1. 特征工程分类
- 提取:从“原始”数据中提取特征
- 特别是对文章数据(自然语言处理)、从图像中抽取特征(用到深度学习技术)
- 转换:缩放,转换或修改特征
- 性别(男,女,其他)====>sex(0,1,-1)
- 选择:从更大的特征集中选择特征子集
- featuresA+featuresB
- df.select(“featuresB”)
- df.select($“featuresB”)
- df.select(col(“featuresB”))
- df.select($"featuresB,col(“featuresB”))
- 卡方验证
2. 特征提取(了解)
2.1 TF-IDF
-
TF-IDF: 词频-逆向文件频率 文本挖掘中广泛使用的特征向量化方法
- TF就是在描绘词的频率,如果一个文章中出现最多的词,一般情况下是重要的词汇

- TF就是在描绘词的频率,如果一个文章中出现最多的词,一般情况下是重要的词汇
-
但是对于语气词,如is am are等需要过滤(因为文本中含有大量的语气词),分母加一表示加了一个平滑项
对数函数图像:
提取文章或词语中最重要的词代码演示:
import org.apache.spark.SparkContext
import org.apache.spark.ml.feature.{
HashingTF, IDF, IDFModel, Tokenizer}
import org.apache.spark.sql.{
DataFrame, SparkSession}
/**
* DESC: TFIDF的使用---目的:提取文章或词语中最重要的词
* Complete data processing and modeling process steps:
* 开发步骤:
* 1-准备环境
* 2-准备数据
* 3-解析数据
* 4-对文章或词语进行分词
* 5-使用TF构建词频的模型
* 6-使用IDF构建逆文档频率模型
* 7-形成最后的结果打印
*/
object TFIDFTest {
def main(args: Array[String]): Unit = {
// * 1-准备环境
val spark: SparkSession = SparkSession.builder().appName("TFIDFTest").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
// * 2-准备数据----jieba分词
val data: DataFrame = spark.createDataFrame(Seq((0, "Hi I heard about Spark"),
(0, "I wish Java could use case classes"),
(1, "Logistic regression models are neat"))).toDF("label", "words")
// * 3-解析数据
data.printSchema()
//label+words
// * 4-对文章或词语进行分词
// token(inout=?? putput=????,)
//setInputCol表示的是输入数据的列名,来源于上面处理完的数据,如data中的words
//setOutputCol是表示用户可以自定义指定输出的列名,如“token_Words”
//Tokenizer是以默认的空格作为分隔符的
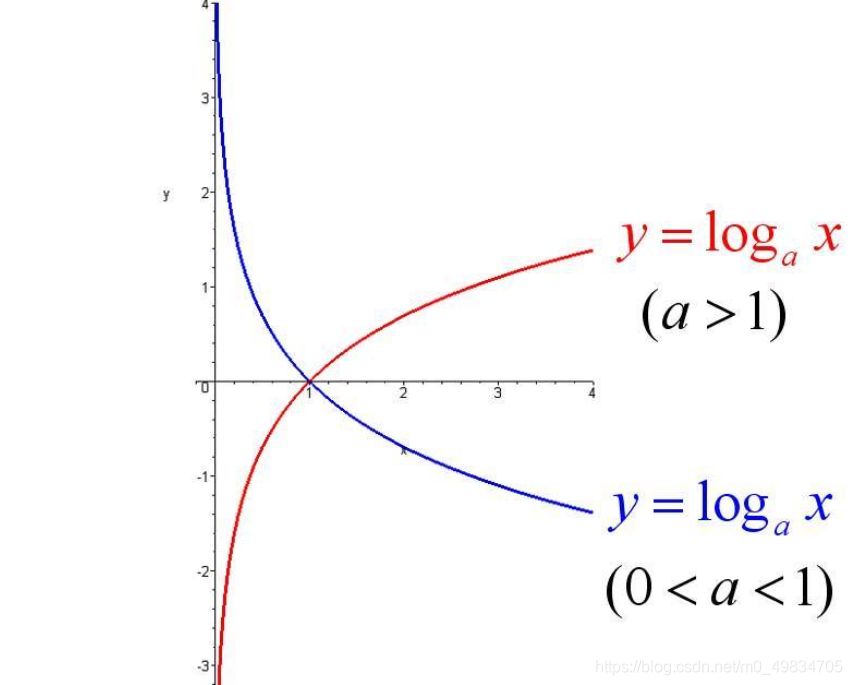
val token: Tokenizer = new Tokenizer().setInputCol("words").setOutputCol("token_Words")
val tokenResult: DataFrame = token.transform(data)
tokenResult.show(truncate = false)
tokenResult.printSchema()
// +-----+--------------------+--------------------+
// |label| words| token_Words|
// +-----+--------------------+--------------------+
// | 0|Hi I heard about ...|[hi, i, heard, ab...|
// | 0|I wish Java could...|[i, wish, java, c...|
// | 1|Logistic regressi...|[logistic, regres...|
// +-----+--------------------+--------------------+
// * 5-使用TF构建词频的模型
//setInputCol---指定输入的参数---一定来源于上面分词之后的结果
//setOutputCol用户自己指定的参数
val hashTF: HashingTF = new HashingTF().setInputCol("token_Words").setOutputCol("hashingTokenWords")
val hashResult: DataFrame = hashTF.transform(tokenResult)
hashResult.printSchema()
hashResult.show(false)
// (262144 id,[24417第1个桶id,49304第2个桶id,73197第3个桶id,91137第4个桶id,234657第5个桶id],[1.0,1.0,1.0,1.0,1.0])
// * 6-使用IDF构建逆文档频率模型
//setInputCol---指定输入的参数---一定来源于上面分词之后的结果
//setOutputCol用户自己指定的参数
val idf: IDF = new IDF().setInputCol("hashingTokenWords").setOutputCol("idfWords")
//为什么idf需要先进行fit在进行tranform呢?
//答案:因为idf操作需要先形成模型model,在利用model对其他数据进行转换
val idfModel: IDFModel = idf.fit(hashResult)
val result: DataFrame = idfModel.transform(hashResult)
// * 7-形成最后的结果打印
result.show(false)
//0.28768207245178085,0.6931471805599453,0.6931471805599453,0.6931471805599453,0.6931471805599453
}
}
总结:
- new 操作() 特征工程
- tranform 数据转换
- fit------model---------transform转换
- 问题:有些的操作需要直接进行transform,有些操作先进行fit再进行transform
extends Estimator 继承该类需要进行fit
extends Transformer 继承该类的直接进行tranform
2.2 CountVector
简介: CountVectorizer并CountVectorizerModel旨在帮助将一组文本文档转换为标签计数的向量

代码:
println("countVector:")
val re: CountVectorizer = new CountVectorizer().setInputCol("token_Words").setOutputCol("frquency_words")
val countModel: CountVectorizerModel = re.fit(tokenResult)
countModel.transform(tokenResult).show(false)
总结:
- TFIDF
- 含义:计算词频*逆文档频率(注意,在sparkmllib中使用的是hashingtf)
- 目的:计算出一个文章中出现的重要的词
- 能用在哪些地方:
- 提取文章的关键词汇
- CountVector
- 含义:计算单词出现的次数
- 目的:找出出现次数较多的单词或词语
- 用途:在文章中找出出现次数最多的词