2,200,@s);
select @s;
5、调用过程
call transfer_out(1,2,200,@s);
select @s;
6、IF语句
IF(条件表达式)THEN
sql语句
END IF;
IF(条件表达式)THEN
sql语句
ELSE
sql语句
END IF;
7、ROW_COUNT
mysql中的ROW_COUNT()可以返回前一个SQL进行UPDATE,DELETE,INSERT操作所影响的行数。
8、转账案例:
(1)mysql存储过程:
create procedure `transfer_out`(IN `receiptid` int,IN `payid` int,IN `balance` double,OUT `flag` varchar(10))
BEGIN
##定义变量
declare vbalance DOUBLE;
declare result int;
set result=0;
## 变量v赋值
select ubalance into vbalance from users where userid=payid;
##判断付款账户的金额是否足够
if(vbalance-balance >= 0)then
##开启事务
start transaction;
##转账到收款账户
UPDATE users SET ubalance=ubalance+balance WHERE userid=receiptid;
if(ROW_COUNT()=1)THEN
set result = result+1;
end if;
##付款账户转出金额
UPDATE users SET ubalance=ubalance-balance WHERE userid=payid;
if(ROW_COUNT()=1)THEN
set result = result+1;
end if;
if(result=2)THEN
##提示成功
set flag='成功,事务提交!';
##提交事务
COMMIT;
ELSE
##提示失败
set flag='失败,事务回滚!';
##回滚事务
ROLLBACK;
end if;
ELSE
##提示失败
set flag='失败,余额不足!';
end if;
END
(2)java代码:
package com.etc.bs.test;
import java.sql.CallableStatement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import com.mysql.cj.MysqlType;
public class TestProcedure {
// 数据库连接的url
private static final String url = "jdbc:mysql://localhost:3306/blogdb?useSSL=FALSE&serverTimezone=Asia/Shanghai";
// 数据库连接的user
private static final String user = "root";
// 数据库连接的password
private static final String password = "root";
public static void main(String[] args) {
transfer(1, 2, 100);
}
/**
* 转账功能
*
* @param payid 付款账户id
* @param receiptid 收款账户id
* @param balance 金额
*/
public static void transfer(int payid, int receiptid, double balance) {
Connection conn = null;
CallableStatement cstmt = null;
String sql = "call transfer_out(?,?,?,?);";
try {
// 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 创建数据库连接
conn = DriverManager.getConnection(url, user, password);
cstmt = conn.prepareCall(sql);
// 通过cstmt.setXxx方法设置输入参数
cstmt.setInt(1, payid);
cstmt.setInt(2, receiptid);
cstmt.setDouble(3, balance);
// 通过cstmt.registerOutParameter方法注册输出参数
cstmt.registerOutParameter(4, MysqlType.VARCHAR);
// 执行sql语句
cstmt.execute();
// 通过cstmt.getXxx方法获取输出数据
String flag = cstmt.getString(4);
System.out.println("转账" + flag);
} catch (Exception e) {
e.printStackTrace();
}finally {
// 释放资源
try {
cstmt.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}