python编程操作系统篇知识点详细梳理
进程的概念:(Process)
- 进程就是正在运行的程序,它是操作系统中资源分配的最小单位。
- 资源分配:操作系统分配的CPU时间片、内存、磁盘空间端口等等资源。
- 进程号(process identification)是操作系统分配给进程的唯一标识号,用户每打开一个进程操作系统都会为其创建PID。UID:用户id; PID:进程id; PPID:父进程id。
- 在存储空间中未被执行的叫程序,被执行的叫进程(进行中的程序)。
- 同一个程序执行两次之后是两个进程。
- 进程和进程之间内存隔离,但可通过socket通信或者通过文件通信。
并行和并发
- 并发:单个CPU通过操作系统调度以极快地速度轮流执行多个进程,给用户的感觉是多个进程正在同时执行。并发在逻辑上是同时执行,实质上是轮流执行。
- 并行:多个CPU在同一时间分别执行不同的进程。并行是真正的同时执行。
CPU调度策略
- 先来先服务:先来的先执行。
- 短作业优先:短作业优先执行。
- 时间片轮转:每个作业执行一个时间片后轮转其它作业执行。
- 多级反馈队列:
- 进程首次启动时进入优先级最高的Q1队列等待;
- 优先执行Q1队列中的进程;若高优先级Q1队列中无待执行的进程,那么会执行Q2队列中的进程;若Q1、Q2队列中都无待执行的进程,那么会执行Q3队列中的进程;以此类推,直至末尾队列的进程。
- 对同级队列中的进程按先来先服务的策略分配时间片。如Q1队列的时间片为N,若Q1中的进程用完时间片N后还未完成时会被调整到Q2队列;若用完Q2队列的时间片后还未完成时会被调整到Q3队列;以此类推,直至被调整到末尾队列。
- 在末尾队列QN中的各个进程,按照时间片轮转执行。
- 如果低优先级队列中的进程在运行时有新进程需要运行,那么它会被中断运行并被放入当前队列的队尾,然后让新进程优先运行。另外被中断运行的进程再度运行时它只能得到上次未用完的时间片。
- 优先级越高的队列时间片越短,优先级越低的队列时间片越长。如三级反馈队列Q1、Q2、Q3它们的时间片分别为2、4、8。
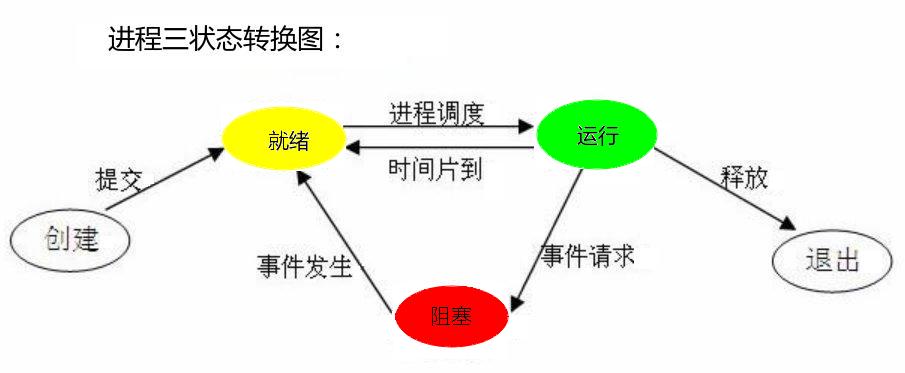
进程三状态
- 就绪(Ready)状态:等待被CPU执行的状态。
- 执行(Running)状态:正在被CPU正在执行的状态。
- 阻塞(Blocked)状态:等待某个事件发生(如等待用户输入)而无法执行的状态。
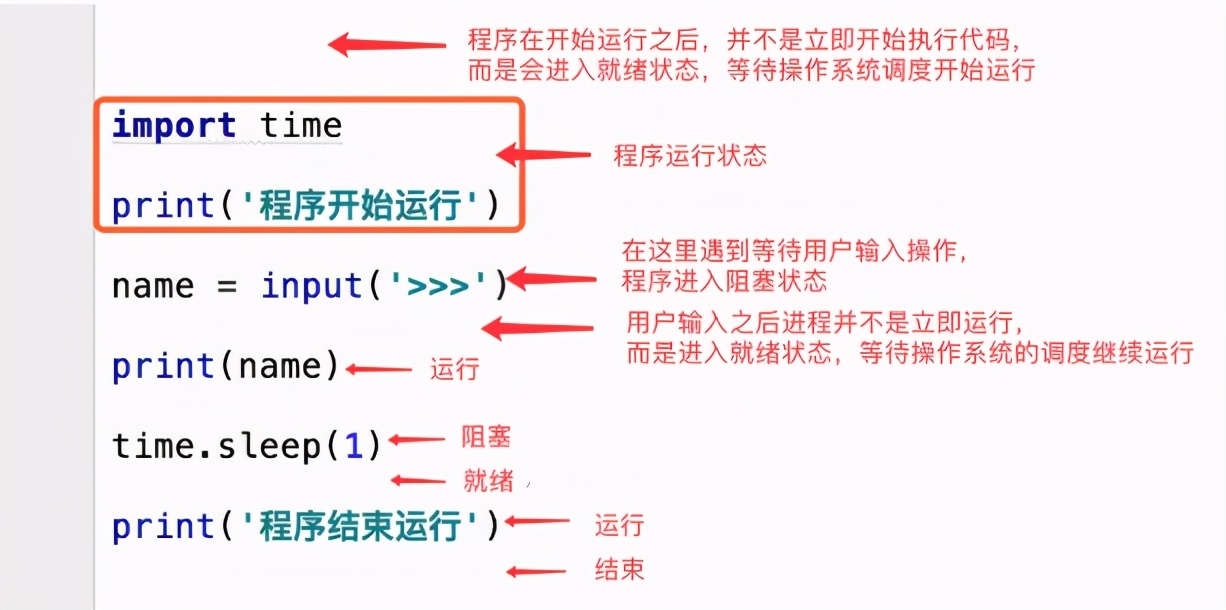
代码示意图:
同步与异步、阻塞与非阻塞
同步与异步、阻塞与非阻塞发生在多任务场景中:
- 同步:是指A进程调用B进程后,A进程要等B进程完成后才能继续运行,这是单进程运行状态。上面的代码示意图中就是同步。
- 异步:是指A进程调用B进程后,A进程不等B进程完成,它和B进程可以同时执行,这是多进程(或线程)运行状态。
- 阻塞:是指进程调用了某些I/O操作后进入挂起状态,要等I/O返回的结果才继续执行。
- 非阻塞:是指进程调用了某些I/O操作后不进入挂起状态,不用等待I/O返回的结果就继续执行。
四种状态:
- 同步阻塞:单进程运行有阻塞事件时,等待阻塞事件完成后才能继续运行。
- 异步阻塞:某进程运行时有多条子进程(或线程)同步运行,它的某条子进程有阻塞事件进入阻塞状态,而其它子进程仍然正常运行。
- 同步非阻塞:没有阻塞事件,单进程正常执行的状态。
- 异步非阻塞:多进程运行且无阻塞事件。
多进程
- 处理多进程的模块:注意:导入的是Process类,首字母必须大写,另外小写的是process文件。
from multiprocessing import Process- 函数式编程方式:
案例:
from multiprocessing import Process
import os
def func(n):
for i in range(n):
print("func", os.getpid(), os.getppid())
if __name__ == '__main__':
print("main", os.getpid(), os.getppid())
p = Process(target=func, args=(1,))
p.start()
out:
main 6928 6621
func 6929 6928代码说明:
- os.getpid:获取进程号。
- os.getppid:获取父进程号。
- p = Process(target=func, args=(1,)):创建Process类的实例,目标是func函数,args=(1,)是给函数传参数(注意agrs=后面必须是元祖,1后面的逗号不能少,少了就不是元祖,会报错),以此创建子进程。
- 面向对象式编程方式:
案例:
from multiprocessing import Process
from time import sleep
from os import getpid, getppid
class MyProcess(Process):
def __init__(self, n):
self.n = n
super().__init__()
def run(self):
sleep(0.1)
print(f"第{self.n}次打印,子进程id:{getpid()},父进程id:{getppid()}")
if __name__ == "__main__":
for i in range(5):
MyProcess(i).start()
print("*" * 20)
out:
********************
第0次打印,子进程id:13029,父进程id:13028
第2次打印,子进程id:13031,父进程id:13028
第1次打印,子进程id:13030,父进程id:13028
第3次打印,子进程id:13032,父进程id:13028
第4次打印,子进程id:13033,父进程id:13028代码说明:

- 面向对象编程必须自定义一个类并继承Process类。
- 必须使用__init__传参,在传参完成后必须调用父类的__init__方法才能正确完成初始化。
- 创建子进程的方法就是初始化自定义类的方法。
- Process类常用的属性和方法:
class Process(process.BaseProcess):
_start_method = None
@staticmethod
def _Popen(process_obj):
return _default_context.get_context().Process._Popen(process_obj)Process类本身内容很少,但它继承了process.BaseProcess类,再来看process.BaseProcess类:
class BaseProcess:
name: str
daemon: bool
authkey: bytes
def __init__(
self,
group: None = ...,
target: Optional[Callable[..., Any]] = ...,
name: Optional[str] = ...,
args: Tuple[Any, ...] = ...,
kwargs: Mapping[str, Any] = ...,
*,
daemon: Optional[bool] = ...,
) -> None: ...
def run(self) -> None: ...
def start(self) -> None: ...
def terminate(self) -> None: ...
if sys.version_info >= (3, 7):
def kill(self) -> None: ...
def close(self) -> None: ...
def join(self, timeout: Optional[float] = ...) -> None: ...
def is_alive(self) -> bool: ...
@property
def exitcode(self) -> Optional[int]: ...
@property
def ident(self) -> Optional[int]: ...
@property
def pid(self) -> Optional[int]: ...
@property
def sentinel(self) -> int: ...代码说明:
- run方法:即多进程需要执行的代码主体。
- start方法:即多进程启动运行。
- terminate方法:强制终止子进程。请注意这个方法是调用操作系统来关闭子进程,通常需要零点零零几秒的片刻时间后该子进程才会被终止。这是异步非阻塞的方法,即该方法通知操作系统后会立即继续执行后续代码,它不等待操作系统返回结果,后续代码运行的时候操作系统杀进程的代码也在同步运行的。
- is_alive方法:查看子进程是否活着。用self.terminate方法结束子进程后立即查看可能还是True即活着的状态,要等待操作系统执行完杀进程的操作后才会返回False。
- pid和ident属性:它们是被property装饰的方法,返回当前进程的id,这2个属性内容完全一致。
- self.exitcode属性:返回子进程结束时的状态码。
- 不同操作系统平台下的差异:
- windows平台下创建子进程是通过加载py文件来获取所需的数据和代码,假如不写“ if __name__ == ‘__main__’ ”会造成递归加载py文件导致加载失败!
- linux和mac平台下创建子进程是通过拷贝父进程内存空间来获取的所需的数据和代码,所以在linux和mac平台下不写“ if __name__ == ‘__main__’ ”也可以正常执行,不会导致加载失败!在linux平台下创建和运行子进程的效率比window平台下高得多。
- 不同子进程之间内存隔离,不能直接共享数据。但是可以通过socket通信。
- 开启多个子进程的示范:
from multiprocessing import Process
import time
def func(name):
time.sleep(0.5)
print('子进程:', name)
if __name__ == '__main__':
print("父进程:")
name_list = ['张三', '李四', '王五']
for i in name_list:
p = Process(target=func, args=(i,))
p.start()
out:
父进程:
子进程: 张三
子进程: 王五
子进程: 李四代码说明:
- 在该案例中time.sleep(0.5)是阻塞事件,多条子进程各自执行,遇到阻塞时各自等待,相互不干扰。这就是异步阻塞。
- 可以使用循环的方式创建多条子进程。
- join阻塞主进程,主进程等待被join的子进程运行结束后才继续运行:
模拟多进程下载文件的错误代码:
from multiprocessing import Process
import time
import random
def func(name):
time.sleep(random.random())
print('子进程:', name)
if __name__ == '__main__':
name_list = ['下载完第一部分', '下载完第二部分', '下载完第三部分', '下载完第四部分', '下载完第五部分']
for i in name_list:
p = Process(target=func, args=(i,))
p.start()
print("文件五个部分下载完成,合并完毕!")
out:
文件五个部分下载完成,合并完毕!
子进程: 下载完第四部分
子进程: 下载完第一部分
子进程: 下载完第五部分
子进程: 下载完第二部分
子进程: 下载完第三部分代码说明:
- 上述代码模拟多进程下载文件。假设不阻塞主进程,那么这个程序无法保证正确执行。
- 要保证上述代码正常运行就必须阻塞主进程,等待所有子进程下载完毕后主进程才能继续执行后续的合并和校验文件以及告知用户下载完成的工作。
模拟多进程下载文件的正确代码:
from multiprocessing import Process
import time
import random
def func(name):
time.sleep(random.random())
print('子进程:', name)
if __name__ == '__main__':
name_list = ['下载完第一部分', '下载完第二部分', '下载完第三部分', '下载完第四部分', '下载完第五部分']
process_list = []
for i in name_list:
p = Process(target=func, args=(i,))
p.start()
process_list.append(p)
for i in process_list:
i.join()
print("文件五个部分下载完成,合并完毕!")
out:
子进程: 下载完第二部分
子进程: 下载完第五部分
子进程: 下载完第一部分
子进程: 下载完第三部分
子进程: 下载完第四部分
文件五个部分下载完成,合并完毕!代码说明:
- 在上述代码中,每次创建并开启子进程后,会将子进程的对象内存地址存入process_list列表中。
- 所有子进程创建完毕后,遍历process_list列表,将所有子进程对象设为阻塞事件,设置方法是p.join()。
- 守护进程:
- 给子进程设置守护进程属性为True,该子进程会随着主进程代码执行完毕而结束。
p.daemon = True- 设置守护进程属性语句必须在子进程启动语句前面。
p.daemon = True
p.start()- 守护进程内无法再开启子进程。
案例,看案例请思考一个问题,son1的打印语句会执行几次?
import time
from multiprocessing import Process
def son1():
while True:
print('->1号子进程')
time.sleep(1)
def son2():
for i in range(5):
print('->2号子进程')
time.sleep(1)
if __name__=="__main__":
p1 = Process(target=son1)
p1.daemon = True
p1.start()
p2 = Process(target=son2)
p2.start()
print("->主进程")
time.sleep(3)
out:
->主进程
->1号子进程
->2号子进程
->1号子进程
->2号子进程
->1号子进程
->2号子进程
->2号子进程
->2号子进程代码说明:
a. 在上述案例中,son1函数即1号子进程每隔1秒打印"->1号子进程"(无限循环);
b. son2函数即2号子进程每隔1秒打印"->1号子进程"(循环5次);
c. 在主进程代码中对son1设守护进程属性为True,然后启动son1子进程;
d. 对son2未设守护进程属性(默认为False),然后启动son2子进程;
e. 主进程sleep3秒,显示结果是son1打印了3次。即主进程的代码3秒执行完毕后son1子进程会被强制结束!
f. son2子进程未设daemon属性,它正常打印了5次,它不会随着主进程的代码结束而结束。
结论:
a. 子进程daemon属性为True的是守护进程,在主进程代码结束时它会被强制结束;
b. 子进程daemon属性为False的是非守护进程,在主进程代码结束时它仍然会正常运行直至运行完毕。
c. 主进程代码结束后守护进程会立即结束,之后python解释器还会做一些回收资源的工作,最后主进程才真正结束。
锁(Lock)
- 案例:假设有一个多进程的票务系统,多个用户使用它买票,抢票案例.py:
import json
import time
from multiprocessing import Process
def search(i):
with open('ticket.txt',encoding='utf8') as f:
ticket = json.load(f)
print(f"{i}你好,当前余票是{ticket['count']}张。")
def buy_ticket(i):
with open('ticket.txt',encoding='utf8') as f:
ticket = json.load(f)
if ticket['count']>0:
ticket['count'] -= 1
print(f'{i}买到票了!')
time.sleep(0.1)
with open('ticket.txt',encoding='utf8',mode='wt') as f:
ticket = json.dump(ticket,f)
if __name__ == "__main__":
for i in range(1,6):
Process(target=search,args=(f'{i}号',)).start()
Process(target=buy_ticket,args=(f'{i}号',)).start()- ticket.txt:
{"count": 1}- 运行结果:
1号你好,当前余票是1张。
1号买到票了!
2号你好,当前余票是1张。
3号你好,当前余票是1张。
2号买到票了!
3号买到票了!
4号你好,当前余票是1张。
5号你好,当前余票是1张。
4号买到票了!
5号买到票了!代码说明:
- 上述案例中buy_ticket函数中有time.sleep(0.1)来模拟网络延迟;
- 查询时多进程受理用户查询操作,结果显示还有1张票;
- 买票后将数据写入文件时因网络延迟造成多名用户同时买到1张余票;
- 由此可见多进程写操作会有数据不安全的问题;
- 要解决上面这个问题必须引入锁的概念,即同一时间只能有一个用户继续写操作。
- 加入lock后的代码:
import json
import time
from multiprocessing import Process
from multiprocessing import Lock
def search(i):
with open('ticket.txt',encoding='utf8') as f:
ticket = json.load(f)
print(f"{i}你好,当前余票是{ticket['count']}张。")
def buy_ticket(i):
with open('ticket.txt',encoding='utf8') as f:
ticket = json.load(f)
if ticket['count']>0:
ticket['count'] -= 1
print(f'{i}买到票了!')
time.sleep(0.1)
with open('ticket.txt',encoding='utf8',mode='wt') as f:
ticket = json.dump(ticket,f)
def lock_buy(i,lock):
search(i)
with lock:
buy_ticket(i)
if __name__ == "__main__":
lock = Lock()
for i in range(1,6):
Process(target=lock_buy,args=(f'{i}号',lock)).start()现在将ticket.txt文件内容改为:
{"count": 2}运行结果:
1号你好,当前余票是2张。
1号买到票了!
2号你好,当前余票是2张。
3号你好,当前余票是2张。
4号你好,当前余票是2张。
5号你好,当前余票是2张。
2号买到票了!代码说明:
- 查询余票时并发执行,多个用户可以同时查余票数量;
- 买票时顺序执行,先来先得;
- with lock:等价于 lock.acquire() # 上锁 和 lock.release() # 解锁;
- 建议使用with lock不要使用lock.acquire()和release():一是因为简便;二是使用with可以保证释放锁而release()可能会因进程异常退出造成死锁。
- 概念总结:
- 加锁可以保证多个进程修改同一块数据时轮流执行修改;
- 加锁牺牲运行速度来保证数据安全;
- 上锁和解锁必须是一对,上锁未解锁会造成死锁。
进程之间通信
进程之间通信(IPC) Inter Process communication分2种:
一、 基于文件,同一台机器内部多个进程之间通信:
- Queue,案例:
from multiprocessing import Queue,Process
def son(q):
q.put('hello')
if __name__ =="__main__":
q = Queue()
Process(target=son,args=(q,)).start()
print(q.get())- 代码说明:
- Queue类必须是从multiprocessing中导入,而不是内置模块queue,它俩不是一个东西!
- Queue队列存取顺序是先进先出;
- get是阻塞事件,若get次数比put多那么会导致阻塞等待。
- Queue详细说明:
要快速准确了解Queue最好还是看源码:
class Queue(queue.Queue[_T]):
# FIXME: `ctx` is a circular dependency and it's not actually optional.
# It's marked as such to be able to use the generic Queue in __init__.pyi.
def __init__(self, maxsize: int = ..., *, ctx: Any = ...) -> None: ...
def get(self, block: bool = ..., timeout: Optional[float] = ...) -> _T: ...
def put(self, obj: _T, block: bool = ..., timeout: Optional[float] = ...) -> None: ...
def qsize(self) -> int: ...
def empty(self) -> bool: ...
def full(self) -> bool: ...
def put_nowait(self, item: _T) -> None: ...
def get_nowait(self) -> _T: ...
def close(self) -> None: ...
def join_thread(self) -> None: ...
def cancel_join_thread(self) -> None: ...- init方法:实例化方法,参数一maxsize(可选,默认为不限长度)用来指定队列长度,参数二ctx实际上是不可选参数。
- get方法,从队列中取数据:
- 参数有2个,参数一block(可选,默认为True)用来指定是否阻塞,参数二timeout(可选,默认为None)用来指定超时阀值 ,该方法默认状态会阻塞当前进程直至取出数据。
- 设置block为True且timeout为正浮点数时表示该方法会阻塞当前进程timeout秒,超时后会抛queue.Empty异常。
- 设置block为false时即表示该方法不阻塞,进程会直接取数据,若队列空会抛queue.Empty异常。另外当block为false时timeout参数失效。
- get_nowait方法,功能等价于get(False)即不阻塞取数据。
- put方法,将数据放入队列:
- 参数有3个:参数一obj(必选,无默认值)是要存放的数据,参数二block(可选,默认为True)用来指定是否阻塞,参数三timeout(可选,默认为None)用来指定超时阀值 。若给定长队列存放数据遇到队列满时该方法会阻塞当前进程直至存入数据,若给不定长队列存放数据虽不会遇到阻塞问题但存在撑爆内存的可能。
- 设置block为True且timeout为正浮点数时表示该方法会阻塞当前进程timeout秒,超时后会抛queue.Full异常。
- 设置block为false时即表示该方法不阻塞,进程会直接存数据,如果队列满会抛queue.Full异常。另外当block为false时timeout参数失效。
- put_nowait方法,参数obj为要存放的数据,功能等价于put(obj, False)即不阻塞存数据。
- empty方法:判断队列是否空,若为空返回True,若不空返回False。
- full方法:用来判断队列是否满,若已满返回True,若不满返回False。另外不定长队列永远返回False。
案例:
from multiprocessing import Queue,Process
def put(i,q):
print(f'给队列存放了{i}')
q.put(i)
def get(q):
i = q.get()
print(f'从队列取出了{i}')
if __name__ =="__main__":
q = Queue()
for i in range(5):
Process(target=put,args=(i,q)).start()
for i in range(5):
Process(target=get,args=(q,)).start()输出:
给队列存放了0
给队列存放了3
给队列存放了2
给队列存放了1
给队列存放了4
从队列取出了0
从队列取出了3
从队列取出了1
从队列取出了4
从队列取出了2代码说明:
- 多进程之间可以使用Queue传递数据;
- 通常使用阻塞方式put和get;
- put和get的顺序是先进先出;
- put和get次数一定要一致,假设put五次get六次那么第六次get会一直陷入阻塞状态直至取到数据。
- Pipe,基于管道的多进程通信方式,功能和Queue类似。前面已经对Queue详细讲述了使用方法,在这就不对Pipe展开细说了,有需要的朋友可以自己查资料。
二、基于网络,同一台机器或多台机器上的多个进程之间通信:
- 第三方工具(消息中间件)redis、rabbitmq、kafka、memcache,前面三个用的多,memcache用的少。基本上学redis和rabbitmq两种就可以了。因为这2项工具内容很多,细说的话会导致文章篇幅太大,以后有时间再单独写一篇。
生产者与消费者模型
- 使用生产者消费者模型的目的:平衡生产数据和消费数据的效率,让整体效率达到最大化。
- 生产者消费者模型常见应用场景:
爬虫:将爬取数据和处理数据分开。爬虫进程是生产者,处理进程是消费者。
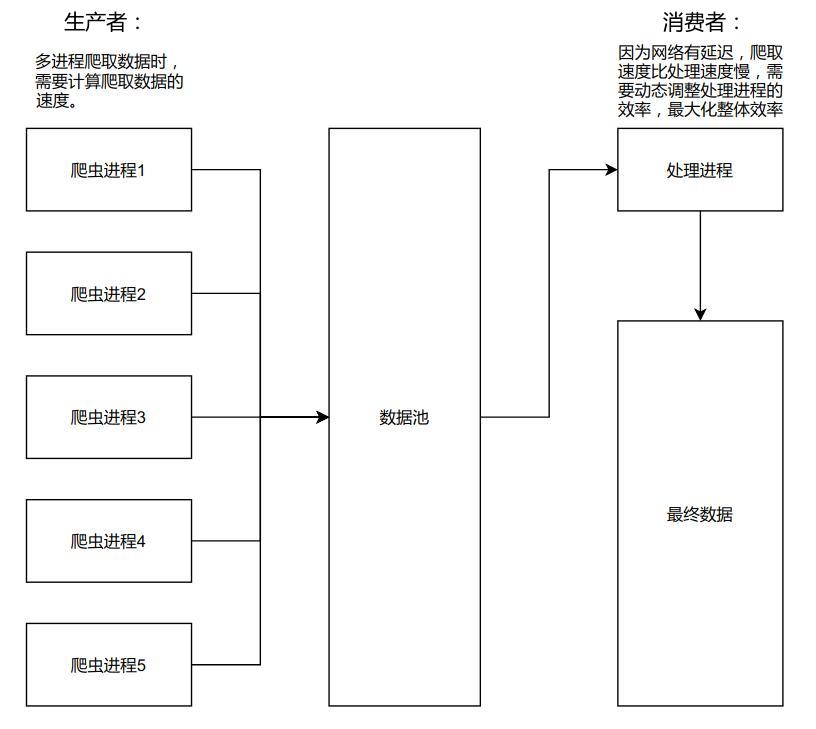
爬虫生产者消费者模型示意图
分布式操作(celery):发布任务进程:它是生产者,负责将任务拆分后放入任务池。任务处理进程:它既是消费者,从任务池中获取任务后进行处理;它又是生产者,将处理任务的结果放入处理结果反馈池。处理结果反馈进程:它是消费者,负责从处理结果反馈池获取数据后进行处理再反馈最终结果。
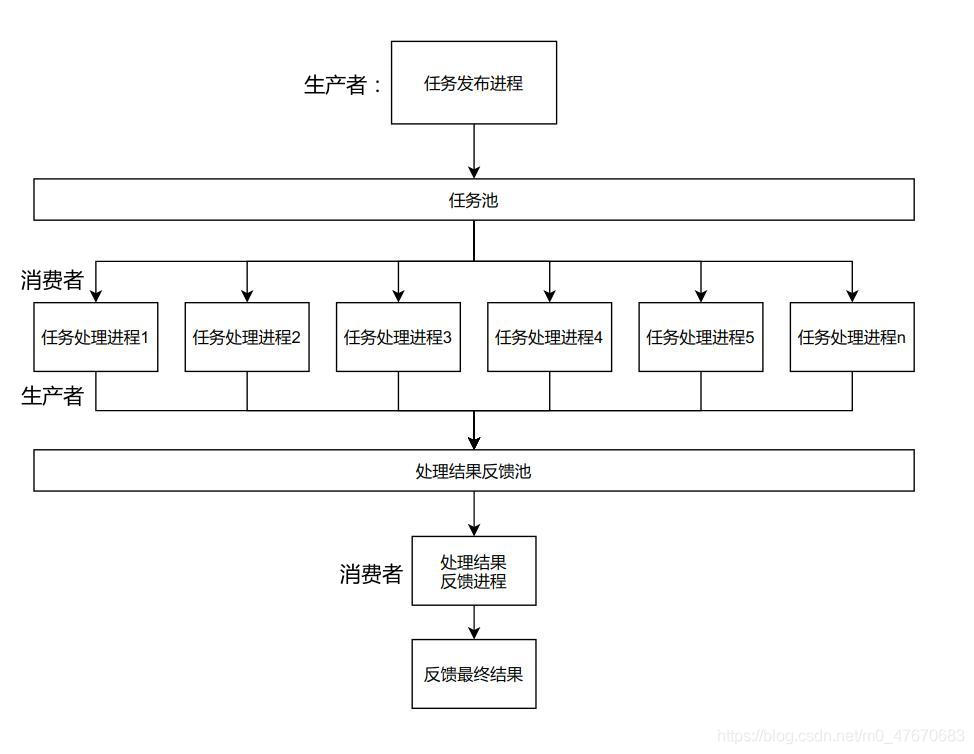
celery生产者消费者示意图
- 简单案例,代码:
from multiprocessing import Queue, Process
import requests
url = {'csdn': 'https://www.csdn.net/', 'cnblogs': 'https://www.cnblogs.com/',
'baidu': 'https://www.baidu.com/', 'toutiao': 'https://www.toutiao.com/'}
def put(key,value, q):
r = requests.get(value)
q.put((key, r.status_code))
def get(q):
while ret := q.get():
print(f'网站{ret[0]}内容已获取,状态码是{ret[1]}')
if __name__ == "__main__":
q = Queue()
p_list = []
for key,value in url.items():
p = Process(target=put, args=(key,value, q))
p.start()
p_list.append(p)
Process(target=get, args=(q,)).start()
for i in p_list:
i.join()
q.put(None)输出:
网站baidu内容已获取,状态码是200
网站cnblogs内容已获取,状态码是200
网站toutiao内容已获取,状态码是200
网站csdn内容已获取,状态码是200代码说明:
- 上述代码是个模拟爬虫的案例,给url字典每一项单独开一条进程获取网页;
- 多个生产者对应一个消费者,因为下载有延迟,下载速度慢于处理速度;
- 生产者从网站获取数据,将(网站名称,网站内容)以元组格式放入队列;
- 消费者从队列中获取数据,将其处理后输出到屏幕(实际生产时会将网页处理后保存到文件);
- 生产者和消费者进程全部开启后,join所有生产者,阻塞主进程;
- 所有生产者进程运行完毕后将None存入队列,用来通知消费者生产完毕;
- 消费者以阻塞状态循环从队列中获取数据,若获取到数据不为None时将其做相应处理,若数据为None时退出循环;
- 上述生产者消费者模型是一个异步阻塞的状态,即多个生产者多进程互不干扰地下载数据(这是异步),一个消费者以阻塞状态从队列中获取数据(这是阻塞)。
进程间数据共享
进程间数据共享可以使用Manager类,但是要注意2点:
- 修改数据时可能存在数据不安全的风险,为保证数据安全需要对修改操作加锁:
未加锁的代码:
from multiprocessing import Process,Manager
def change_dic(dic):
dic['count'] -= 1
if __name__ == "__main__":
m = Manager()
dic = m.dict()
dic['count'] = 100
p_l = []
for i in range(100):
p = Process(target=change_dic,args=(dic,))
p.start()
p_l.append(p)
for p in p_l:
p.join()
print(dic)每次运行结果都不一样:
{'count': 23}
{'count': 19}
{'count': 20}分析:当多线程修改共享数据时会发生这样的情况,当a进程修改dic['count']值前是100,此时b进程也要修改dic['count']的值,然后a将计算100-1的结果99写入dic['count'],而b进程也将100-1的结果99写入dic['count'],这就造成了应该减2而实际减1的情况。
加锁的代码:
from multiprocessing import Process,Manager,Lock
def change_dic(dic,lock):
with lock:
dic['count'] -= 1
if __name__ == "__main__":
m = Manager()
dic = m.dict()
dic['count'] = 100
p_l = []
lock = Lock()
for i in range(100):
p = Process(target=change_dic,args=(dic,lock))
p.start()
p_l.append(p)
for p in p_l:
p.join()
print(dic)运行结果:
{'count': 0}分析:加锁后多进程修改共享数据只能排队依次修改,牺牲运行速度来保证数据安全,加锁后可以保证数据安全准确。
- 修改Manager对象容器中容器的元素值时存在bug:
bug案例:
from multiprocessing import Manager, Process
def test(m):
m[0]['i'] = 2
m = Manager().list()
m.append({'i': 1})
p = Process(target=test,args=(m,))
p.start()
p.join()
print(m[0])运行结果:
{'i': 1}分析:
上述代码逻辑上无问题,但由于修改Manager对象容器中容器的元素值时存在数据不安全的情况,所以修改结果不符合预期。
应对策略:
from multiprocessing import Manager, Process
def test(m):
tmp = m[0]
tmp['i'] = 2
m[0] = tmp
m = Manager().list()
m.append({'i': 1})
p = Process(target=test,args=(m,))
p.start()
p.join()
print(m[0])运行结果:
{'i': 2}分析:
修改Manager对象容器中容器的元素值时先通过临时变量保存运算结果,再将临时变量值存回容器,这样可以保证运算结果正确。
线程
线程是操作系统中运算调度的最小单位。线程是进程的一部分,它是进程中的实际运行单位。
进程是操作系统中资源分配的最小单位。一个程序运行时最少有一个进程,一个进程至少有一个线程(即主线程)。
线程与进程的区别
- 创建进程开销大、启动慢,创建线程开销小、启动快。创建进程时操作系统要为其分配独立的内存空间和其它资源;创建线程时不需要为其分配,线程使用父进程的内存和资源。
- 同一进程的所有子线程共享内存和资源,不同进程之间内存隔离。
- 同一进程的所有子线程之间可以直接通信,不同进程之间需要借助中间代理才能实现通信。
- python程序受全局解释器锁影响多线程只能并发不能并行,多进程才可以并行。(并发即一个CPU快速轮流执行多个线程,并行即假如有4个CPU内核那么可以同时执行4个进程)
- 遇到IO多计算少时建议用多线程,遇到IO极少计算极多时建议使用多进程。(IO即输入输出,从内存取出数据或向内存存入数据即发生IO操作,例如数据从内存输出到显示屏、键盘输入字符到内存、从硬盘读取文件到内存等待)
多线程
- 处理多线程的模块
from threading import Thread- 多线程启动速度与多进程启动速度对比:
多线程的代码:
from threading import Thread
import time
def func(i):
print(f'start{i}')
time.sleep(1)
print(f'end{i}')
if __name__ == '__main__':
for i in range(5):
p = Thread(target=func, args=(i,))
p.start()
print('我启动了多线程,请注意我这一行在什么位置!')输出:
start0
start1
start2
start3
start4
我启动了多线程,请注意我这一行在什么位置!
end3
end2
end0
end1
end4多进程的代码:
from multiprocessing import Process
import time
def func(i):
print(f'start{i}')
time.sleep(1)
print(f'end{i}')
if __name__ == '__main__':
for i in range(5):
p = Process(target=func, args=(i,))
p.start()
print('我启动了多进程,请注意我这一行在什么位置!')输出:
start0
start1
start2
我启动了多进程,请注意我这一行在什么位置!
start3
start4
end0
end1
end2
end3
end4总结:
- 多线程运行时主线程打印的内容在所有子线程打印的内容后面;
- linux平台下多进程运行时主线程打印的内容在2-3条子进程打印的内容后面;在windowss平台主线程打印的内容一般在最前面。由此可见linux平台下多进程效率远超windows。
- 启动多进程开销大速度慢,启动多线程开销小速度快。
- 同一进程内部多个子线程之间数据共享,案例如下:
from threading import Thread
n = 100
def func():
global n
n -= 1
l = []
for i in range(100):
t = Thread(target=func)
t.start()
l.append(t)
for i in l:
i.join()
print(n)输出:
0- 子线程与子进程run方法、start方法、join方法、daemon属性、ident属性、is_alive函数等等使用方法和子进程的用法完全一致,在此不再赘述。以下是关于子线程与子进程不同的地方:
- 子线程不能从外部terminate(关闭),只能是子线程代码执行完毕后自我关闭。
- 子线程无exitcode属性。
- 为什么主线程会等待子线程结束之后再结束?因为主线程结束会导致主进程结束,而主进程结束后它占用的资源都会被回收。若主线程不等待子线程结束之后再结束,那么会导致子线程异常退出。
- 在线程外面查看线程id的方法是查看线程对象的ident属性;在线程内部获取id的方法是调用current_thread函数:
from threading import Thread,current_thread
import time
import os
def func(n):
print(f"{n}号线程id是{current_thread().ident}") # 线程内部查看线程id
if __name__ == '__main__':
for i in range(5):
t = Thread(target=func, args=(i,))
t.start()
print(f'线程id是:{t.ident},进程id是:{os.getpid()}') # 线程外部查看线程id输出:
0号线程id是140148462601984
线程id是:140148462601984,进程id是:22514
1号线程id是140148454209280
线程id是:140148454209280,进程id是:22514
2号线程id是140148454209280
线程id是:140148454209280,进程id是:22514
3号线程id是140148454209280
线程id是:140148454209280,进程id是:22514
4号线程id是140148454209280
线程id是:140148454209280,进程id是:22514查看所有活着的子线程:
from threading import Thread,current_thread,enumerate
import time
def func(n):
print(f"{n}号线程id是{current_thread().ident}")
time.sleep(0.5)
if __name__ == '__main__':
tread_table = []
for i in range(5):
t = Thread(target=func, args=(i,))
t.start()
tread_table.append(t)
print(len(enumerate()),enumerate())
for t in tread_table:
t.join()
print('所有线程执行完毕!')输出:
0号线程id是139804396619520
1号线程id是139804388226816
2号线程id是139804379834112
3号线程id是139804371441408
4号线程id是139804363048704
6 [<_MainThread(MainThread, started 139804408248128)>,
<Thread(Thread-1, started 139804396619520)>,
<Thread(Thread-2, started 139804388226816)>,
<Thread(Thread-3, started 139804379834112)>,
<Thread(Thread-4, started 139804371441408)>,
<Thread(Thread-5, started 139804363048704)>]
所有线程执行完毕!说明:
- threading模块里面有enumerate,它可以返回一个列表,存放了当前进程下属的所有子线程对象。
- 上述案例中为了正确查看线程数量,所以在线程内部sleep(0.5),不加这行代码会因为线程结束太快导致查看到的线程数量不符合逻辑。
- 上述案例中开了5个子线程,但enumerate中有6个子线程,因为有一条子线程是主进程的主线程。
守护线程
守护线程:守护线程随着主线程的代码结束而结束,若主线程代码结束后还有其它子线程,守护线程继续守护。
守护进程:守护进程会随着主进程的代码结束而结束,若主进程代码结束后还有其它子进程在运行,守护进程不继续守护。
为什么守护进程不守护其它子进程,而守护线程会守护其它子线程?
因为子进程各自有独立的资源,它们可以独立运行;子线程没有独立的资源,所有子线程都要依赖父进程才能运行,假如主线程结束时守护线程又不守护,那么会导致会导致其它子线程异常退出。
全局解释器锁
在CPython中,全局解释器锁(GIL)是一个互斥锁,它阻止多线程同时执行Pythond字节码。这个锁是必需的,因为CPython的垃圾回收机制造成多线程并行运行时存在数据不安全的情况。
GIL在什么时候释放?
- 当前线程执行的字节码行数达到一定阀值后切换线程时被释放。阀值通常是700条左右,但在不同版本的python和不同的操作系统下该数值不一样。
- 当前线程的时间片用尽被操作系统调度进入就绪状态,变动释放。
- 遇到IO操作时向操作系统报告当前线程进入阻塞状态,主动释放。
线程锁
讲线程锁以前先看2个例子:
全局变量数据不安全示例:
from threading import Thread
n=0
def add():
for i in range(220000):
global n
n += 1
def sub():
for i in range(220000):
global n
n -= 1
t1 = Thread(target=add)
t2 = Thread(target=sub)
t1.start()
t2.start()
t1.join()
t2.join()
print(n)运行三次会发现结果都不一致:
62830
-29108
18585说明:
- 在+=、-=、if、while等存在数据不安全的情况,当计算和赋值分离就会发生数据不安全的情况。假如有一个变量 temp = 0;a线程对temp += 1,运算过程是先获取temp的值是0、然后计算0+1、最后将1写入temp;若线程a计算完结果为1在将其写入temp时被切换到线程b执行;线程b此时获取temp的值仍然为0,它将运算结果1写入temp后,切换回线程a执行;线程a继续执行将1写入temp的操作,结果就造成temp值应该为2而实际却是1;类似这种计算操作与赋值操作因线程切换造成分离的情况就会造成数据不安全。
- 调用append、pop等内置方法时数据安全,因为调用内置方法的语句实际字节码是一条,不会发生不安全的情况。
函数式编程加锁方法:
from threading import Thread,Lock
n = 0
def add(lock):
for i in range(220000):
global n
with lock:
n += 1
def sub(lock):
for i in range(220000):
global n
with lock:
n -= 1
lock = Lock()
t1 = Thread(target=add,args=(lock,))
t2 = Thread(target=sub,args=(lock,))
t1.start()
t2.start()
t1.join()
t2.join()
print(n)运行结果:
0说明:
- 线程锁lock使用方法和进程锁的lock如出一辙,从threading模块中继承Lock类。
- 线程锁可以保证需要连续执行的代码得以连续执行。
- 线程之间修改共享数据时需要使用线程锁,加锁的位置是修改共享数据的语句,加锁后可避免修改过程中读操作和写操作因线程切换造成读写不能连贯执行的数据不安全。
类属性不安全示例:
import time
class A:
__instance = None
def __new__(cls, *args, **kwargs):
if not cls.__instance:
time.sleep(0.0001) # 模拟CPU轮转
cls.__instance = super().__new__(cls)
return cls.__instance
def func():
a = A()
print(a)
from threading import Thread
for i in range(10):
Thread(target=func).start()运行结果:
<__main__.A object at 0x7f3a68c26160>
<__main__.A object at 0x7f3a68c26160>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>
<__main__.A object at 0x7f3a68c261c0>代码说明:
- 面向对象的单例模式,我们预期得到一个实例,实际上在多线程编程时会因为CPU轮转造成创建多个不同的实例。
- 在线程a创建实例时执行if判断时,当前if判断为True,在执行后续代码时恰巧遇到CPU轮转;
- CPU轮转后线程b创建实例,在执行if判断时会发现线程a还未真正的创建实例,所以线程b会创建一个实例;
- 线程b执行完毕后轮转到线程a继续执行,此时线程a继续创建实例,这个和线程b创建的是不一样的实例;
- 最终后果是在多线程编程时单例模式创建了多个不同实例。
面向对象编程加锁方法:
import time
class A:
from threading import Lock
__instance = None
lock = Lock()
def __new__(cls, *args, **kwargs):
with cls.lock:
if not cls.__instance:
time.sleep(0.0001) # 模拟CPU轮转
cls.__instance = super().__new__(cls)
return cls.__instance
def func():
a = A()
print(a)
from threading import Thread
for i in range(10):
Thread(target=func).start()运行结果:
对某多线程共享使用的数据<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>
<__main__.A object at 0x7f4fe8527340>说明:
- 注意看上面的关于面向对象编程时加锁的示范;
- 在类中from threading import Lock导入锁,然后定义类属性lock = Lock();
- 使用with cls.lock的方式对创建单例实例的if判断及if内部代码块一起加锁;
- 加锁后可以实现多线程安全的单例模式。
总结:
- 当某线程正在使用的全局变量被其它线程修改,就可能会发生数据不安全。
- 数据不安全的根源在于全局变量的值与后续操作不匹配。当某线程获取全局变量的当前值后准备执行后续操作前,该全局变量被其它线程改动,使得后续操作与全局变量的最新值不匹配。
- 常见的全局变量有以下几种:
声明global的变量。
类属性:类属性是类的所有实例共享使用的,它是全局变量。
容器(list、set、dict):使用容器作参数时要注意它是全局变量,对容器参数修改元素、pop元素、insert元素、删除元素都有数据不安全的风险。使用容器的copy作参数可避免数据不安全的风险,另外若容器中嵌套容器时要使用deepcopy。
- 使用元组(tuple)作参数是安全的,但元组(tuple)中嵌套容器(list、set、dict)时仍然存在数据不安全的风险。
- 使用线程锁可以让线程对全局变量的取值与后续操作不被打扰,当该线程使用全局变量时其它线程访问这个全局变量会陷入阻塞态,该线程释放线程锁后其它线程才能恢复就绪态,另外如果该线程一直不释放线程锁会造成其它线程永远陷入阻塞态。
死锁
- 什么是死锁?是指多个进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象。
- 死锁是怎么产生的?
当存在多把(互斥/递归)锁并且在多个线程中交叉使用就有可能造成死锁。例如:a线程需要两把钥匙(先拿钥匙a后拿钥匙b),b线程也需要两把钥匙(先拿钥匙b后拿钥匙a);如果发生a线程拿到钥匙a在等钥匙b,而b线程拿到钥匙b在等待钥匙a,此时就会陷入死锁。
案例:
from threading import Thread,Lock
import time
def blue(name,lock1,lock2):
with lock1,lock2: # 拿钥匙的顺序是先lock1后lock2
time.sleep(0.1) # 模拟网络延迟
print(f'蓝队的“{name}”获得了2把钥匙,完成任务了')
def red(name,lock1,lock2):
with lock2,lock1: # 拿钥匙的顺序是先lock2后lock1
print(f'红队的“{name}”获得了2把钥匙,完成任务了')
lock1 = Lock()
lock2 = Lock()
for i in range(5):
t1 = Thread(target=blue,args=(i,lock1,lock2))
t2 = Thread(target=red,args=(i,lock1,lock2))
t1.start()
t2.start()运行结果每次都不一样,但是都会发生死锁,不能顺利完成全部任务:
蓝队的“0”获得了2把钥匙,完成任务了
红队的“0”获得了2把钥匙,完成任务了
红队的“1”获得了2把钥匙,完成任务了
红队的“2”获得了2把钥匙,完成任务了
蓝队的“3”获得了2把钥匙,完成任务了- 怎么解决死锁?
解决方法有两种:
一是所有的线程拿钥匙和放钥匙的顺序一致。例如:a线程需要2把钥匙(先拿钥匙a后拿钥匙b),b线程也需要两把钥匙(先拿钥匙a后拿钥匙b),即所有线程获取钥匙的顺序都一致,此时就可以避免陷入死锁。
案例:
from threading import Thread,Lock
import time
def blue(name,lock1,lock2):
with lock1,lock2: # 所有线程拿钥匙的顺序都是先lock1后lock2
time.sleep(0.1) # 模拟网络延迟
print(f'蓝队的“{name}”获得了2把钥匙,完成任务了')
def red(name,lock1,lock2): # 所有线程拿拿钥匙的顺序都是先lock1后lock2
with lock1,lock2:
print(f'红队的“{name}”获得了2把钥匙,完成任务了')
lock1 = Lock()
lock2 = Lock()
for i in range(5):
t1 = Thread(target=blue,args=(i,lock1,lock2))
t2 = Thread(target=red,args=(i,lock1,lock2))
t1.start()
t2.start()运行结果每次都一样,不会发生死锁,都能顺利完成任务:
蓝队的“0”获得了2把钥匙,完成任务了
红队的“0”获得了2把钥匙,完成任务了
蓝队的“1”获得了2把钥匙,完成任务了
红队的“1”获得了2把钥匙,完成任务了
蓝队的“2”获得了2把钥匙,完成任务了
红队的“2”获得了2把钥匙,完成任务了
蓝队的“3”获得了2把钥匙,完成任务了
红队的“3”获得了2把钥匙,完成任务了
蓝队的“4”获得了2把钥匙,完成任务了
红队的“4”获得了2把钥匙,完成任务了二是所有线程都使用一把递归锁。
from threading import Thread,RLock
import time
def blue(name,lock1,lock2):
with lock1,lock2: # 蓝队拿钥匙的顺序是先lock1后lock2
time.sleep(0.1) # 模拟网络延迟
print(f'蓝队的“{name}”获得了2把钥匙,完成任务了')
def red(name,lock2,lock1):
with lock1,lock2: # 红队拿钥匙的顺序是先lock2后lock1
print(f'红队的“{name}”获得了2把钥匙,完成任务了')
lock1 = lock2 = RLock() # 所有的锁都是一把递归锁
for i in range(5):
t1 = Thread(target=blue,args=(i,lock1,lock2))
t2 = Thread(target=red,args=(i,lock1,lock2))
t1.start()
t2.start()运行结果每次都一样,不会发生死锁,都能顺利完成任务:
蓝队的“0”获得了2把钥匙,完成任务了
红队的“0”获得了2把钥匙,完成任务了
蓝队的“1”获得了2把钥匙,完成任务了
红队的“1”获得了2把钥匙,完成任务了
蓝队的“2”获得了2把钥匙,完成任务了
红队的“2”获得了2把钥匙,完成任务了
蓝队的“3”获得了2把钥匙,完成任务了
红队的“3”获得了2把钥匙,完成任务了
蓝队的“4”获得了2把钥匙,完成任务了
红队的“4”获得了2把钥匙,完成任务了递归锁
递归锁的使用方法在前面的案例中已有说明,但是要注意不同的递归锁交叉使用还是会造成死锁。
递归锁(Rlock)的效率不如互斥锁(Lock)高。遇到死锁问题优先考虑使用顺序一致的互斥锁解决,其次才考虑使用一把递归锁解决。