目标检测之Fast R-CNN
禁止任何形式的转载!
1.前言
《Fast R-CNN》
论文地址:https://arxiv.org/abs/1504.08083.
于2015年4月份发表于ICCV上,弥补了R-CNN和SPPnet的缺点,在速度和精度上都有所提升。
1)比R-CNN, SPPnet检测效果更好
2)利用多任务损失函数,使得训练只需要一步完成,不再分多个阶段训练
3)训练时可以对所有网络层进行更新
4)无需在硬件内存上专门存储特征
2.Fast R-CNN的结构
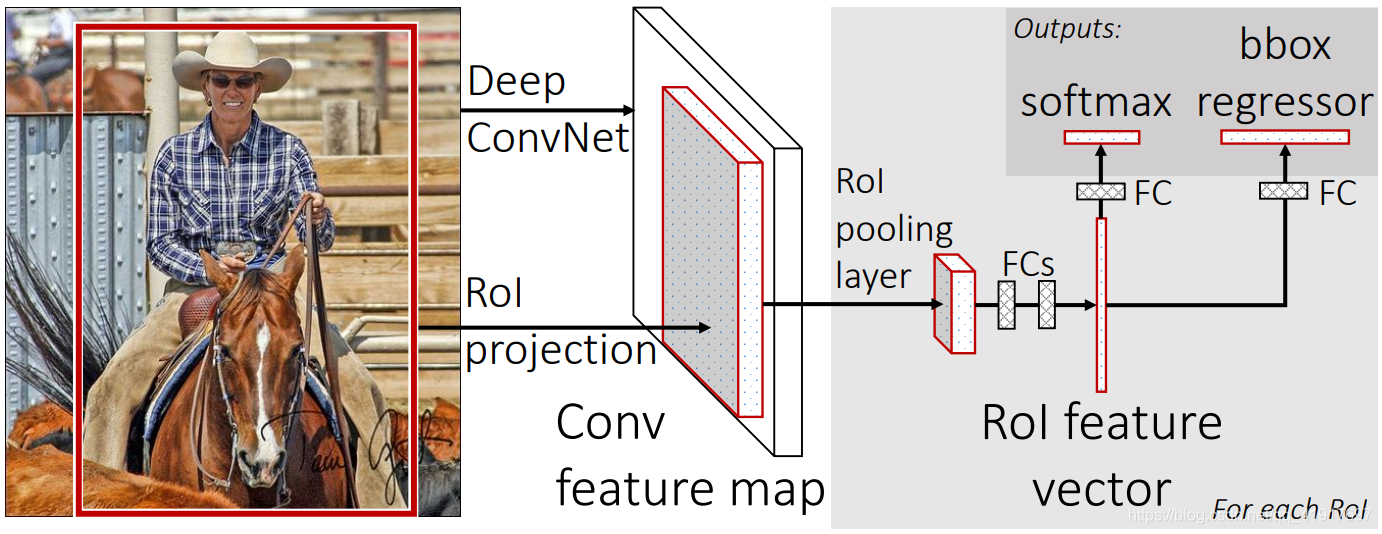
- 整个224x224图片送入CNN网络,这里使用的是VGG,conv5层得到特征图 conv feature map,注意这里一张图只需要运行一次CNN即可,速度大大加快。
- 对图像进行候选框提取(selective search)得到2000个候选区域的坐标信息。将这些区域坐标映射到conv feature map上截取出相应的feature map(图中大的灰色方块),然后进行RoI pooling,将各种形状的feature map固定到统一的大小(图中小的灰色方块) a fixed-length feature vector。
- 将feature vector喂入到一系列FC层中(VGG是两个4096维的fc),最后经两个FC支路连接到两个输出层。分类层通过softmax输出K+1(背景)个类别的概率,回归层输出4*K个坐标信息。
2.1 RoI pooling
RoI pooling是对每个小格采用的max pooling,max pooling就是常规的分别在每个通道进行。RoI pooling到固定空间大小HxW可以作为一个超参数。定位的坐标 (r, c, h, w) ,(r, c) 代表左上顶点, (h, w)代表框的长宽。这里为VGG选用的是7x7的RoI pooling。
2.2 预训练CNN网络

使用更多的数据集预训练网络效果会更好。
2.3 微调目标检测网络
使用的 mini-batch SGD,但是每张图片都会有很多RoI区域,只有把batchsize减少。这里是每次取batchsize=2,R=128(即每张图片取64个RoI)。这个策略的一个令人担心的问题是它可能导致训练收敛变慢,因为来自相同图像的RoI是相关的。事实证明,N=2和R=128时效果很好,没有出现收敛变慢的情况。
既然要选择选择样本,就需要对正负样本进行定义,从候选框中获取25%的RoI且IoU至少为0.5作为正样本,75%负样本选择IoU在区间 [ 0.1 , 0.5 ) \lbrack 0.1, 0.5) [0.1,0.5)上的,即正负样本比例为1:3,防止负样本过多。在训练期间,图像以p=0.5水平翻转,不使用其他数据增强。
Multi-task loss多任务损失函数。一个函数就包含了分类和定位的优化目标。如下列公式所示,其中[u ≥ 1]代表正样本为1,负样本为0,即负样本不计算定位损失。
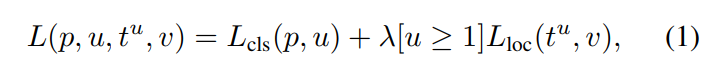
分类损失使用的是log loss对数损失: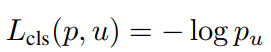
定位损失的定义:
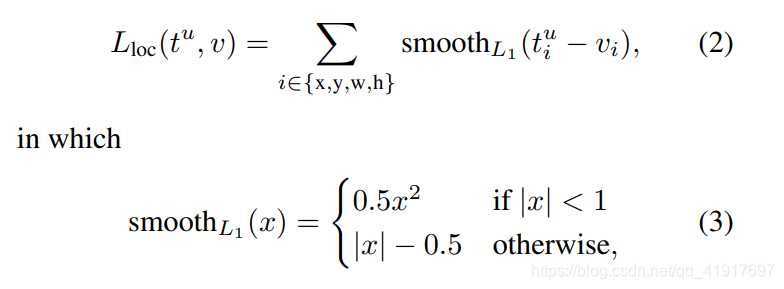
为什么采用smooth L1损失函数?
L1 loss相比于L2 loss对于异常点更加不敏感,边框回归采用L2损失的话需要更仔细的微调学习率来防止梯度爆炸。R-CNN就是采用的L2 loss。
smooth L1是L1光滑之后的,L1损失的缺点就是有折点,不光滑,导致不稳定。
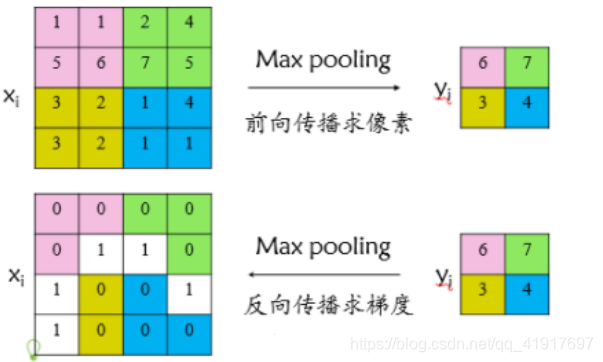
RoI pooling层的反向传播:
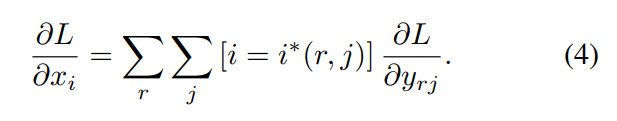
其实就是类比于maxpooling反向传播,只不过在RoI出现重叠的区域需要累加起来。
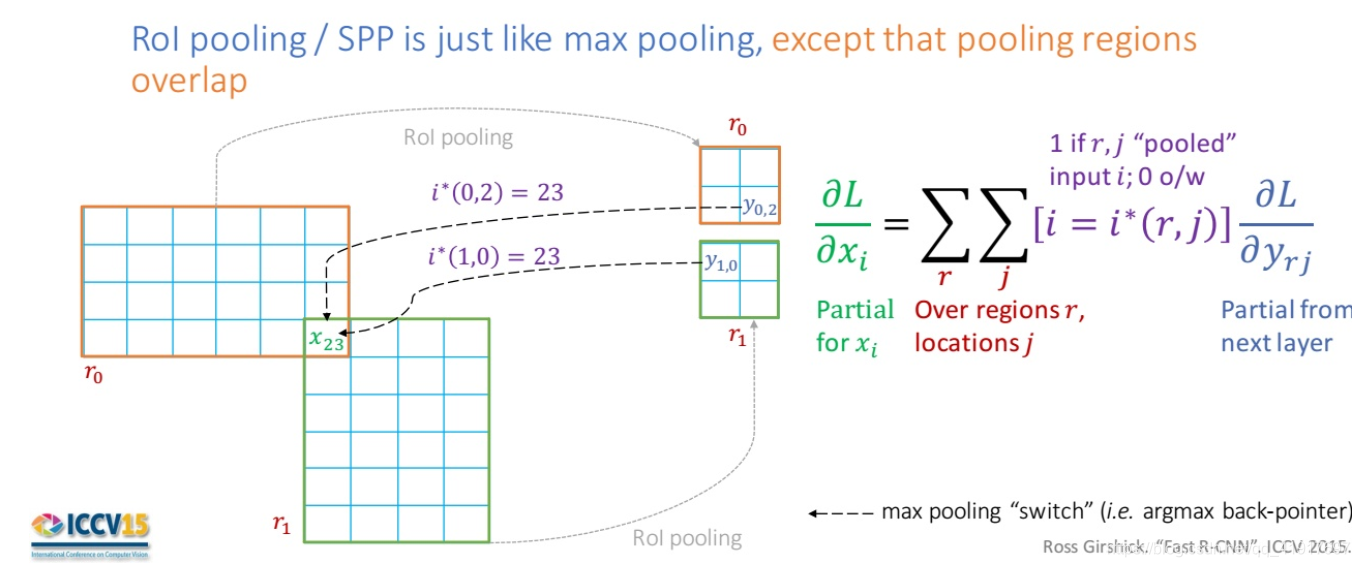
从哪里开始微调整个网络: 作者冻结不同的层,经过对比,对于VGG作为的主干网络,从conv3_1往后开始微调(这里主要考虑到效率,从conv2开始微调只能提升0.3,但时间却增长3倍),小一些的网络从conv2往后开始微调。

2.4 尺度变换 single scale or multi-scale
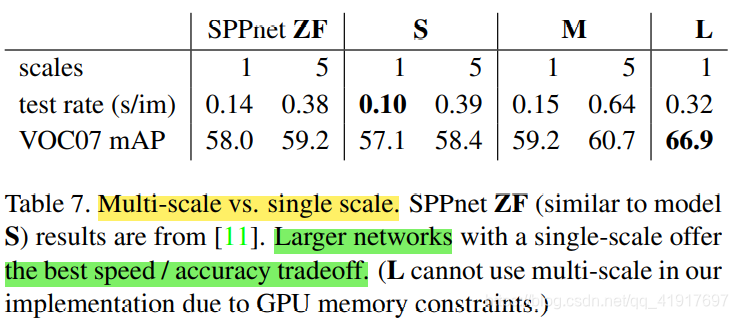
文中将多尺度与单一尺度进行了对比实验: single-scale detection performs almost as well as multi-scale detection。多尺度能提升性能,但是不如使用更大一点的网络得到的提升大,而且预测速度也更慢。综合精度和速度,推荐选用单一尺度的大网络。这里L=VGGNet。
至此,整个前向传播和反向传播的过程都已展示完。
3.SVD分解的作用
对于图像分类的处理过程, 时间消耗主要在卷积层,全连接层时间花费会很少,但是对于目标检测算法,由于需要处理大量的RoI,因此需要花费一般以上的时间在全连接层上。
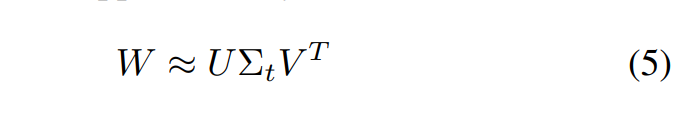
作者采用SVD来简化全连接层计算。原本计算公式为y=Wx,将W进行SVD分解,并用前t个特征值近似代替,y=Wx=U⋅(∑⋅VT)⋅x:
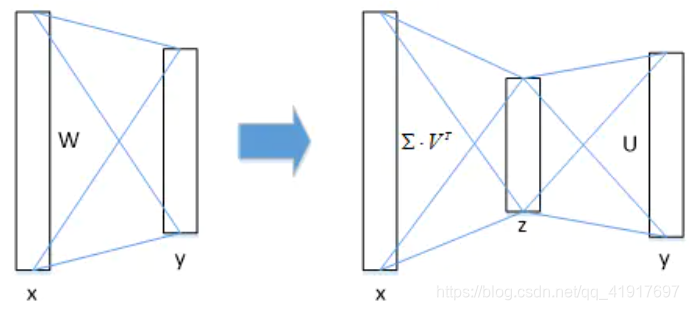
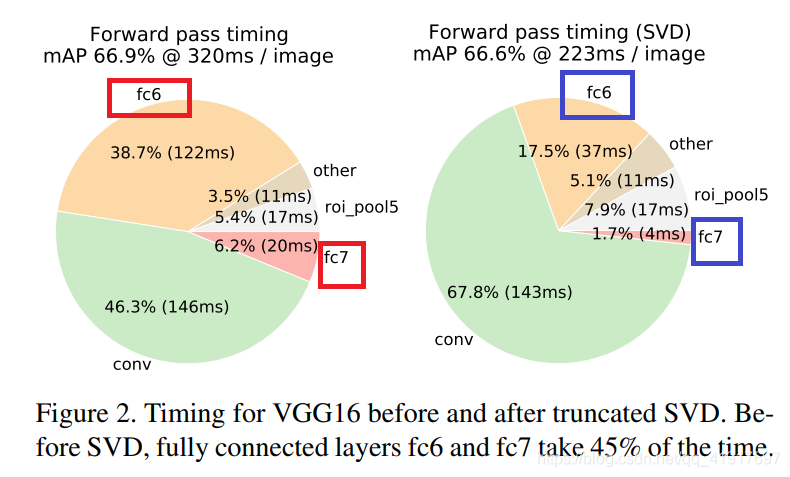
相当于把一个全连接层拆分为两个全连接层,第一个全连接层不含偏置,第二个全连接层含偏置;实验表明,SVD分解全连接层能使mAP只下降0.3%的情况下提升30%的速度,同时该方法也不必再执行额外的微调操作。可以看见fc层的计算占比大大减少。
上一篇:目标检测之RCNN.